StackLLaMA:一个实践指南,用于使用RLHF训练LLaMA
StackLLaMA:一个RLHF训练LLaMA的实践指南
ChatGPT、GPT-4和Claude等模型是强大的语言模型,它们经过了一种称为人类反馈强化学习(RLHF)的方法进行了微调,以更好地与我们期望的行为相一致,并且能够更好地使用它们。
在这篇博文中,我们展示了使用RLHF训练LlaMa模型在Stack Exchange上回答问题的所有步骤,通过以下组合实现:
- 监督微调(SFT)
- 奖励/偏好建模(RM)
- 人类反馈强化学习(RLHF)
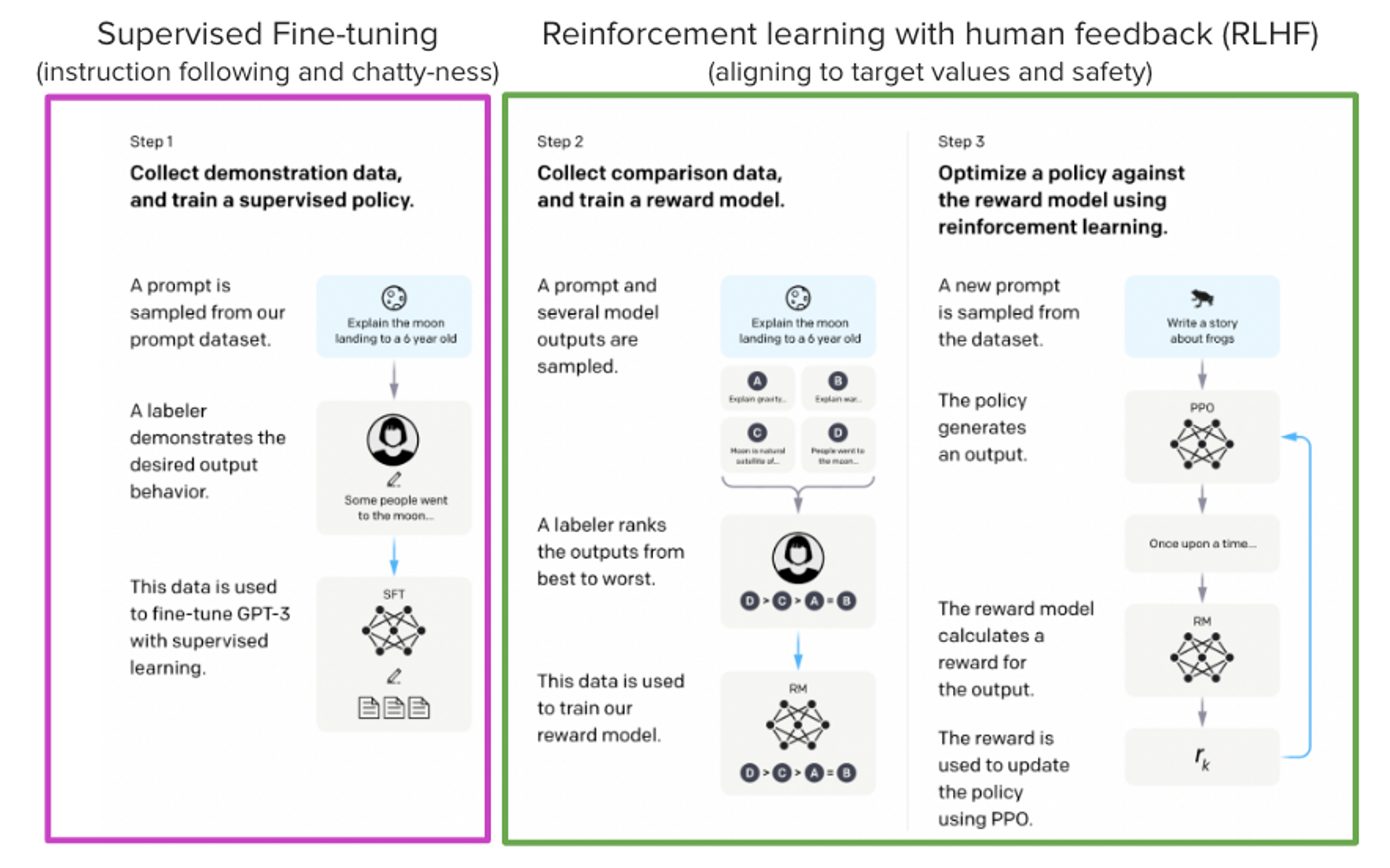 来自InstructGPT论文:Ouyang, Long等人。”使用人类反馈训练语言模型遵循指令。” arXiv预印本arXiv:2203.02155(2022)。
来自InstructGPT论文:Ouyang, Long等人。”使用人类反馈训练语言模型遵循指令。” arXiv预印本arXiv:2203.02155(2022)。
通过结合这些方法,我们发布了StackLLaMA模型。该模型可在🤗 Hub上使用(请参阅原始LLaMA模型的Meta的LLaMA发布),整个训练流程作为Hugging Face TRL库的一部分提供。为了让您了解模型的功能,可以在下面尝试演示!
LLaMA模型
在进行RLHF时,选择一个能力强的模型非常重要:RLHF步骤只是微调步骤,以使模型与我们希望与之交互和期望其响应的方式相一致。因此,我们选择使用最近引入且性能优良的LLaMA模型。LLaMA模型是Meta AI开发的最新大型语言模型,参数范围从7B到65B,训练数据量在1T到1.4T标记之间,非常能胜任。我们将7B模型作为所有后续步骤的基础!要访问模型,请使用Meta AI的表单。
Stack Exchange数据集
收集人类反馈是一项复杂且昂贵的工作。为了在构建一个有用的模型的同时启动此示例的过程,我们利用了StackExchange数据集。该数据集包括来自StackExchange平台(包括用于代码和许多其他主题的StackOverflow)的问题及其相应的答案。这个数据集在这种情况下很有吸引力,因为答案附带了点赞数和被接受答案的标签。
我们遵循Askell等人2021年的方法,并为每个答案分配一个分数:
score = log2(1 + upvotes)四舍五入到最近的整数,如果提问者接受了答案,则再加1(如果点赞数为负数,则分配分数为-1)。
对于奖励模型,我们始终需要每个问题比较两个答案,后面我们会看到。有些问题有几十个答案,导致可能有许多可能的配对。我们每个问题最多随机采样十对答案,以限制每个问题的数据点数量。最后,我们将HTML转换为Markdown,以使模型的输出更易读。您可以在这里找到数据集以及处理笔记本。
高效的训练策略
即使训练最小的LLaMA模型也需要大量的内存。一些快速计算:在bf16中,每个参数使用2个字节(在fp32中为4个字节),另外还有8个字节,例如Adam优化器使用的字节(有关更多信息,请参阅Transformers中的性能文档)。因此,一个7B参数的模型将使用(2+8)*7B=70GB的内存,并且在计算注意力分数等中间值时可能需要更多内存。因此,您甚至无法在单个80GB A100上训练模型。您可以使用一些技巧,例如更高效的优化器和半精度训练,以在内存中挤压更多数据,但迟早会耗尽。
另一种选择是使用Parameter-Efficient Fine-Tuning(PEFT)技术,例如peft库,可以在加载为8位的模型上执行低秩适应(LoRA)。
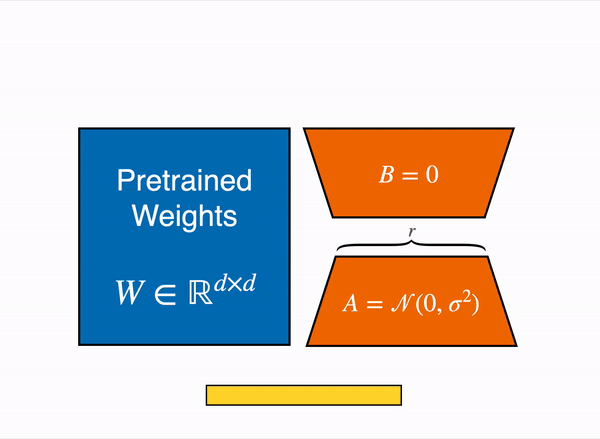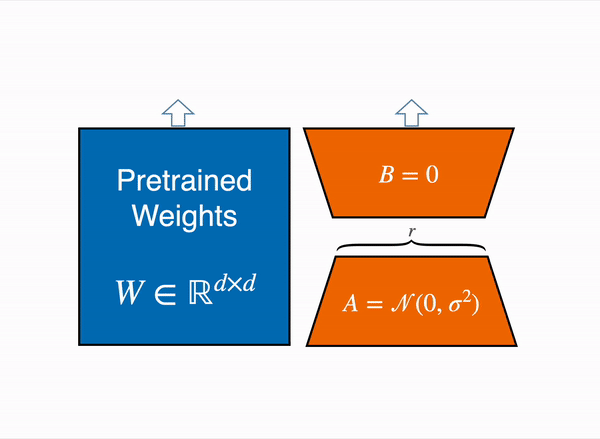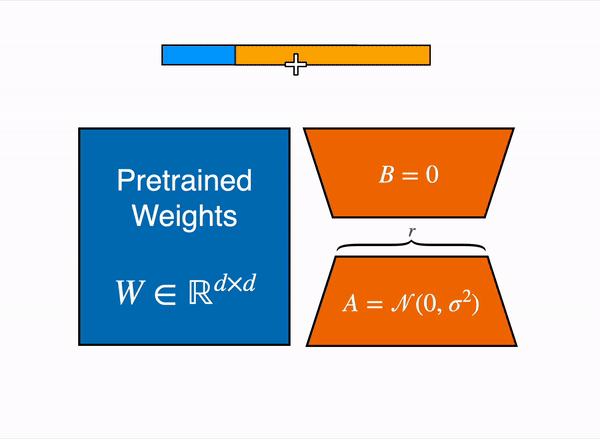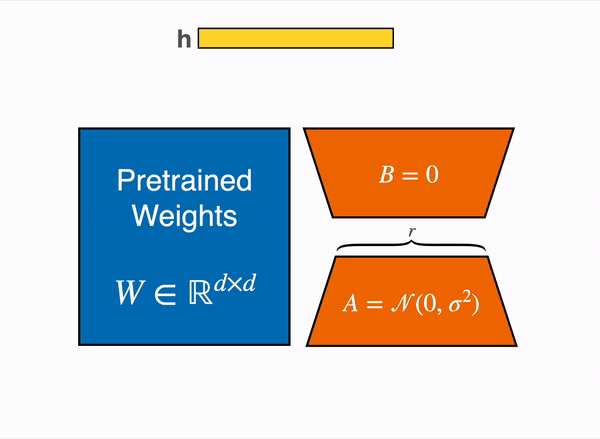 线性层的低秩适应:在冻结层(蓝色)旁边添加额外参数(橙色),并将结果编码的隐藏状态与冻结层的隐藏状态相加。
线性层的低秩适应:在冻结层(蓝色)旁边添加额外参数(橙色),并将结果编码的隐藏状态与冻结层的隐藏状态相加。
以8位加载模型可大幅减少内存占用,因为权重仅需要一个字节的空间(例如,7B LlaMa在内存中占用7GB)。LoRA在某些特定层(通常是注意力层)之上添加小的适配器层,而不是直接训练原始权重,从而大幅减少可训练参数的数量。
在这种情况下,一个经验法则是为每十亿个参数分配约1.2-1.4GB的内存(取决于批量大小和序列长度),以适应整个微调设置。如上文所述,这使得能够以较低成本对更大的模型进行微调(在NVIDIA A100 80GB上可达到50-60B规模的模型)。
这些技术使得在消费设备和Google Colab上可以对大型模型进行微调。值得注意的示例是在Google Colab上对facebook/opt-6.7b(float16下的13GB)和openai/whisper-large(15GB GPU RAM)进行微调。有关使用peft的更多信息,请参考我们的GitHub存储库或之前的博客文章(https://huggingface.co/blog/trl-peft),该博客文章介绍了在消费级硬件上训练200亿参数模型的方法。
现在我们可以将非常大的模型适配到单个GPU中,但训练可能仍然非常缓慢。在这种情况下,最简单的策略是数据并行:我们将相同的训练设置复制到不同的GPU中,并将不同的批次传递给每个GPU。通过这种方式,您可以并行化模型的前向/后向传递,并与GPU数量进行扩展。
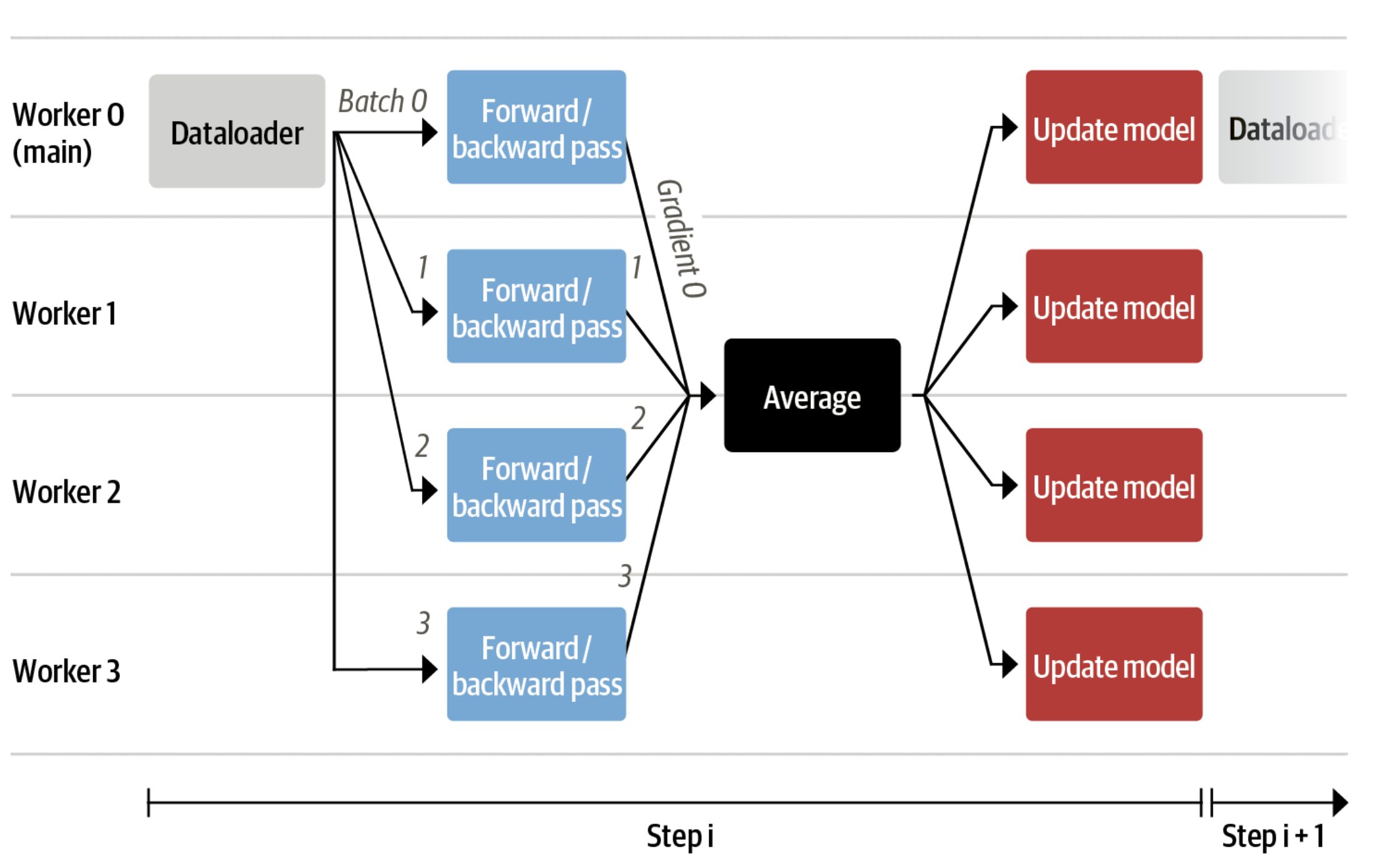
我们可以使用transformers.Trainer或accelerate来支持数据并行,而无需进行任何代码更改,只需在使用torchrun或accelerate launch调用脚本时传递参数即可。以下分别在单台机器上使用accelerate和torchrun以8个GPU运行一个训练脚本。
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py监督微调
在训练奖励模型并使用RL调优模型之前,如果模型在我们感兴趣的领域已经表现良好将会很有帮助。在我们的情况下,我们希望它能回答问题,而对于其他用例,我们可能希望它能遵循指示,这时进行指示调优是个好主意。实现这一目标的最简单方法是继续以语言建模目标对来自该领域或任务的文本进行语言模型的训练。StackExchange数据集非常庞大(超过1000万个指令),因此我们可以轻松地在其子集上训练语言模型。
在进行RLHF之前,对模型进行微调没有什么特别之处-我们只是应用了预训练的因果语言建模目标。为了有效使用数据,我们使用了一种称为packing的技术:不是每个样本在批次中有一个文本,然后填充到最长文本或模型的最大上下文,而是将很多文本连接起来,中间用EOS标记,并切割上下文大小的块来填充批次,而无需进行任何填充。
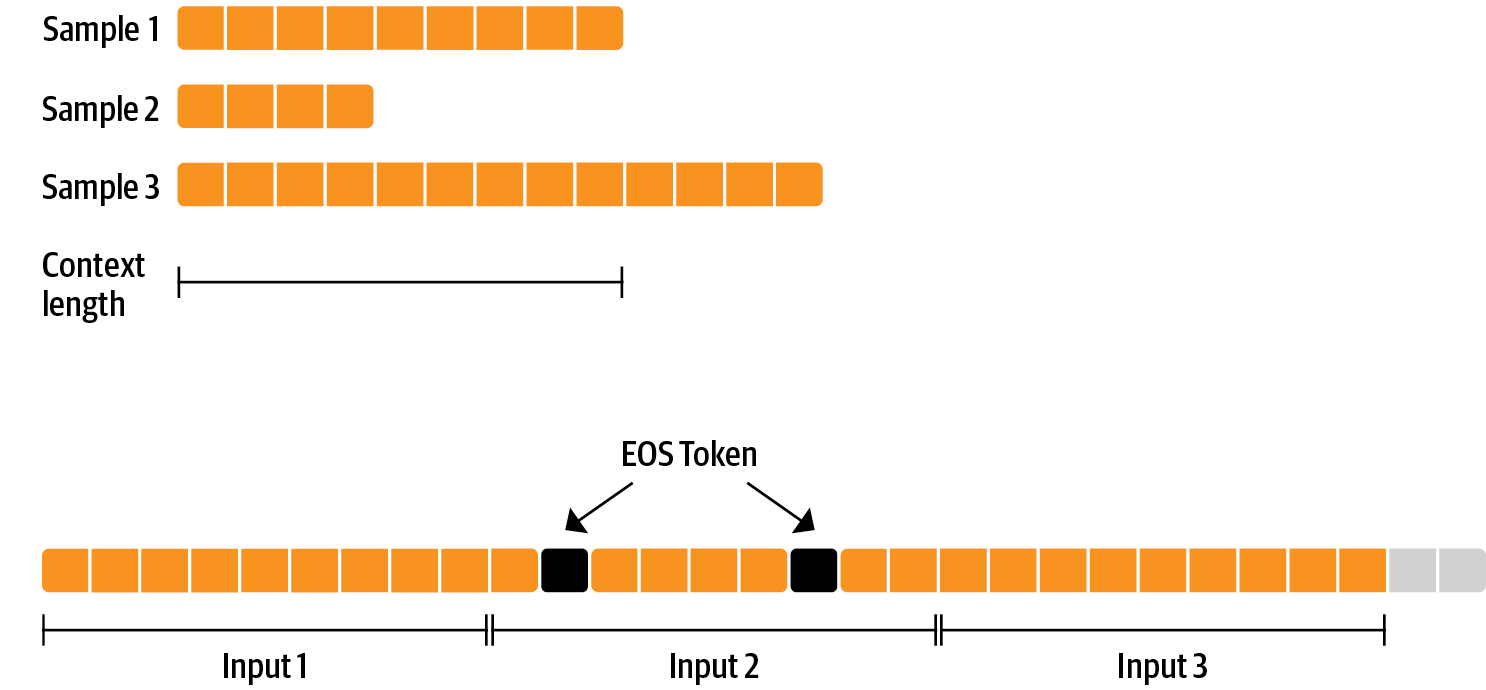
采用这种方法,训练更加高效,因为通过模型传递的每个标记都会得到训练,而不是通常从损失中屏蔽填充标记。如果您没有太多数据,并且更关注偶尔截断一些溢出上下文的标记,您还可以使用传统的数据加载器。
packing由ConstantLengthDataset处理,然后我们可以在使用peft加载模型后使用Trainer。首先,我们以8位加载模型,准备进行训练,然后添加LoRA适配器。
# 以8位加载模型
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_int8_training(model)
# 添加LoRA到模型
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)我们使用因果语言建模目标对模型进行几千个步骤的训练,并保存模型。由于我们将再次使用不同的目标对模型进行调优,因此我们将适配器权重与原始模型权重合并。
免责声明:由于LLaMA的许可证,我们仅发布适配器权重和下面章节中的模型检查点。您可以通过填写Meta AI的表单申请获得基础模型的权重,然后通过运行这个脚本将它们转换为🤗 Transformers格式。请注意,在v4.28发布之前,您还需要从源代码安装🤗 Transformers。
现在,我们已经对任务进行了微调,准备训练奖励模型。
奖励建模与人类偏好
原则上,我们可以直接使用人类注释来对模型进行RLHF微调。然而,这将需要我们在每次优化迭代后将一些样本发送给人类进行评分。由于需要收敛的训练样本数量以及人类阅读和注释速度的固有延迟,这种方法既昂贵又缓慢。
一种替代直接反馈的方法是在RL循环之前使用人类注释来训练奖励模型。奖励模型的目标是模拟人类如何对文本进行评分。构建奖励模型有几种可能的策略:最直接的方法是预测注释(例如评分分数或“好”/“坏”二进制值)。实际上,更有效的方法是预测两个示例的排名,其中奖励模型呈现给定提示 x x x 的两个候选项 ( y k , y j ) (y_k, y_j) ( y k , y j ) ,并且必须预测出哪一个候选项会被人类注释者评分更高。
这可以转化为以下损失函数:
loss ( θ ) = − E ( x , y j , y k ) ∼ D [ log ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ]
其中 r r r 是模型的得分, y j y_j y j 是首选候选项。
通过StackExchange数据集,我们可以根据得分推断出用户更喜欢哪个答案中的两个。有了这些信息和上面定义的损失,我们可以通过添加自定义损失函数来修改transformers.Trainer。
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss我们使用了100,000个候选对的子集,并在一个保留集上进行了评估,该保留集包含了50,000个样本。使用批量大小为4进行训练,我们使用LoRA peft适配器在Adam优化器下使用BF16精度对LLaMA模型进行了一次 epoch 的训练。我们的LoRA配置如下:
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)训练日志记录在Weights & Biases中,使用🤗研究集群的8个A100 GPU花费了几个小时,模型最终达到了67%的准确率。虽然听起来得分较低,但即使对于人类注释者来说,这个任务也非常困难。
如下一节详细介绍的那样,生成的适配器可以合并到冻结的模型中,并保存以供进一步的下游使用。
来自人类反馈的强化学习
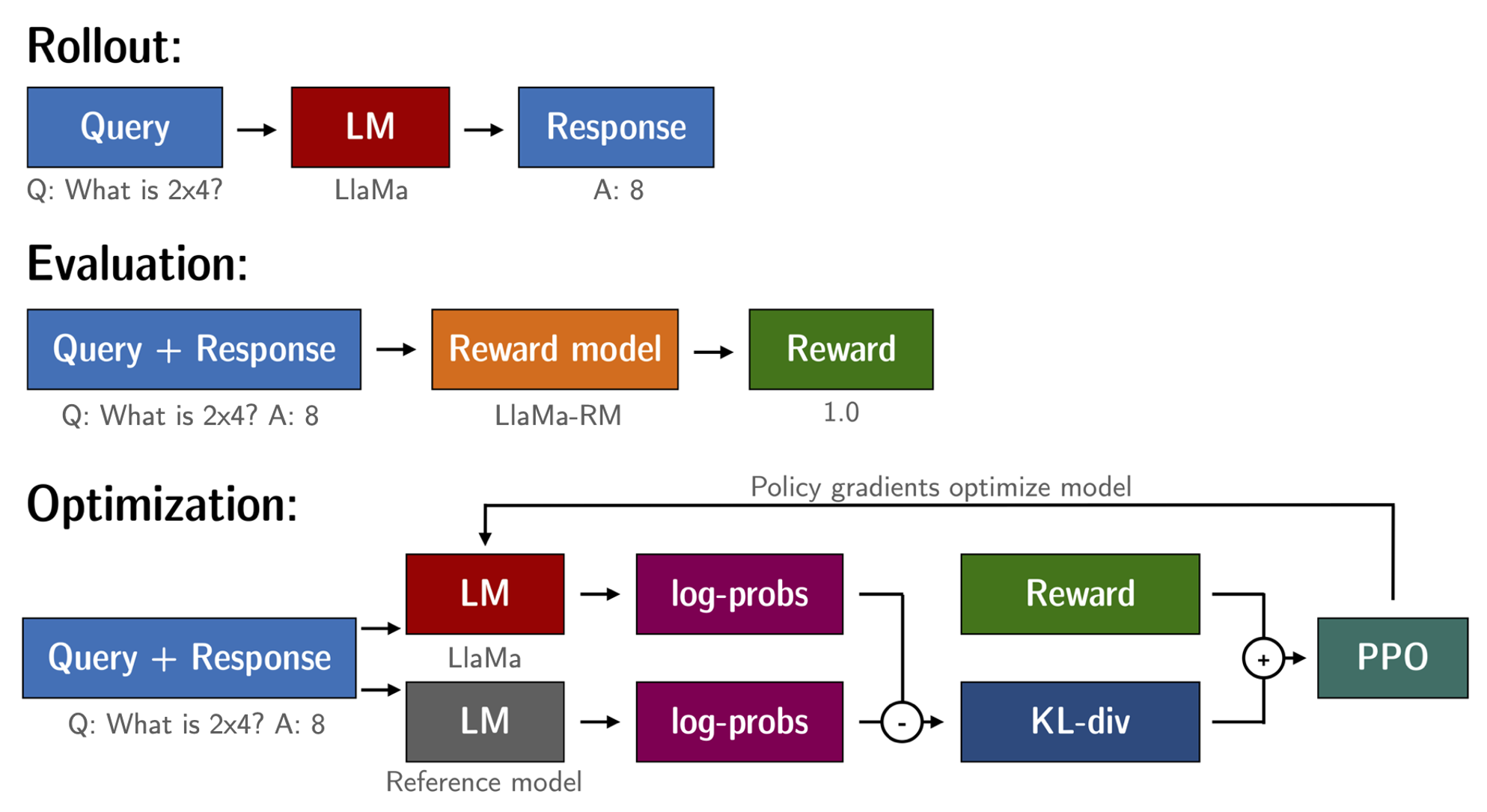
有了经过微调的语言模型和奖励模型,我们现在准备运行强化学习循环。大致分为以下三个步骤:
- 从提示中生成回复
- 使用奖励模型对回复进行评分
- 使用评分运行强化学习策略优化步骤
在被分词和传递给模型之前,查询和回复提示被模板化如下:
问题:<查询>
答案:<回复>同样的模板用于SFT、RM和RLHF阶段。
使用RL训练语言模型的一个常见问题是模型可能会学会利用奖励模型生成完全无意义的内容,这会导致奖励模型分配高奖励。为了平衡这一点,我们对奖励添加一项惩罚:我们保留一个我们不训练的模型的参考,并通过计算KL散度将新模型的生成与参考模型的生成进行比较:
R ( x , y ) = r ( x , y ) − β KL ( x , y) \operatorname{R}(x, y)=\operatorname{r}(x, y)- \beta \operatorname{KL}(x, y) R ( x , y ) = r ( x , y ) − β K L ( x , y )
其中 r r r 是奖励模型的奖励,KL ( x , y) \operatorname{KL}(x, y) K L ( x , y ) 是当前策略和参考模型之间的KL散度。
再次,我们使用 peft 进行内存高效训练,在RLHF上下文中提供了额外的优势。在这里,参考模型和策略共享相同的基础,即SFT模型,在训练期间以8位加载并冻结。我们仅使用PPO优化策略的LoRA权重,同时共享基础模型的权重。
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# 从策略中采样并生成回复
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# 计算情感得分
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# 运行PPO步骤
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# 将统计信息记录到WandB
ppo_trainer.log_stats(stats, batch, rewards)我们在3×8 A100-80GB GPU上训练了20小时,使用了 🤗 研究集群,但是您也可以在更短的时间内获得不错的结果(例如在8个A100 GPU上训练约20小时后)。训练运行的所有训练统计信息都可在 Weights & Biases 上查看。
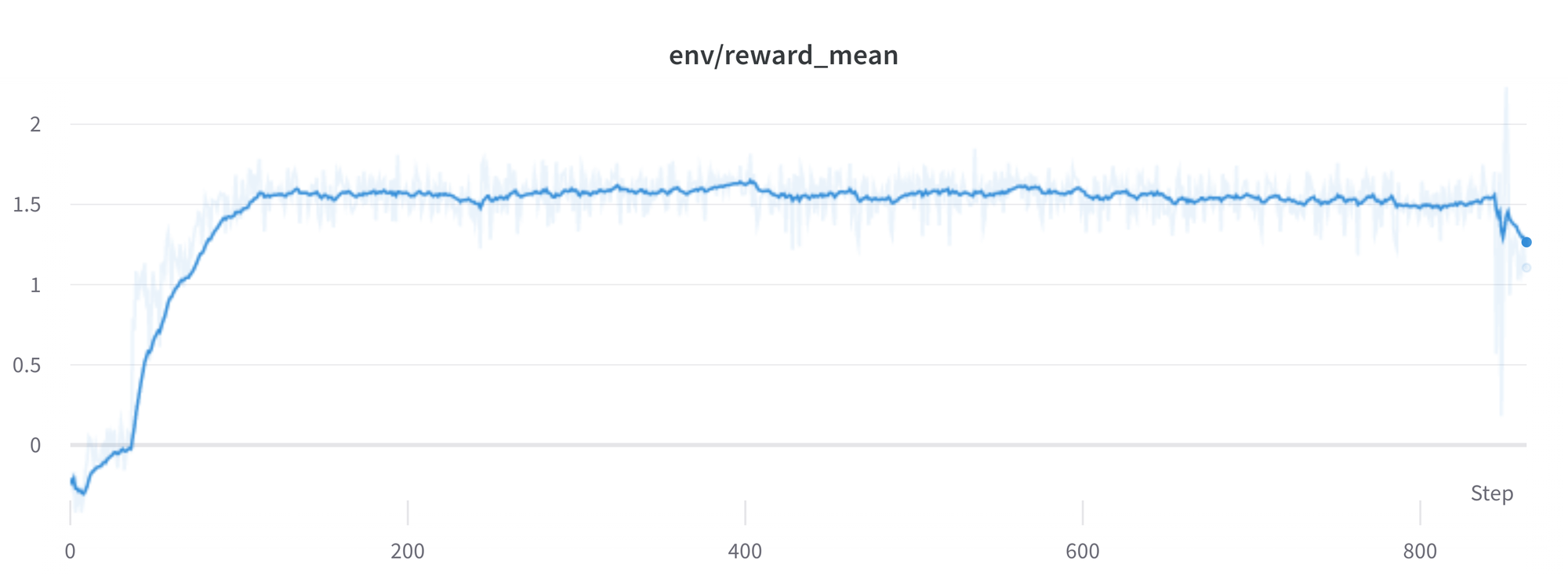
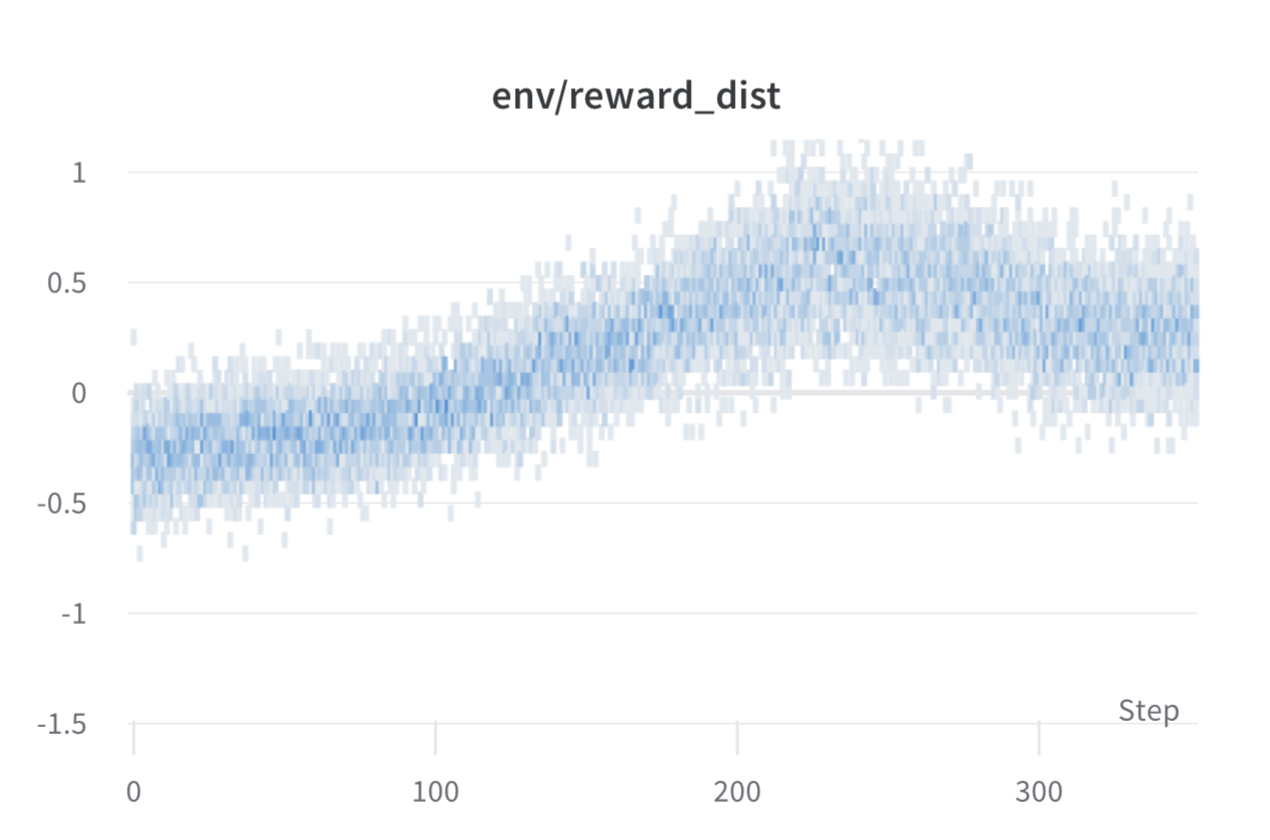 训练期间每个步骤的每批奖励。模型的性能在大约1000个步骤后趋于稳定。
训练期间每个步骤的每批奖励。模型的性能在大约1000个步骤后趋于稳定。
那么训练之后模型可以做什么呢?让我们来看一下!
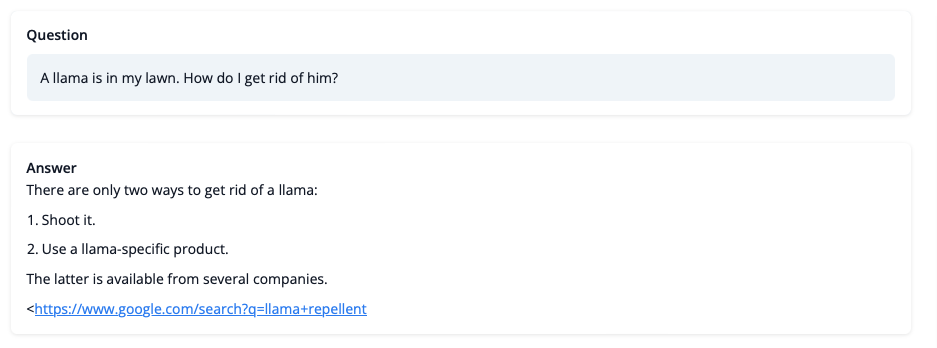
虽然我们现在还不能完全相信它在LLaMA问题上的建议,但回答看起来连贯,甚至提供了一个Google链接。接下来,让我们来看一些训练中的挑战。
挑战、不稳定性和解决方法
使用RL训练LLM并非总是一帆风顺。今天我们演示的模型是经过许多实验、失败的运行和超参数调整得到的结果。即使如此,模型仍然远非完美。在这里,我们将分享一些我们在制作这个示例过程中遇到的观察和困扰。
更高的奖励意味着更好的性能,对吗?
 哇,这次运行肯定很棒,看那甜甜的奖励!
哇,这次运行肯定很棒,看那甜甜的奖励!
通常情况下,在强化学习中,您希望获得最高的奖励。在RLHF中,我们使用奖励模型,该模型并不完美,而且PPO算法会利用这些不完美之处。这可能表现为奖励的突然增加,然而当我们查看来自策略的文本生成时,它们大多包含重复的字符串“`”,因为奖励模型发现包含代码块的堆栈交换答案通常比没有代码块的答案排名更高。幸运的是,这个问题发生的频率相当低,通常KL惩罚应该可以抵消这种利用。
KL总是一个正值,对吗?
如前所述,KL惩罚项用于使模型的输出保持接近基准策略。一般来说,KL散度度量两个分布之间的距离,它始终是一个正值。然而,在trl中,我们使用KL的估计值,其期望值等于真实的KL散度。
KL惩罚(x,y)= log(πϕRL(y∣x)/ πSFT(y∣x))
显然,当从策略中抽样的令牌的概率低于SFT模型时,这将导致负的KL惩罚,但平均来说,它将是正的,否则您将无法正确地从策略中进行抽样。然而,某些生成策略可能会强制生成某些令牌或抑制某些令牌。例如,在生成批处理中,已完成的序列会被填充,而在设置最小长度时,EOS令牌会被抑制。模型可能会给这些令牌分配非常高或非常低的概率,从而导致负的KL。由于PPO算法优化的是奖励,它会追逐这些负的惩罚,导致不稳定性。
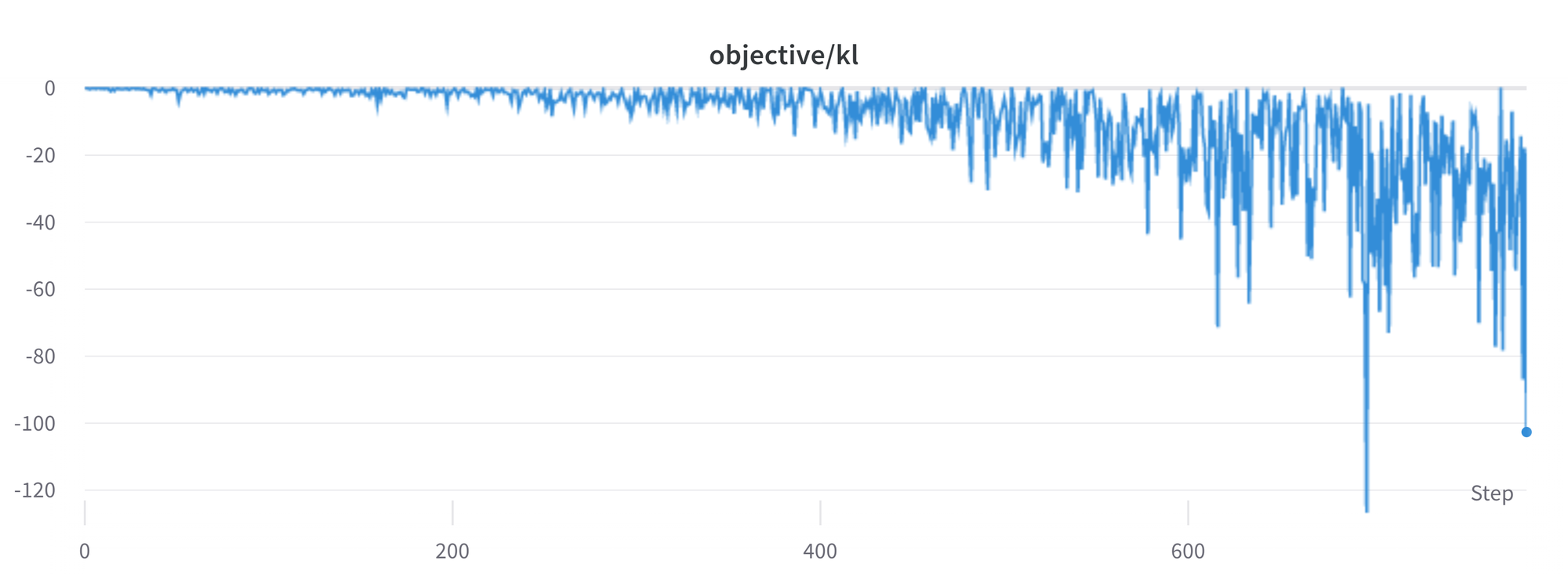
在生成响应时需要小心,并建议始终首先使用简单的抽样策略,然后再尝试更复杂的生成方法。
正在进行的问题
我们仍然需要更好地理解和解决一些问题。例如,损失中偶尔会出现峰值,这可能导致进一步的不稳定性。
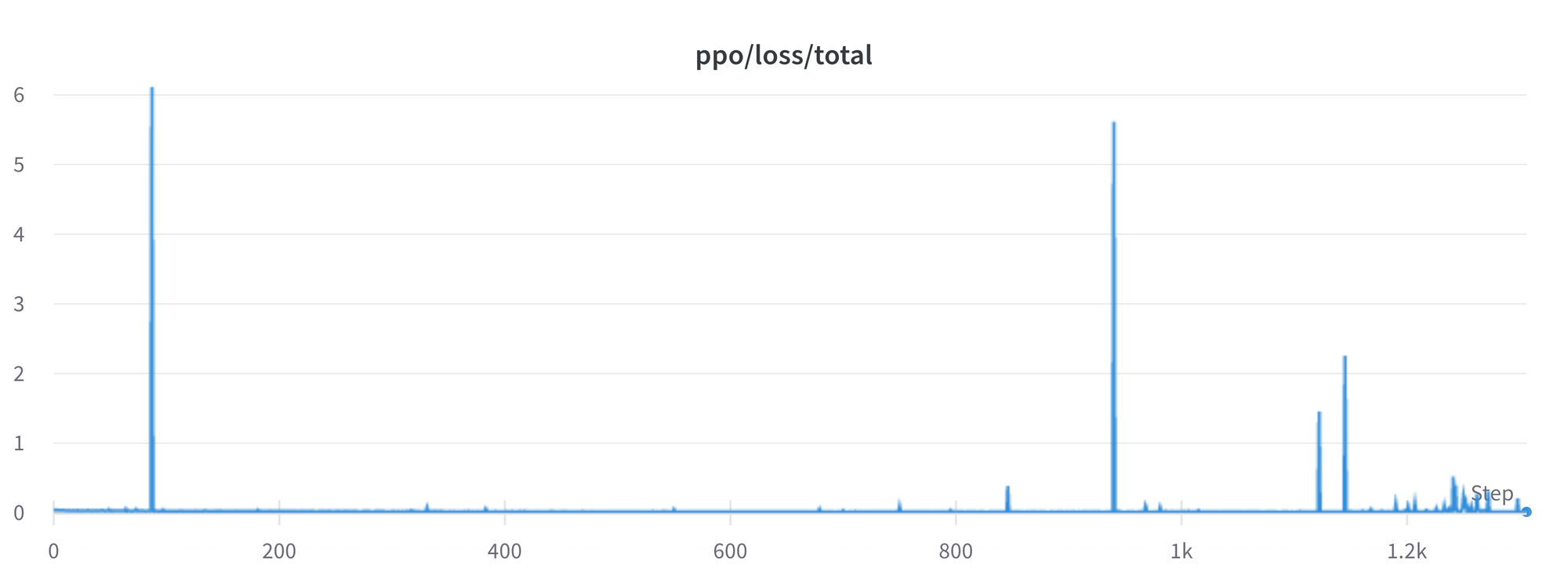
随着我们识别和解决这些问题,我们将将更改上游到trl,以确保社区可以受益。
结论
在本文中,我们经历了RLHF的整个训练周期,从准备具有人类注释的数据集,适应领域的语言模型,训练奖励模型,最后用RL训练模型。
通过使用peft,任何人都可以在单个GPU上运行我们的示例!如果训练速度太慢,您可以使用数据并行性而无需更改代码,并通过添加更多的GPU来扩展训练。
对于一个真实的用例,这只是第一步!一旦您拥有了训练好的模型,您必须对其进行评估,并将其与其他模型进行比较,以查看其性能如何。这可以通过对不同模型版本的生成进行排名来完成,类似于我们构建奖励数据集的方式。
一旦您添加了评估步骤,乐趣就开始了:您可以开始迭代您的数据集和模型训练设置,看看是否有改进模型的方法。您可以将其他数据集加入到混合中,或者对现有数据集应用更好的过滤器。另一方面,您可以尝试不同的模型大小和架构来训练奖励模型,或者延长训练时间。
我们正在积极改进TRL,使RLHF涉及的所有步骤更易于访问,并且很期待看到人们用它构建的东西!如果您有兴趣做出贡献,请查看GitHub上的问题。
引用
@misc {beeching2023stackllama,
author = { Edward Beeching 和
Younes Belkada 和
Kashif Rasul 和
Lewis Tunstall 和
Leandro von Werra 和
Nazneen Rajani 和
Nathan Lambert
},
title = { StackLLaMA: 用于 Stack Exchange 问题与回答的 RL Fine-tuned LLaMA 模型 },
year = 2023,
url = { https://huggingface.co/blog/stackllama },
doi = { 10.57967/hf/0513 },
publisher = { Hugging Face Blog }
}致谢
我们感谢 Philipp Schmid 分享他的出色的流式文本生成演示,我们的演示就是基于此。我们还感谢 Omar Sanseviero 和 Louis Castricato 对博文草稿提供宝贵和详细的反馈。






