用Python处理多变量分类数据的7种可视化方法
Python处理多变量分类数据的7种可视化方法
以简单方式展示复杂分类数据的思路。

一些常见的数据,比如著名的鸢尾花或企鹅数据集,用于分析起来相当简单,因为它们只有少量的分类变量。然而,现实世界的数据可能更加复杂,包含多个层次的分类。
多变量分类数据是一种具有众多类别的数据类型。例如,我们考虑对人进行分组。由于人的特征可能依赖于性别、国籍、薪资范围或教育水平等不同的分类,所以可能存在很多可能性。而车辆也有各种各样的分类变量,如品牌、原产国、燃料类型、车型等。

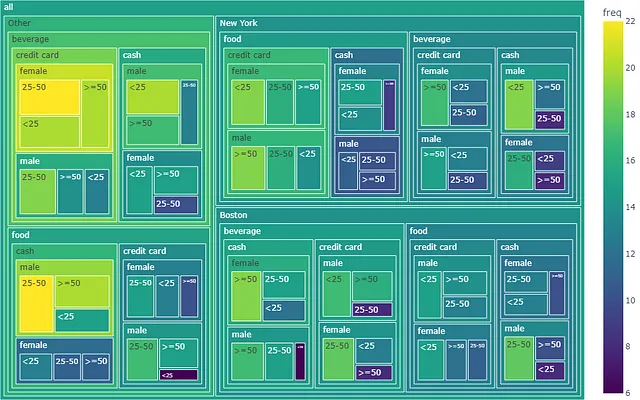
推荐使用数据可视化进行探索性数据分析(EDA),以帮助理解数据。柱状图或饼图等图表是绘制简单分类数据的基本选择。然而,由于分类变量存在多个层次,展示多变量分类数据可能会更加复杂。因此,本文将介绍一些可以表达具有多个层次分类的数据的图表。
- PyTorch模型性能分析与优化 — 第6部分
- 在生成式人工智能时代重新思考质量保证
- “令人难以置信的虚拟化:梅赛德斯-奔驰准备使用NVIDIA Omniverse、MB.OS和生成式人工智能为下一代平台打造数字化生产系统”
获取数据
首先导入所需的库。
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline本文将使用一个包含5个类别的模拟数据集。生成的数据集包含了杂货店顾客的信息:地点、产品、支付方式、性别和年龄范围。下面的代码展示了如何使用随机库生成每个分类变量。
如果你想尝试使用其他多变量分类数据集的可视化代码,可以跳过下一步。





