在3D中工作的神奇画笔:Blended-NeRF是一种在神经辐射场中进行零样本物体生成的AI模型
Blended-NeRF是一种在3D中工作的神奇画笔,可在神经辐射场中进行零样本物体生成的AI模型


最近几年对各个学科来说都充满了启发性的时刻。我们见证了一些革命性的方法的出现,带来了巨大的进步。ChatGPT是语言模型的一次突破,稳定扩散是生成模型的一次突破,神经辐射场(NeRF)是计算机图形学和视觉的一次突破。
NeRF作为一种开创性的技术出现,彻底改变了我们表示和渲染3D场景的方式。NeRF将场景表示为连续的3D体积,编码几何和外观信息。与传统的显式表示不同,NeRF通过神经网络捕捉场景的属性,允许合成新视图和精确重建复杂场景。通过模拟场景中每个点的体积密度和颜色,NeRF实现了令人印象深刻的逼真度和细节保真度。
NeRF的多功能性和潜力引发了广泛的研究努力,以增强其能力并解决其局限性。已经提出了加速NeRF推断、处理动态场景和实现场景编辑的技术,进一步扩展了这种新颖表示的适用性和影响力。
尽管所有这些努力,NeRF仍然存在一些限制,阻碍了它在实际场景中的适应性。编辑NeRF场景就是其中最重要的例子之一。由于NeRF的隐式性质和不同场景组件之间缺乏明确的区分,这是一个具有挑战性的任务。
与提供显式表示(如网格)的其他方法不同,NeRF不提供形状、颜色和材料之间的明确区分。此外,将新对象混合到NeRF场景中需要在多个视图之间保持一致性,进一步复杂化了编辑过程。
能够捕捉3D场景只是方程的一部分。能够编辑输出同样重要。数字图像和视频之所以强大,是因为我们可以相对容易地对它们进行编辑,尤其是使用最近的文本到X AI模型,可以轻松进行编辑。那么,我们如何将这种能力带到NeRF场景中呢?是时候见识一下混合NeRF了。
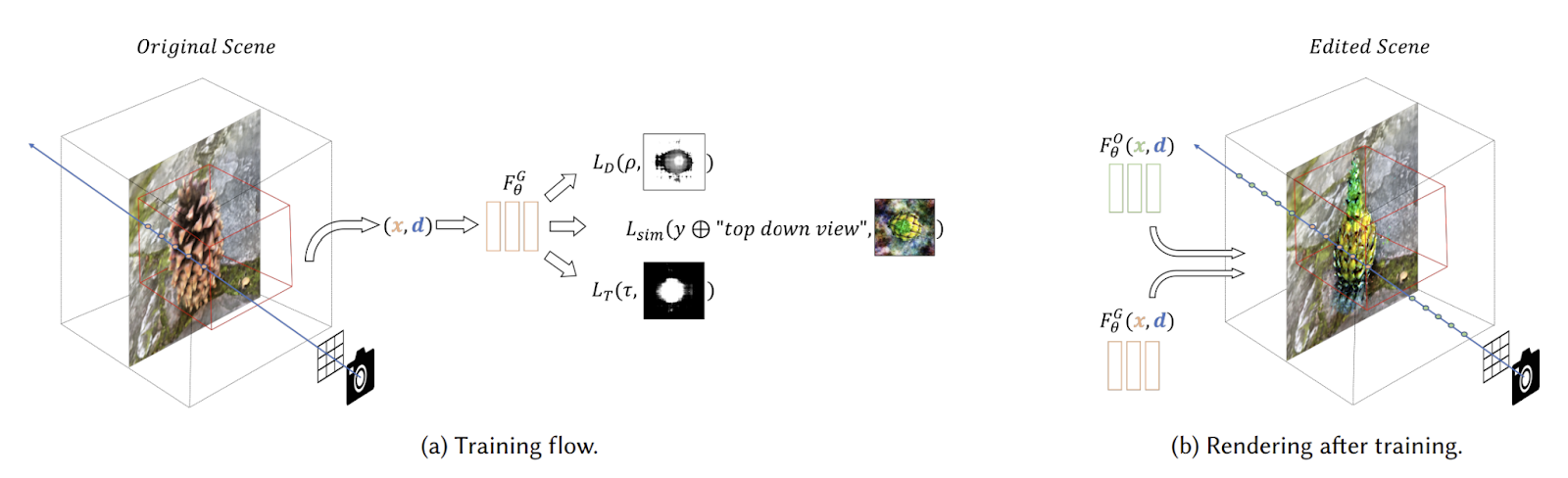
混合NeRF是一种以文本提示或图像补丁为指导的ROI(感兴趣区域)编辑NeRF场景的方法。它允许编辑现实场景的任何区域,同时保留其余场景,而无需新的特征空间或二维蒙版集。
目标是生成看起来自然且与现有场景无缝融合的结果。更重要的是,混合NeRF不限于特定的类别或领域,并且能够进行复杂的文本引导操作,如对象插入/替换、对象混合和纹理转换。
实现所有这些功能并不容易。这就是为什么混合NeRF利用预训练的语言-图像模型(如CLIP)和在现有NeRF场景上初始化的NeRF模型作为生成器,用于将新对象合成和混合到场景的感兴趣区域(ROI)中。
CLIP模型根据用户提供的文本提示或图像补丁引导生成过程,实现与场景自然融合的多样化3D对象的生成。为了在保留其余场景的同时实现一般的局部编辑,向用户呈现了一个简单的GUI,用于在NeRF场景中定位一个3D框,利用深度信息进行直观反馈。为了实现无缝融合,提出了一种新颖的距离平滑操作,通过混合每个摄像机射线上采样的3D点来合并原始和合成的辐射场。
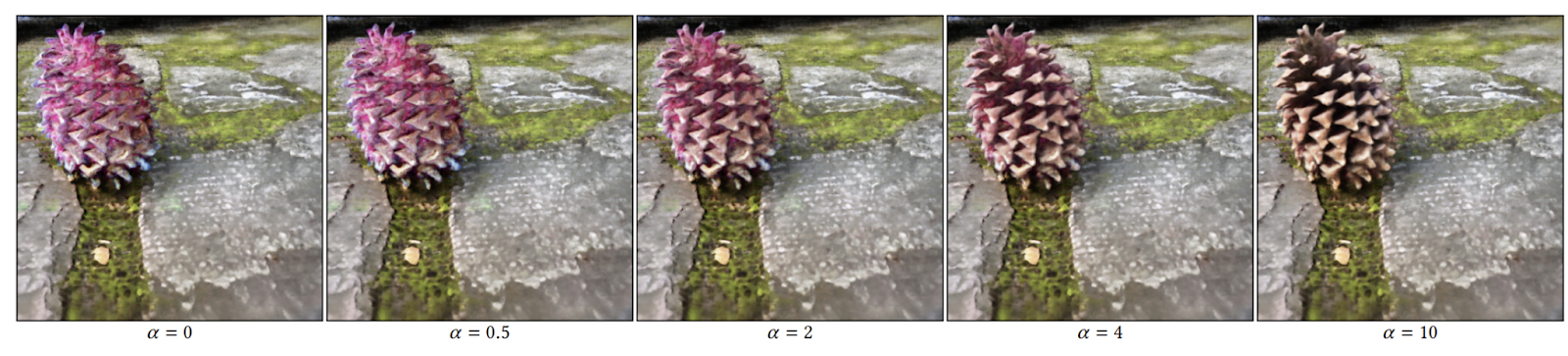
然而,还有一个问题。使用这个流水线来编辑NeRF场景会产生质量低、不连贯和不一致的结果。为了解决这个问题,《混合-NeRF》的研究者们结合了之前的工作中提出的增强和先验知识,例如深度正则化、姿态采样和方向相关提示,以实现更逼真和连贯的结果。





