Google DeepMind研究人员介绍了SynJax:一种用于JAX结构化概率分布的深度学习库
Google DeepMind研究人员介绍了SynJax:一种深度学习库


数据可以被视为在各个领域中具有结构,解释了其组成部分如何组合成一个更大的整体。根据活动的不同,这种结构通常是潜在的并且会发生变化。请参考图1,了解自然语言中不同结构的示例。这些单词一起组成了一个序列。序列中的每个单词都有一个词性标签。这些标签是相互连接的,生成了红色的线性链。通过将句子分割成泡泡,可以将句子中的单词组成小的、不连续的连续聚类。对语言的更深入的研究会发现,可以递归地创建组,从而创建一个句法树结构。结构也可以连接两种语言。
例如,同一张图片中的对齐可以将日语翻译与英语源连接起来。这些语法结构是普遍存在的。在生物学中,也可以找到类似的结构。基于树的RNA模型捕捉了蛋白质折叠过程的分层特性,而单调对齐用于匹配RNA序列中的核苷酸。基因组数据也被分成连续的组。大多数当前的深度学习模型没有明确地尝试表示中间结构,而是直接从输入预测输出变量。这些模型可以通过明确建模结构来获得多种好处。使用适当的归纳偏差可以促进更好的泛化。这将提高下游性能以及样本效率。

显式结构建模可以包含特定问题的一组限制或方法。由于离散结构的存在,模型的判断也更容易理解。最后,有时结构本身是学习的结果。例如,它们可能意识到数据由某种形状的隐藏结构解释,但它们需要更多了解。对于建模序列,自回归模型是主要的技术。在某些情况下,非序列结构可以线性化,并由序列结构代理。这些模型很强大,因为它们不依赖于独立的假设,并且可以使用大量数据进行训练。尽管确定理想的结构或对隐藏变量进行边际化是常见的推断问题,但从自回归模型中采样通常是不可追踪的。
在大规模模型中使用自回归模型是具有挑战性的,因为它们需要偏差或高方差的近似方法,而这些方法通常会带来计算成本。与自回归模型相比,具有与目标结构相同因子分解方式的因子图模型是一种替代方法。这些模型可以通过使用专门的方法准确高效地计算所有有趣的推断问题。尽管每种结构都需要独特的方法,但每个推断任务并不需要专门的算法(argmax、采样、边际、熵等)。为了从每种结构类型的一个函数中提取多个数字,SynJax使用自动微分,正如他们之后将要展示的那样。
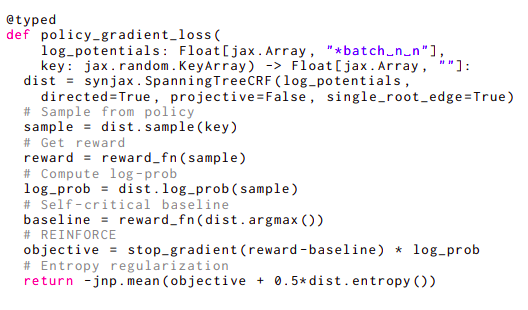
缺乏提供加速器友好的结构组件实现的实用库已经减缓了对深度理解的结构分布的研究,特别是因为这些组件依赖于通常无法直接映射到可用的深度学习原语的算法,而不像Transformer模型。来自Google Deepmind的研究人员提供了易于使用的结构原语,这些原语在JAX机器学习框架内相互结合,帮助SynJax解决这一挑战。请参考图2中的示例,演示了使用SynJax的简单性。这段代码实现了一个策略梯度损失,需要计算多个参数,包括采样、argmax、熵和对数概率,每个参数都需要一个单独的方法。
在这段代码中,结构是一个非投影有向生成树,具有单根边限制。因此,SynJax将使用dist.sample() Wilson的采样方法用于单根树,dist.entropy()和Tarjan的最大生成树算法用于单根边树。单根边树可以使用Matrix-Tree定理。只需要更改一个标志,SynJax就可以使用完全不同的算法,这些算法适用于该结构-argmax的Kuhlmann算法和Eisner算法的各种迭代,以略微改变树的类型,强制树遵循用户的投射性约束。因为SynJax处理与这些算法相关的一切,用户可以专注于模型问题的方面,而无需实现它们甚至了解它们的工作原理。