日本稳定扩散
'Japan stable diffusion.'
![]()
稳定扩散(Stable Diffusion)是由CompVis、Stability AI和LAION开发的一种引起极大兴趣的技术,它能够通过输入文本提示生成高度准确的图像。稳定扩散主要使用LAION-5B数据集的英语子集LAION2B-en作为其训练数据,因此需要输入英语文本提示,生成的图像往往更加西方化。
株式会社rinna开发了一种名为“日本稳定扩散”的特定于日本文本到图像模型,通过在稳定扩散上进行日语标题图像的微调来实现。日本稳定扩散接受日语文本提示,并生成反映日本语言世界文化的图像,这可能难以通过翻译来表达。
在本博客中,我们将讨论日本稳定扩散开发的背景及其学习方法。日本稳定扩散可以在Hugging Face和GitHub上找到。代码基于🧨扩散器(Diffusers)。
- Hugging Face模型卡片:https://huggingface.co/rinna/japanese-stable-diffusion
- Hugging Face Spaces:https://huggingface.co/spaces/rinna/japanese-stable-diffusion
- GitHub:https://github.com/rinnakk/japanese-stable-diffusion
稳定扩散
最近,扩散模型在人工合成方面被证明比生成对抗网络(GANs)更有效。Hugging Face在以下文章中解释了扩散模型的工作原理:
- 批注扩散模型
- 开始使用🧨扩散器
一般来说,文本到图像模型由文本编码器和生成模型组成。文本编码器解释文本,生成模型根据其输出生成图像。
稳定扩散使用OpenAI的CLIP作为其文本编码器,使用改进版扩散模型作为生成模型。稳定扩散主要在LAION-5B的英语子集上进行训练,可以通过输入文本提示生成高性能的图像。除了性能优异,稳定扩散还易于使用,推理过程的计算成本约为10GB的VRAM GPU。

来自稳定扩散与🧨扩散器
日本稳定扩散
为什么我们需要日本稳定扩散?
稳定扩散不仅在质量上而且在计算成本上都是非常强大的文本到图像模型。由于稳定扩散是在英语数据集上训练的,需要先将非英语提示翻译成英语。令人惊讶的是,稳定扩散有时候甚至在使用非英语提示时也能生成合适的图像。
那么,为什么我们需要一种特定语言的稳定扩散?答案是因为我们希望有一种理解日本文化、身份和独特表达方式(包括俚语)的文本到图像模型。例如,从英语单词“businessman”重新解释而来的日语术语之一是“salary man”,我们通常会将其想象成穿着西装的男性。稳定扩散无法正确理解这种日本特有的词汇,因为日本不是它们的目标。

来自原始稳定扩散的“salary man, oil painting”
因此,我们开发了一种特定语言版本的稳定扩散。与原始稳定扩散相比,日本稳定扩散可以实现以下几点:
- 生成日本风格的图像
- 理解从英语中衍生出的日本词汇
- 理解日本特有的拟声词
- 理解日本专有名词
训练数据
我们使用了大约1亿张带有日语字幕的图像,其中包括LAION-5B的日语子集。此外,为了去除质量低下的样本,我们使用了株式会社rinna发布的日语cloob-vit-b-16作为预处理步骤,去除了得分低于一定阈值的样本。
培训细节
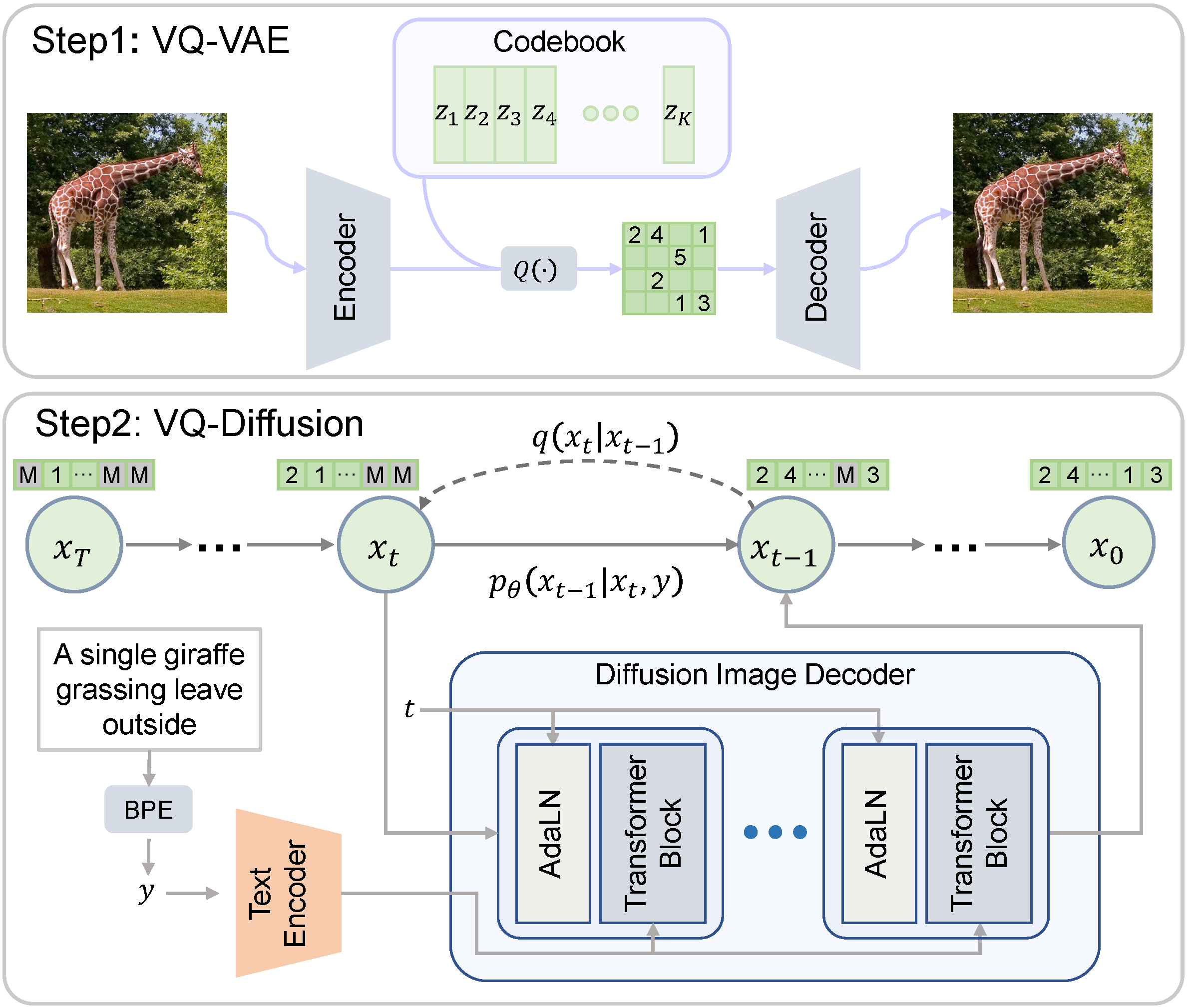
制作一个针对日本特定文本到图像模型的最大挑战是数据集的大小。非英语数据集比英语数据集要小得多,这导致基于深度学习的模型性能下降。用于训练日本稳定扩散的数据集的大小是用于稳定扩散训练的数据集的1/20。为了在这样一个小的数据集上建立一个好的模型,我们对在英语数据集上训练的强大的稳定扩散进行了微调,而不是从头开始训练一个文本到图像模型。
为了制作一个好的语言特定的文本到图像模型,我们不仅仅进行了微调,还应用了 PITI 的2个训练阶段。
第一阶段:训练一个日本特定的文本编码器
在第一阶段,潜在扩散模型被固定,我们将英语文本编码器替换为一个训练好的日本特定的文本编码器。此时,我们使用日文 sentencepiece 分词器作为分词器。如果直接使用 CLIP 分词器,日文文本会被分词为字节,这使得学习令牌依赖关系变得困难,并且令牌数量变得不必要地大。例如,如果我们将 “サラリーマン 油絵” 进行分词,得到的结果是 ['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>'],这是无法解释的令牌。
from transformers import CLIPTokenizer
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text = "サラリーマン 油絵"
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵另一方面,通过使用我们的日本分词器,提示被分割成可以解释的令牌,并且令牌数量减少。例如,”サラリーマン 油絵” 可以被分词为 ['▁', 'サラリーマン', '▁', '油', '絵'],这是正确的日文分词。
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-stable-diffusion", subfolder="tokenizer", use_auth_token=True)
tokenizer.do_lower_case = True
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['▁', 'サラリーマン', '▁', '油', '絵']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵这个阶段使得模型能够理解日文提示,但仍然不能输出日本风格的图像,因为潜在扩散模型完全没有改变。换句话说,日文词汇 “salary man” 可以被解释为英文词汇 “businessman”,但生成的结果是一个带有西方面孔的商人,如下图所示。

“サラリーマン 油絵”,即 “salary man, oil painting”,来自第一阶段的日本稳定扩散
因此,在第二阶段,我们训练模型以输出更多日本风格的图像。
第二阶段:微调文本编码器和潜在扩散模型
在第二阶段,我们将同时训练文本编码器和潜在扩散模型以生成日本风格的图像。这个阶段对于使模型成为更具语言特定性的模型至关重要。在此之后,模型最终可以生成一个带有日本面孔的商人,如下图所示。

“サラリーマン 油絵”,意思是”上班族,油画”,来自第二阶段的日本稳定扩散
rinna的开放战略
许多研究机构都发布了基于人工智能民主化理念的研究成果,旨在实现任何人都能轻松使用人工智能的世界。特别是最近,基于大规模训练数据的具有大量参数的预训练模型已成为主流,对于拥有计算资源的研究机构垄断高性能人工智能的担忧也日益增多。不过,令人庆幸的是,许多预训练模型已经发布并对人工智能技术的发展做出了贡献。然而,文本上的预训练模型通常针对英语,这是世界上最流行的语言。对于一个任何人都能轻松使用人工智能的世界,我们认为能够在除了英语之外的其他语言中使用最先进的人工智能是理想的。
因此,rinna公司已经发布了专门针对日语的GPT、BERT和CLIP,现在也发布了日本稳定扩散。通过发布专门针对日语的预训练模型,我们希望制造出的人工智能不仅不偏向英语世界的文化,还能融入日语世界的文化。让它面向所有人将有助于民主化保证日本文化身份的人工智能。
接下来是什么?
与稳定扩散相比,日本稳定扩散的适用性不如前者,仍然存在一些准确性问题。然而,通过开发和发布日本稳定扩散,我们希望向研究界传达语言特定模型开发的重要性和潜力。
rinna公司已经为日语文本发布了GPT和BERT模型,以及CLIP、CLOOB和日本稳定扩散模型,适用于日语文本和图像。我们将继续改进这些模型,下一步将考虑发布基于自监督学习专门针对日语语音的模型。