在大型语言模型(LLM)时代平衡创新与安全与隐私
Balancing innovation, security, and privacy in the era of large-scale language models (LLMs).
实施生成式AI应用的安全和隐私机制指南
AI时代已将大型语言模型(LLM)引领到技术前沿,这在2023年引起了广泛讨论,并有可能在接下来的多年中持续如此。LLM是AI模型的动力源,例如ChatGPT。这些AI模型凭借大量的数据和计算能力,解锁了卓越的能力,从生成类似人类的文本到辅助自然语言理解(NLU)任务。它们迅速成为了无数应用和软件服务的基础,或者至少是被增强的基础。
然而,与任何突破性创新一样,LLM的崛起带来了一个关键问题——“我们如何在追求技术进步的同时平衡安全和隐私的必要性?”这不仅仅是一个哲学问题,而是需要积极和深思熟虑的行动的挑战。
安全和隐私
为了在我们的LLM驱动应用中优先考虑安全和隐私,我们将重点关注关键领域,包括控制个人数据(即个人可识别信息,即PII)和有害或有毒内容的传播。无论您是使用自己的数据集来微调LLM,还是仅仅用LLM进行文本生成任务,这都是必不可少的。这有几个重要原因。
- 遵守政府法规,要求保护用户个人信息(如GDPR、CCPA、HIPAA隐私规则等)
- 遵守LLM提供商的最终用户许可协议(EULA)或可接受使用政策(AUP)
- 遵循组织内设定的信息安全政策
- 减少模型微调后可能存在的偏见和倾斜
- 确保LLM的合法使用并保护品牌声誉
- 为可能出现的任何AI监管做好准备
微调的考虑事项
在准备对LLM进行微调时,第一步是数据准备。除了研究、教育或个人项目外,您可能会遇到训练数据中包含PII信息的情况。这里的第一步是识别数据中存在的这些PII实体,第二步是清洗数据,确保这些PII实体得到适当的匿名处理。
- 使用Zipper快速构建无服务器应用程序:编写TypeScript,将其他所有工作卸载
- VoAGI新闻,9月20日:Python在Excel中:这将永久改变数据科学 • 新的VoAGI调查!
- 2024年的前5所大学证书

文本生成的考虑事项
对于使用LLM进行文本生成,有一些需要注意的事项。首先,我们确保任何包含有害内容的提示被限制不传播给LLM,其次我们确保我们的提示不包含任何PII实体。接下来,在某些情况下,可能适合在“机器生成的文本”上运行这些验证,从而对LLM生成的文本进行双重保护,以确保我们的安全和隐私理念。第三个方面是确定提示本身的意图,这在某种程度上可能限制提示注入攻击等问题。然而,本文主要关注PII和有害内容,并将在另外的讨论中讨论意图分类及其对LLM的影响。

实施
为了实施这个解决方案,我们将采取两个步骤。首先,我们使用一个名词实体识别(NER)模型,可以识别文本中的PII实体,并允许我们对这些实体进行匿名化。PII实体通常包括人名、位置或地址、电话号码、信用卡号、社会安全号码等。其次,我们使用一个文本分类模型来判断文本是否是“有害”的或“中性”的。有害文本的例子通常是包含滥用、粗言秽语、骚扰、欺凌等内容的文本。
对于PII NER模型,最常见的选择是使用BERT Base模型,可以进行微调以检测特定的PII实体。您还可以对预训练的转换器模型进行微调,例如Robust DeID(去识别)预训练模型,它是一个针对医疗记录的去识别的RoBERTa模型,主要关注个人健康信息(即PHI)。一个更简单的开始实验的选择是使用spaCy ER(EntityRecognizer)。
import spacynlp = spacy.load("en_core_web_lg")text = "申请人的姓名是John Doe,他住在Silver St.的电话号码是555-123-1290"doc = nlp(text)displacy.render(doc, style="ent", jupyter=True)这将给我们提供

spaCy EntityRecognizer能够识别出三个实体-PERSON(人物,包括虚构人物)、FAC(位置或地址)和CARDINAL(不属于其他类型的数字)。spaCy还给出了检测到的实体的起始和结束偏移量(文本中的字符位置),我们可以使用它们进行匿名化处理。
ent_positions = [(ent.start_char, ent.end_char) for ent in doc.ents]for start, end in reversed(ent_positions): text = text[:start] + '#' * (end - start) + text[end:]print(text)这将给我们提供
申请人的姓名是########,他住在###################的电话号码是###-123-1290但是这里存在一些明显的问题。spaCy ER的默认实体列表不全面,无法覆盖所有类型的PII实体。例如,在我们的案例中,我们希望将555-123-1290识别为PHONE_NUMBER,而不仅仅是作为CARDINAL文本的一部分,导致实体检测不完整。当然,就像基于transformer的NER模型一样,spaCy也可以使用自己的自定义名称实体数据集进行训练,以使其更加鲁棒。然而,我们将使用更加专门用于数据保护和去识别的开源Presidio SDK。
使用Presidio进行PII检测和匿名化
Presidio SDK提供了一整套PII检测功能,支持多种PII实体。Presidio主要使用模式匹配,结合spaCy和Stanza的ML能力。但是,Presidio是可定制的,可以插入使用基于transformer的PII实体识别模型,甚至可以与云端的PII能力(如Azure Text Analytics PII检测或Amazon Comprehend PII检测)进行集成。它还配备了一个内置的可定制的匿名化工具,可以帮助从文本中删除和隐藏PII实体。
from presidio_analyzer import AnalyzerEnginetext="""申请人的姓名是John Doe,他住在Silver St.,电话号码是555-123-1290。"""analyzer = AnalyzerEngine()results = analyzer.analyze(text=text, language='en')for result in results: print(f"PII类型={result.entity_type},", f"起始偏移量={result.start},", f"结束偏移量={result.end},", f"分数={result.score}")这将给我们提供
PII类型=PERSON,起始偏移量=21,结束偏移量=29,分数=0.85PII类型=LOCATION,起始偏移量=50,结束偏移量=60,分数=0.85PII类型=PHONE_NUMBER,起始偏移量=85,结束偏移量=97,分数=0.75和

正如我们之前所见,匿名化文本是一个相当简单的任务,因为我们有文本中每个实体的开始和结束偏移量。然而,我们将利用Presidio的内置AnonymizerEngine来帮助我们完成这个任务。
from presidio_anonymizer import AnonymizerEngineanonymizer = AnonymizerEngine()anonymized_text = anonymizer.anonymize(text=text,analyzer_results=results)print(anonymized_text.text)这将给我们:
申请人的姓名是<PERSON>,他住在<LOCATION>,他的电话号码是<PHONE_NUMBER>。到目前为止都很好,但如果我们希望匿名化只是简单的屏蔽,该怎么办?在这种情况下,我们可以向AnonymizerEngine传入自定义配置,以执行PII实体的简单屏蔽。例如,我们只用星号(*)字符屏蔽实体。
from presidio_anonymizer import AnonymizerEnginefrom presidio_anonymizer.entities import OperatorConfigoperators = dict()# 假设`results`是`AnalyzerEngine`对PII实体检测的输出for result in results: operators[result.entity_type] = OperatorConfig("mask", {"chars_to_mask": result.end - result.start, "masking_char": "*", "from_end": False})anonymizer = AnonymizerEngine()anonymized_results = anonymizer.anonymize( text=text, analyzer_results=results, operators=operators)print(anonymized_results.text)这将给我们:
申请人的姓名是********,他住在**********,他的电话号码是************。匿名化的注意事项
在决定对文本中的PII实体进行匿名化时,有几个需要记住的事项。
- Presidio的默认
AnonymizerEngine使用模式<ENTITY_LABEL>来屏蔽PII实体(例如<PHONE_NUMBER>)。这可能会导致问题,尤其是在LLM微调时。用实体类型标签替换PII可能会引入具有语义意义的词语,可能会影响语言模型的行为。 - 伪匿名化是一种有用的数据保护工具,但在对训练数据进行伪匿名化时应谨慎。例如,在微调数据中用伪名
John Doe替换所有的NAME实体,或者用01-JAN-2000替换所有的DATE实体,可能会导致微调模型中出现极端偏见。 - 要注意你的LLM对提示中的某些字符或模式的反应。某些LLM可能需要一种非常特定的方式来构建提示,以最大程度地利用模型,例如Anthropic建议使用提示标签。了解这一点将有助于决定如何进行匿名化处理。
匿名化数据对模型微调可能会产生其他一般性的副作用,例如丢失上下文、语义漂移、模型产生幻觉等等。在最小化对模型性能的负面影响的同时,进行迭代和实验以确定适合您需求的匿名化水平非常重要。
使用文本分类进行有害内容检测
为了判断文本是否包含有害内容,我们将采用二分类方法 —— 如果文本是中性的,则为0;如果文本是有害的,则为1。我决定训练一个DistilBERT基础模型(uncased),这是一个BERT基础模型的精简版本。对于训练数据,我使用了Jigsaw数据集。
我不会详细介绍模型的训练方式和模型指标等等,但你可以参考这篇关于训练DistilBERT基础模型用于文本分类任务的文章。你可以在这里看到我编写的模型训练脚本。该模型在HuggingFace Hub上可用,名称为tensor-trek/distilbert-toxicity-classifier。让我们通过推理来运行一些示例文本,看看模型给出的结果。
from transformers import pipeline
text = ["这是一部杰作。虽然没有完全忠于原著,但从头到尾都令人着迷。可能是我最喜欢的三部曲之一。",
"我希望我能杀死那只鸟,我讨厌它。"]
classifier = pipeline("text-classification", model="tensor-trek/distilbert-toxicity-classifier")
classifier(text)
这个模型以相当高的置信度将文本正确分类为中性或有害。这个文本分类模型,结合我们之前讨论过的PII实体分类,现在可以用来创建一个可以在我们的LLM驱动的应用程序或服务中强制实施隐私和安全性的机制。
将事物整合在一起
我们通过PII实体识别机制解决了隐私问题,通过文本有害性分类器解决了安全问题。您可以考虑其他可能与您组织对安全性和隐私性的定义相关的机制。例如,医疗保健机构可能更关注PHI而不是PII等等。无论您想引入哪种控制机制,整体实现方法都是相同的。
考虑到这一点,现在是将所有内容整合到一起并付诸行动的时候了。我们希望能够将隐私和安全机制与LLM结合在一起,用于我们希望引入生成AI能力的应用程序。我将使用流行的LangChain框架的Python版本(也可在JavaScript/TS中使用)来构建一个包含这两个机制的生成AI应用程序。下面是我们整体架构的样子。
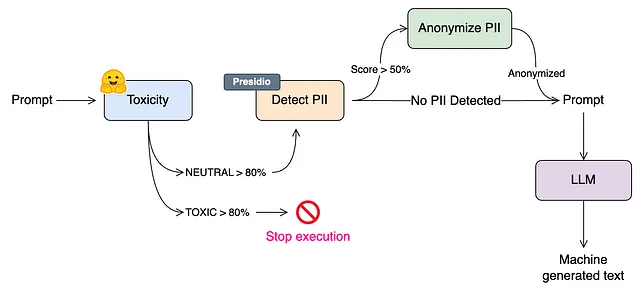
在上述架构中,我首先检查文本是否包含至少80%模型准确度的有害内容。如果是这样,整个LangChain应用程序的执行将在此处停止,并向用户显示相应的消息。如果文本被大部分分类为中性,那么我将将其传递到下一步以识别PII实体。然后,如果每个实体检测的置信度得分超过50%,则对文本中的这些实体进行匿名处理。一旦文本完全匿名化,就将其作为提示传递给LLM以进行进一步的文本生成。请注意,准确性阈值(80%和50%)是任意的,您需要测试PII和有害性检测器在您的数据上的准确性,并决定适合您用例的阈值。阈值越低,系统变得越严格,阈值越高,这些检查的执行就越弱。
另一种更保守的方法是在检测到任何PII实体时停止执行。这对于未获得处理PII数据的认证的应用程序可能很有用,您希望确保不管怎样,包含PII的文本都不会成为输入进入该应用程序。
LangChain实现
为了使其与LangChain配合使用,我创建了一个名为PrivacyAndSafetyChain的自定义链。这可以与任何LangChain支持的LLM配合使用,以实现隐私和安全机制。下面是它的样子 –
from langchain import HuggingFaceHub
from langchain import PromptTemplate, LLMChain
from PrivacyAndSafety import PrivacyAndSafetyChain
safety_privacy = PrivacyAndSafetyChain(verbose=True,
pii_labels=["电话号码", "美国社会安全号码"])
template = """{question}"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = HuggingFaceHub(repo_id=repo_id, model_kwargs={"temperature": 0.5, "max_length": 256})
chain = (prompt
| safety_privacy
| {"input": (lambda x: x['output']) | llm}
| safety_privacy)
try:
response = chain.invoke({"question": """以下文本中John Doe的地址、电话号码和社会安全号码是什么?John Doe住在斯普林菲尔德的1234号榆树街,最近在1月1日庆祝了生日。今年43岁的约翰回顾了过去的岁月。他经常通过电话(555)123-4567与他的亲密朋友分享他年轻时的回忆。与此同时,在一个轻松的晚上,他收到了一封电子邮件,提醒他一个老朋友的聚会。当他浏览一些旧文件时,他偶然发现一张纸列出了他的社会安全号码为338-12-6789,并提醒他将其存放在一个更安全的地方。"""})
except Exception as e:
print(str(e))
else:
print(response['output'])
默认情况下,PrivacyAndSafetyChain 首先执行毒性检测。如果检测到任何有毒内容,它将出错,从而停止链条,正如我们之前讨论的那样。如果没有检测到毒性内容,则将输入的文本传递给 PII 实体识别器,并根据要使用的掩码字符,链条将对检测到的 PII 实体的文本进行匿名化处理。前面代码的输出如下所示。由于没有有毒内容,链条没有停止,并且它检测到了PHONE_NUMBER和SSN并正确地对其进行了匿名化处理。
> 输入新的 PrivacyAndSafetyChain 链...运行 PrivacyAndSafetyChain...检查毒性内容...检查 PII...> 完成链条。> 输入新的 PrivacyAndSafetyChain 链...运行 PrivacyAndSafetyChain...检查毒性内容...检查 PII...> 完成链条。1234 Elm 街, **************, ***********结论
本文的最大收获是,在我们继续创新大型语言模型的过程中,必须在创新和安全、隐私之间取得平衡。对LLM(大型语言模型)的热情以及我们对其与可能的各种用例进行整合的不断增长的渴望是不可否认的。然而,潜在的风险,如数据隐私泄露、意外偏见或滥用,同样是真实存在的,需要我们立即关注。我介绍了如何在LLM中建立检测PII和毒性内容的机制,并讨论了使用LangChain的实现。
仍然有许多研究和开发需要进行,也许有更好的架构,更可靠和无缝的确保数据隐私和安全的方法。本文中的代码为简洁起见进行了精简,但我鼓励您查看我的 GitHub 存储库,在那里我整理了每个步骤的详细笔记本以及我们讨论的自定义LangChain的完整源代码。使用它,派生它,改进它,继续创新!
参考资料
[1] Jacob Devlin, Ming-Wei Chang et. al. 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
[2] Victor Sanh, Lysandre Debut et. al《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》
[3] 数据集 – Jigsaw Multilingual Toxic Comment Classification 2020
除非另有说明,所有图片均为作者所提供





