“监控LLM和NLP的非结构化数据”
Monitoring unstructured data in LLM and NLP
使用文本描述符的代码教程
一旦部署了一个基于NLP或LLM的解决方案,您需要一种方法来监视它。但是如何监测非结构化数据以理解文本堆的含义呢?
在这里有几种方法,可以从检测原始文本数据中的漂移和嵌入漂移,到使用正则表达式进行基于规则的检查。
在本教程中,我们将深入探讨一种特定的方法,即跟踪可解释的文本描述符,这些描述符可以帮助给每个文本分配特定的属性。
首先,我们将介绍一些理论知识:
- 什么是文本描述符,何时使用它们。
- 文本描述符的示例。
- 如何选择自定义描述符。
接下来,开始编码! 您将使用电子商务评论数据,并完成以下步骤:
- 获取文本数据的概述。
- 使用标准描述符评估文本数据的漂移。
- 使用外部预训练模型添加自定义文本描述符。
- 实施管道测试以监控数据变化。
我们将使用开源Python库Evidently生成文本描述符并评估数据的变化。
代码示例: 如果您更喜欢直接查看代码,这是示例笔记本。
什么是文本描述符?
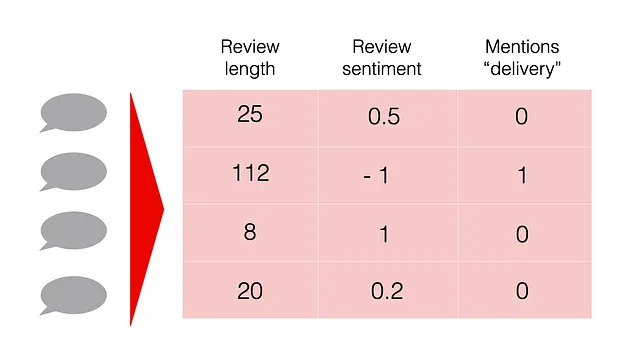
文本描述符是描述文本数据集中对象的任何特征或属性。例如,文本的长度或其中的符号数量。
您可能已经有一些有用的元数据与您的文本一起,这些元数据可以作为描述符。例如,电子商务用户评价可能附带用户分配的评级或主题标签。
否则,您可以生成自己的描述符!您可以通过向文本数据添加“虚拟特征”来实现。每个特征都可以使用一些有意义的标准来描述或分类您的文本。
通过创建这些描述符,您实际上是在为自己创建一个简单的“嵌入”,并将每个文本映射到几个可解释的维度。这有助于理解原本非结构化的数据。
然后,您可以使用这些文本描述符:
- 监视生产NLP模型。 您可以跟踪数据的属性,并检测其何时发生变化。例如,描述符有助于检测文本长度的突增或情感漂移。
- 在更新期间测试模型。 当您迭代模型时,可以比较评估数据集和模型响应的属性。例如,您可以检查LLM生成的答案的长度是否保持相似,并且它们始终包含您期望看到的单词。
- 调试数据漂移或模型衰退。 如果您检测到嵌入漂移或直接观察到模型质量下降,您可以使用文本描述符来探索其来源。
文本描述符的示例
以下是我们认为是很好的默认文本描述符:
文本长度
一个很好的起点是简单的文本统计。例如,您可以查看以单词、符号或句子为单位的文本长度。您可以评估平均长度和最小-最大长度,并查看分布情况。
您可以基于您的用例设置期望值。例如,产品评论的长度通常在5到100个单词之间。如果它们更短或更长,这可能表示上下文发生了变化。如果固定长度的评论数量激增,这可能表示存在垃圾邮件攻击。如果您知道负面评论通常更长,您可以跟踪超过一定长度的评论占比。
还有一些快速的健全性检查:如果你运行一个聊天机器人,你可能希望得到非零的回复,或者有一些最小长度的有意义的输出。
词汇外的单词

评估定义词汇范围之外的单词的共享比例是一种衡量数据质量的“粗略”方法。你的用户是否开始用新语言撰写评论?用户是否用Python而不是英语与你的聊天机器人交流?用户是否在回复中填充“ggg”而不是实际单词?
这是一种单一实用的措施,可以检测到各种变化。一旦发现变化,你可以进行更深入的调试。
你可以根据随时间累积的“良好”生产数据示例来形成关于词汇外单词共享比例的预期。例如,如果你查看以前产品评论的语料库,你可能期望词汇外的单词不超过10%,并监测该值是否超过此阈值。
非字母字符
相关,但有所不同:此描述符将计算所有不是字母或数字的特殊符号的数量,包括逗号、括号、井号等。
有时你会期望有一定比例的特殊符号:你的文本可能包含代码或以JSON格式结构化。有时,你只期望在可读的文本中出现标点符号。
检测非字母字符的变化可以揭示数据质量问题,比如HTML代码泄漏到评论文本中、垃圾邮件攻击、意外的使用情况等。
情感
文本情感是另一个指标。它在各种场景中都很有帮助:从聊天机器人对话到用户评论和编写营销文案。你通常可以对你处理的文本的情感设置期望。
即使情感“不适用”,这可能会转化为主要中性语气的期望。负面或正面语气的出现可能值得追踪和研究。它可能表示意外的使用情况:用户是否将你的虚拟抵押贷款顾问用作投诉渠道?
你还可能期望一定的平衡:例如,总会有一部分带有负面语气的对话或评论,但你期望它不会超过一定的阈值,或者评论情感的整体分布保持稳定。
触发词
你还可以检查文本中是否包含特定列表或列表中的单词,并将其视为二元特征。
这是一种强大的方式来编码关于你的文本的多个期望。你需要一些努力来手动策划列表,但你可以通过这种方式设计许多方便的检查。例如,你可以创建触发词列表,例如:
- 产品或品牌的提及。
- 竞争对手的提及。
- 地点、城市、地点等的提及。
- 代表特定主题的单词的提及。
你可以策划(并不断扩展)特定于你的用例的类似列表。
例如,如果一个顾问聊天机器人帮助选择公司提供的产品之一,你可能期望大多数回复包含列表中某个产品的名称。
正则表达式匹配
从列表中包含特定单词是你可以用正则表达式表示的模式的一个示例。你可以想出其他模式:你是否期望你的文本以“你好”开头并以“谢谢”结尾?是否包含电子邮件?是否包含已知的命名元素?
如果您希望模型的输入或输出与特定格式匹配,您可以使用正则表达式匹配作为另一个描述符。
自定义描述符
您可以进一步扩展这个想法。例如:
- 评估其他文本属性:毒性、主观性、语气的正式程度、可读性分数等。您通常可以找到开放的预训练模型来实现。
- 计算特定组件的数量:电子邮件、URL、表情符号、日期和词性的部分。您可以使用外部模型甚至简单的正则表达式。
- 详细跟踪统计信息:如果对您的用例有意义,您可以跟踪非常详细的文本统计信息,例如跟踪单词的平均长度、它们是大写还是小写、唯一单词的比例等。
- 监控个人身份信息:例如,当您不希望它出现在聊天机器人对话中时。
- 使用命名实体识别:提取特定实体并将它们视为标签。
- 使用主题建模来构建主题监控系统。这是最费力的方法,但在正确使用时非常强大。当您希望文本大部分保持在主题上并且具有先前示例的语料库来训练模型时,它非常有用。您可以使用无监督的主题聚类,并创建一个模型来将新文本分配给已知的聚类。然后,您可以将分配的类别视为描述符,以监控新数据中主题分布的变化。

在设计用于监控的描述符时,请记住以下几点:
- 最好保持专注,尝试找到少量适合用例的适量质量指标,而不是监控所有可能的维度。将描述符视为模型特征。您希望找到一些强大的特征,而不是生成大量薄弱或无用的特征。其中许多特征可能存在相关性:语言和OOV词的比例,句子和符号的长度等。选择您最喜欢的!
- 使用探索性数据分析来评估现有数据中的文本属性(例如,以前对话的日志)以测试您的假设,然后再将其添加到模型监控中。
- 从模型故障中学习。每当您面临生产模型质量问题并且预计会再次出现时(例如,外语文本),请考虑如何开发一个测试用例或描述符以便在将来检测到它。
- 注意计算成本。使用外部模型按每个可能维度对您的文本进行评分很诱人,但这是有代价的。在处理较大数据集时请考虑它:每个外部分类器都是一个额外需要运行的模型。您通常可以减少或简化检查。
逐步教程
为了说明这个想法,让我们通过以下场景进行演示:您正在构建一个分类器模型,用于对用户在电子商务网站上留下的评论进行评分并标记它们的主题。一旦投入生产,您希望检测数据和模型环境的变化,但您没有真实标签。您需要运行单独的标记过程来获取它们。
没有标签的情况下,您如何跟踪这些变化呢?
让我们以一个示例数据集为例,按照以下步骤进行:
代码示例:请转到示例笔记本以按照所有步骤进行操作。
💻 1. 安装 Evidently
首先,安装 Evidently。使用Python包管理器将其安装到您的环境中。如果您在Colab中工作,请运行!pip install。在Jupyter Notebook中,您还应该安装nbextension。查看您的环境的说明。
您还需要导入一些其他库,如pandas和特定的Evidently组件。请按照笔记本中的说明进行操作。
🔡 2. 准备数据
一旦您准备好了,让我们来看看数据!您将使用来自电子商务评论的开放数据集进行工作。
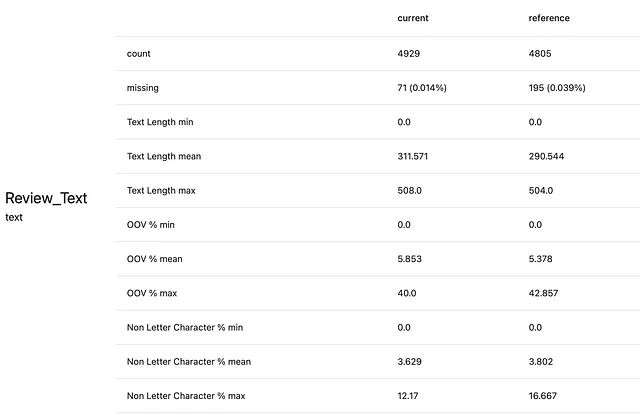
数据集的展示如下:
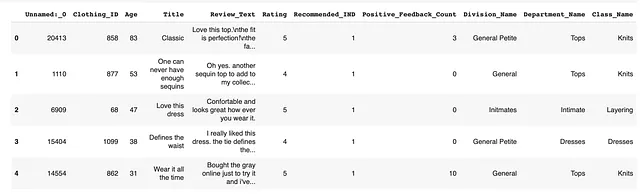
我们将重点关注“Review_Text”列进行演示。在生产中,我们希望监控评论文本的变化。
您需要使用列映射来指定包含文本的列:
column_mapping = ColumnMapping( numerical_features=['Age', 'Positive_Feedback_Count'], categorical_features=['Division_Name', 'Department_Name', 'Class_Name'], text_features=['Review_Text', 'Title'])您还需要将数据分成两部分:参考数据和当前数据。假设“参考”数据是某个代表性过去时期(例如,上个月)的数据,“当前”是当前生产数据(例如,本月)。这是您将使用描述符进行比较的两个数据集。
注意:建立合适的历史基准非常重要。选择反映您对未来数据形态的期望的时期。
我们为每个样本选择了5000个示例。为了增加趣味性,我们在当前数据集中选择了负面评价。
reviews_ref = reviews[reviews.Rating > 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)reviews_cur = reviews[reviews.Rating < 3].sample(n=5000, replace=True, ignore_index=True, random_state=42)📊 3. 探索性数据分析
为了更好地了解数据,您可以使用 Evidently 生成一个可视化报告。有一个预先构建的文本概览预设可以帮助快速比较两个文本数据集。它结合了各种描述性检查,并使用基于模型的漂移检测方法评估整体数据漂移。
该报告还包括一些标准描述符,并允许您使用触发词列表添加描述符。作为报告的一部分,我们将查看以下描述符:
- 文本长度
- 未登录词占比
- 非字母符号占比
- 评论的情感
- 包含“dress”或“gown”单词的评论
- 包含“blouse”或“shirt”单词的评论
有关详细信息,请参阅 Evidently 文档中的描述符部分。
以下是运行此报告所需的代码。您可以为每个描述符指定自定义名称。
text_overview_report = Report(metrics=[ TextOverviewPreset(column_name="Review_Text", descriptors={ "Review texts - OOV %" : OOV(), "Review texts - Non Letter %" : NonLetterCharacterPercentage(), "Review texts - Symbol Length" : TextLength(), "Review texts - Sentence Count" : SentenceCount(), "Review texts - Word Count" : WordCount(), "Review texts - Sentiment" : Sentiment(), "Reviews about Dress" : TriggerWordsPresence(words_list=['dress', 'gown']), "Reviews about Blouses" : TriggerWordsPresence(words_list=['blouse', 'shirt']), }) ]) text_overview_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) text_overview_report运行此类报告有助于探索模式并形成对特定属性(例如文本长度分布)的期望。
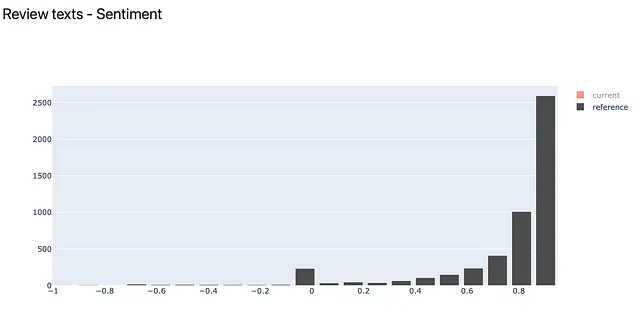
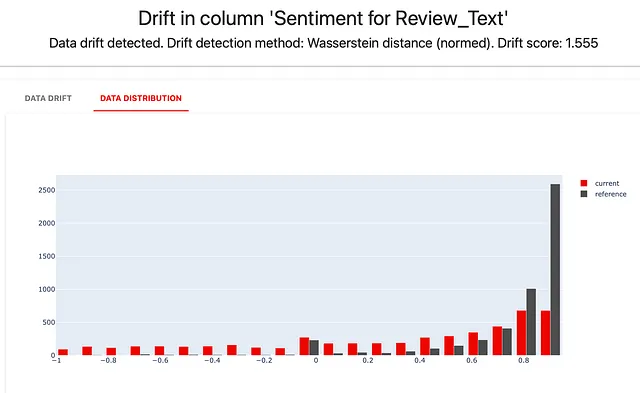
“情感”描述符的分布很快暴露了我们在分割数据时所做的技巧。我们将排名在3以上的评论放在“参考”数据中,并将更多的负面评论放在“当前”数据集中。结果如下所示:
默认报告非常全面,可以同时查看许多文本属性。还可以探索描述符与数据集中其他列之间的相关性!
您可以在探索阶段使用它,但这可能不是您每次都需要查看的内容。
幸运的是,它很容易定制。
显然的预设和度量标准。显然有报告预设,可以快速生成报告。但是,有很多个独立的度量标准可供选择!您可以将它们组合起来创建自定义报告。浏览预设和度量标准,了解其中的内容。
📈 4. 监控描述符的漂移
假设基于探索性分析和对业务问题的理解,您决定只跟踪少量属性:
您希望注意到是否有统计变化:这些属性的分布与参考期间不同。为了检测它,您可以使用Evidently中实现的漂移检测方法。例如,对于“情感”等数值特征,默认情况下它会使用Wasserstein距离来监控漂移。您也可以选择不同的方法。
以下是如何创建一个简单的漂移报告,以跟踪这三个描述符的变化。
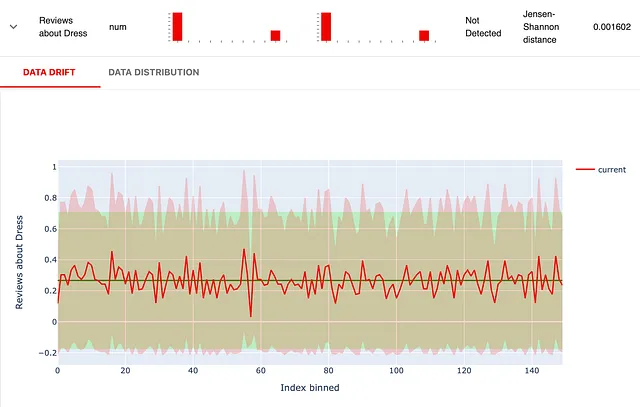
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Review_Text")), ColumnDriftMetric(Sentiment().for_column("Review_Text")), ColumnDriftMetric(TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_report运行报告后,您将获得所有选择的描述符的组合可视化。这是其中之一:

深绿色线是参考数据集中的情感均值。绿色区域覆盖了均值的一个标准差范围。您可以注意到当前分布(红色)明显更为消极。
注意:在这种情况下,监控输出漂移也是有意义的:通过跟踪预测类别的变化。您可以使用类别数据漂移检测方法,例如JS散度。我们在本教程中未涵盖此内容,因为我们只关注输入而不生成预测。实际上,预测漂移通常是第一个要反应的信号。
😍 5. 添加“情感”描述符
假设您决定跟踪另一个有意义的属性:评论中表达的情感。整体情感是一回事,但它还有助于区分“悲伤”和“愤怒”等不同类型的评论。
让我们添加这个自定义描述符!您可以找到一个适合的外部开源模型来对数据集进行评分。然后,您将使用此属性作为附加列进行处理。
我们将使用Huggingface的Distilbert模型,该模型将文本分类为五种情感。
对于您的用例,您可以考虑使用任何其他模型,例如命名实体识别、语言检测、毒性检测等。
您必须安装transformers才能运行该模型。请查看详细说明以获取更多细节。然后,将其应用于评论数据集:
from transformers import pipeline classifier = pipeline("text-classification", model='bhadresh-savani/distilbert-base-uncased-emotion', top_k=1) prediction = classifier("I love using evidently! It's easy to use", ) print(prediction)注意:此步骤将使用外部模型对数据集进行评分。根据您的环境,执行此操作可能需要一些时间。为了不必等待即可理解原理,请参阅示例笔记本中的“简单示例”部分。
在将新列“情感”添加到数据集后,您必须在列映射中反映这一点。您应该指定它是数据集中的一个新的分类变量。
column_mapping = ColumnMapping( numerical_features=['Age', 'Positive_Feedback_Count'], categorical_features=['Division_Name', 'Department_Name', 'Class_Name', 'emotion'], text_features=['Review_Text', 'Title'] )现在,您可以将“情感”分布漂移监控添加到报告中。
descriptors_report = Report(metrics=[ ColumnDriftMetric(WordCount().for_column("Review_Text")), ColumnDriftMetric(Sentiment().for_column("Review_Text")), ColumnDriftMetric(TriggerWordsPresence(words_list=['dress', 'gown']).for_column("Review_Text")), ColumnDriftMetric('emotion'), ]) descriptors_report.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_report这是你得到的内容!
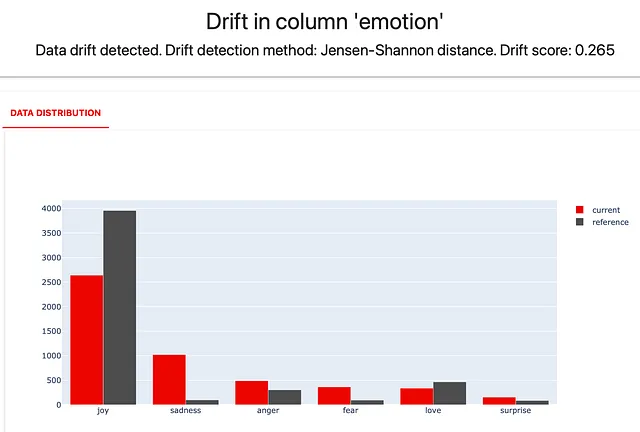
你可以看到“悲伤”评论的显著增加和“喜悦”评论的减少。
随着时间的推移,这样的跟踪是否有帮助?你可以在新数据到来时继续运行此检查。
🏗️ 6. 运行流水线测试
为了对数据输入进行定期分析,将评估打包为测试是有意义的。在这种情况下,你将得到明确的“通过”或“失败”结果。如果所有测试都通过,你可能不需要查看图表。只有当事物发生变化时,你才会感兴趣!
显然,还有一个名为“Test Suite”的替代界面,可以以此方式工作。
以下是如何创建一个测试套件来检查相同的四个描述符中的统计分布:
descriptors_test_suite = TestSuite(tests=[ TestColumnDrift(column_name = '情绪'), TestColumnDrift(column_name = WordCount().for_column("评论文本")), TestColumnDrift(column_name = Sentiment().for_column("评论文本")), TestColumnDrift(column_name = TriggerWordsPresence(words_list=['连衣裙', '礼服']).for_column("评论文本")), ]) descriptors_test_suite.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_test_suite注意:我们使用默认值,但你也可以设置自定义的漂移方法和条件。
这是结果。输出结构清晰,你可以看到哪些描述符发生了漂移。
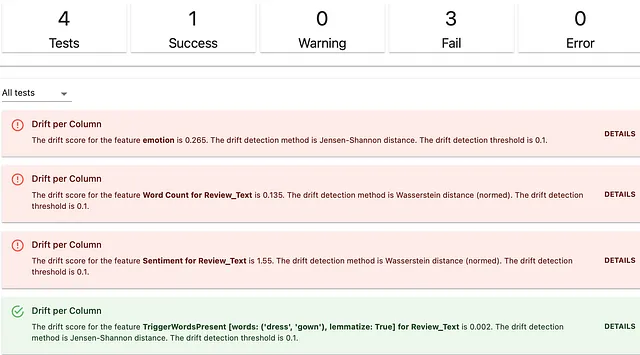
检测统计分布漂移是监测文本属性变化的方法之一。还有其他方法!有时,运行基于规则的预期值检查描述符的最小值、最大值或平均值是很方便的。
假设你想检查所有评论文本的长度是否大于两个词。如果至少有一个评论文本长度小于两个词,你希望测试失败并查看响应中的短文本数量。
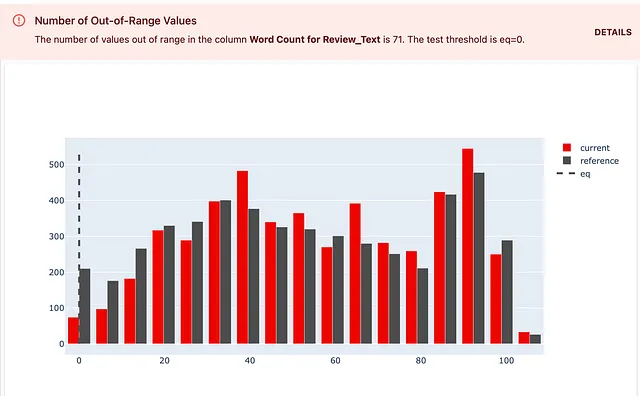
以下是如何做到这一点!你可以选择一个TestNumberOfOutRangeValues()检查。这次,你应该设置一个自定义边界:期望范围的“左”侧是两个词。你还必须设置一个测试条件:eq=0。这意味着你期望在这个范围之外的对象数量为0。如果数量更高,你希望测试返回失败。
descriptors_test_suite = TestSuite(tests=[ TestNumberOfOutRangeValues(column_name = WordCount().for_column("评论文本"), left=2, eq=0), ]) descriptors_test_suite.run(reference_data=reviews_ref, current_data=reviews_cur, column_mapping=column_mapping) descriptors_test_suite这是结果。你还可以看到显示了定义的预期的测试详细信息。
你可以按照这个原则设计其他检查。
支持 Evidently
喜欢这篇教程吗?在 GitHub 上给 Evidently 点个赞,为社区的免费开源工具和内容做出贡献。 ⭐️ 在 GitHub 上点赞 ⟶
总结
文本描述符将文本数据映射为可解释的维度,你可以将其表达为数值或分类属性。它们有助于描述、评估和监测非结构化数据。
在本教程中,你学会了如何使用描述符监测文本数据。
你可以使用这种方法来监测 NLP 和 LLM 模型的生产行为。你可以自定义和组合描述符与其他方法,例如监测嵌入漂移。
您是否还有其他您认为普遍有用的描述符?请告诉我们!加入我们的Discord社区,分享您的想法。
原始发布于2023年6月27日,https://www.evidentlyai.com。感谢Olga Filippova共同撰写本文。






