使用Mask2Former和OneFormer进行通用图像分割
Use Mask2Former and OneFormer for general image segmentation.
本指南介绍了Mask2Former和OneFormer,这是两个用于图像分割的最先进的神经网络。这些模型现在可以在🤗 transformers开源库中使用,该库提供了最先进模型的易于使用的实现。在学习过程中,您将了解各种形式的图像分割之间的区别。
图像分割
图像分割是识别图像中不同“段”(如人或汽车)的任务。从技术上讲,图像分割是将具有不同语义的像素分组的任务。请参考Hugging Face任务页面的简要介绍。
图像分割可以大致分为3个子任务 – 实例分割、语义分割和全景分割,并有许多方法和模型架构来执行每个子任务。
- 实例分割是识别图像中不同“实例”(如单个人)的任务。实例分割与目标检测非常相似,只是我们希望输出一组二进制分割掩码,而不是边界框,并附带类别标签。实例通常也称为“对象”或“物体”。请注意,单个实例可能会重叠。
- 语义分割是识别图像中每个像素的不同“语义类别”(如“人”或“天空”)的任务。与实例分割相反,不区分给定语义类别的各个实例;只需为“人”类别创建一个掩码,而不是为各个人创建掩码。通常将没有单独实例的语义类别(如“天空”或“草地”)称为“物体”以与“物体”进行区分(好名字,对吧?)。请注意,不可能存在语义类别之间的重叠,因为每个像素属于一个类别。
- 全景分割,由Kirillov等人于2018年提出,旨在通过使模型简单地识别一组具有相应二进制掩码和类别标签的“段”来统一实例和语义分割。段既可以是“物体”也可以是“物体”。与实例分割不同,不同段之间不可能重叠。
下图说明了这3个子任务之间的区别(源自这篇博文)。

在过去的几年中,研究人员提出了几种通常非常针对实例、语义或全景分割的架构。实例和全景分割通常通过输出一组对象实例的二进制掩码+相应标签来解决(与目标检测非常相似,只是每个实例输出一个二进制掩码而不是边界框)。这通常称为“二进制掩码分类”。另一方面,语义分割通常通过使模型输出一个具有每个像素的标签的单个“分割地图”来解决。因此,语义分割被视为“逐像素分类”问题。采用这种范式的流行语义分割模型包括SegFormer和UPerNet,我们在一篇详尽的博文中对它们进行了介绍。
通用图像分割
幸运的是,从2020年开始,人们开始提出可以使用统一架构解决所有3个任务(实例、语义和全景分割)的模型,采用相同的范式。这始于DETR,它是第一个使用“二进制掩码分类”范式解决全景分割的模型,通过以统一方式处理“物体”和“物体”类别。关键创新是使用Transformer解码器并行生成一组二进制掩码+类别。然后,在MaskFormer论文中进行了改进,表明“二进制掩码分类”范式对于语义分割也非常有效。
Mask2Former通过进一步改进神经网络架构将其扩展到实例分割。因此,我们已经从单独的架构发展到研究人员现在称之为“通用图像分割”架构的模型,能够解决任何图像分割任务。有趣的是,这些通用模型都采用“掩码分类”范式,完全放弃了“逐像素分类”范式。下图显示了Mask2Former的架构(来自原始论文)。
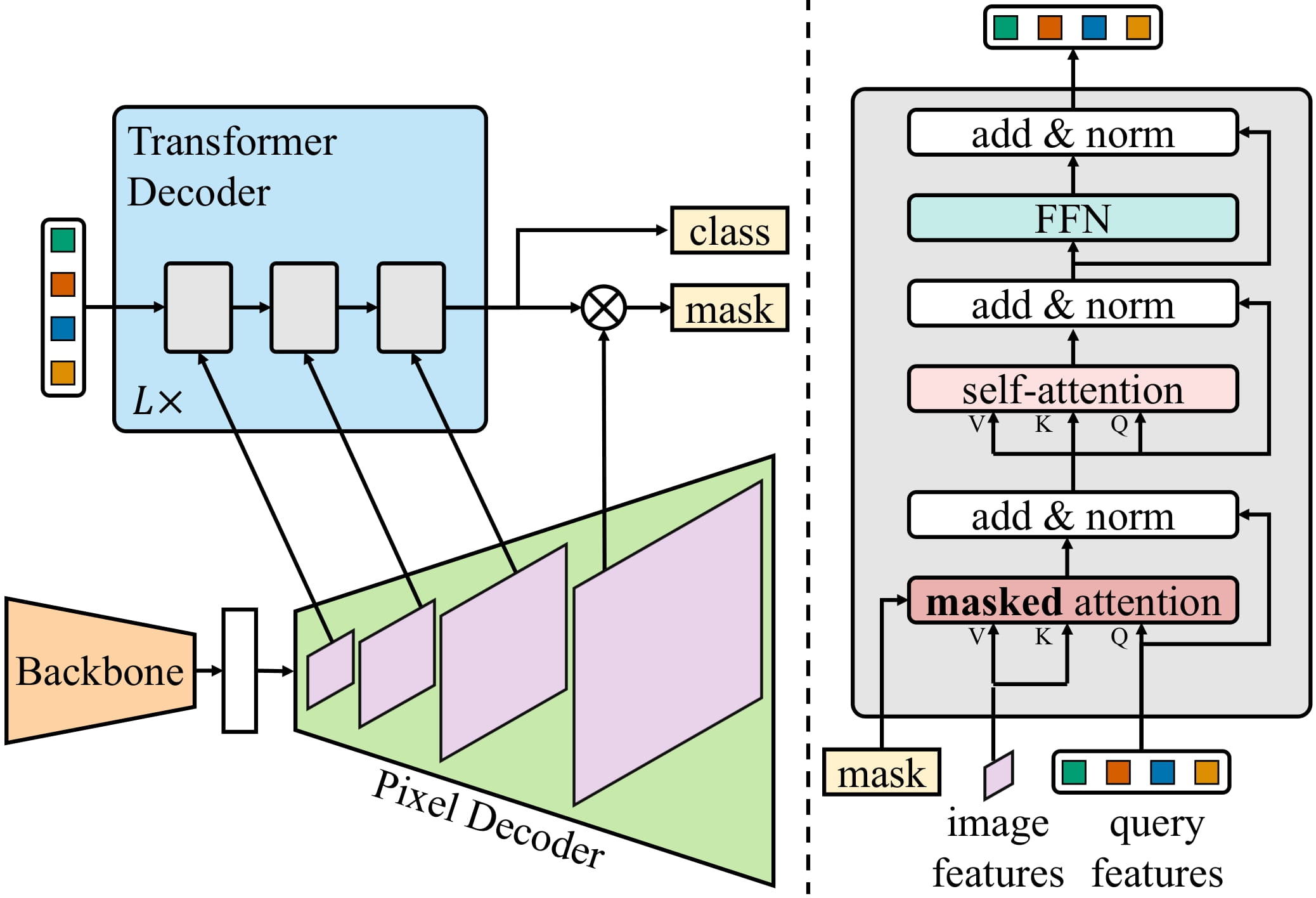
简而言之,首先将图像通过主干网络(可以是ResNet或Swin Transformer)发送,以获取低分辨率特征图的列表。接下来,使用像素解码器模块增强这些特征图以获取高分辨率特征。最后,Transformer解码器接收一组查询并将其转换为一组二进制掩码和类别预测,条件是像素解码器的特征。
请注意,Mask2Former仍然需要单独对每个任务进行训练,以获得最先进的结果。这一点已经通过OneFormer模型得到改进,该模型通过仅在数据集的全景版本上进行训练(!),通过添加文本编码器来使模型在“实例”、“语义”或“全景”输入上进行条件化,从而在所有3个任务上获得最先进的性能。该模型截至今天也已经在🤗transformers中可用。它比Mask2Former更准确,但由于额外的文本编码器而具有更大的延迟。请参见下面的图,了解OneFormer的概述。它使用Swin Transformer或新的DiNAT模型作为骨干。

在Transformers中使用Mask2Former和OneFormer进行推理
使用Mask2Former和OneFormer非常简单,非常类似于它们的前身MaskFormer。让我们从hub上实例化一个在COCO全景数据集上训练的Mask2Former模型,以及它的processor。请注意,作者发布了不少于30个在各种数据集上训练的检查点。
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")接下来,让我们加载来自COCO数据集的熟悉的猫图片,我们将在其上执行推理。
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
我们使用图像处理器为模型准备图像,并将其传递给模型。
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)模型输出一组二进制掩码和对应的类别logits。可以使用图像处理器对Mask2Former的原始输出进行后处理,以获得最终的实例、语义或全景分割预测:
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())在全景分割中,最终的prediction包含两个部分:一个形状为(高度,宽度)的segmentation映射,其中每个值都编码了给定像素的实例ID,以及相应的segments_info。segments_info包含有关映射的各个部分的更多信息(例如它们的类别ID)。请注意,为了效率,Mask2Former输出形状为(96, 96)的二进制掩码提案,并使用target_sizes参数将最终掩码调整为原始图像的大小。
让我们可视化结果:
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# 获取使用的颜色映射
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# 对于每个部分,绘制其图例
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)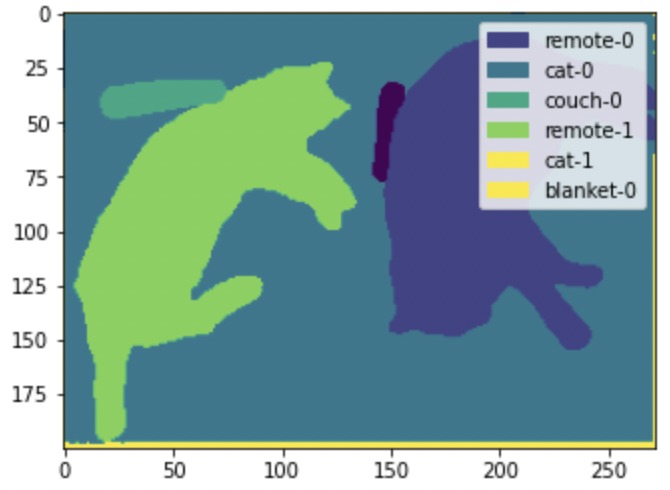
在这里,我们可以看到模型能够检测到图像中的单个猫和遥控器。另一方面,语义分割只会为“猫”类别创建一个单一的掩码。
要使用OneFormer进行推断,其API与MaskFormer完全相同,只是它还需要额外的文本提示作为输入,我们可以参考演示笔记本。
在Transformers中对Mask2Former和OneFormer进行微调
要对Mask2Former/OneFormer在自定义数据集上进行微调,无论是实例、语义还是全景分割,请查看我们的演示笔记本。MaskFormer、Mask2Former和OneFormer具有相似的API,因此从MaskFormer升级到它们非常容易,只需要进行最小的更改。
演示笔记本使用MaskFormerForInstanceSegmentation来加载模型,而您需要切换到使用Mask2FormerForUniversalSegmentation或OneFormerForUniversalSegmentation。在进行Mask2Former的图像处理时,您还需要切换到使用Mask2FormerImageProcessor。您还可以使用AutoImageProcessor类加载图像处理器,它会自动加载与您的模型相对应的正确处理器。另一方面,OneFormer需要一个OneFormerProcessor,它为模型准备图像和文本输入。
就是这样!您现在了解了实例、语义和全景分割之间的区别,以及如何使用Mask2Former和OneFormer这样的“通用架构”,使用🤗 transformers库。
我们希望您喜欢这篇文章并从中学到了东西。如果在微调Mask2Former或OneFormer时对结果满意,请随时告诉我们。
如果您喜欢这个主题并想要了解更多,我们推荐以下资源:
- 我们的MaskFormer、Mask2Former和OneFormer的演示笔记本,它们对推断(包括可视化)以及在自定义数据上进行微调提供了更广泛的概述。
- Mask2Former和OneFormer在Hugging Face Hub上提供的[在线演示空间],您可以使用它们来快速尝试对样本输入进行模型测试。






