平衡行为:解决推荐系统中的流行度偏差
Balancing Behavior Addressing Popularity Bias in Recommender Systems
一天早上你醒来,决定给自己买一双新鞋。你上了你最喜欢的运动鞋网站,浏览了推荐给你的鞋子。其中一双鞋特别吸引你的眼球 —— 你喜欢它的款式和设计。你毫不犹豫地买下了它们,兴奋地准备穿上新鞋。
当鞋子到了之后,你迫不及待地想要展示它们。你决定在即将参加的音乐会上穿上它们。然而,当你到达场馆时,你注意到至少有10个人穿着完全相同的鞋子!这是多大的几率呢?
突然间,你感到失望。尽管你最初喜欢这双鞋子,但看到这么多人都有同样的鞋子,让你觉得你的购买并不那么特别。你原以为这双鞋子会让你与众不同,结果却让你融入了大众。
就在那一刻,你发誓再也不从那个运动鞋网站购买了。尽管他们的推荐算法给出了你喜欢的物品,但最终并没有给你带来满足感和独特性。所以,尽管你最初欣赏推荐的物品,整体的体验却让你不开心。
这凸显了推荐系统的局限性 —— 推荐一个“好”的产品并不能保证它会给顾客带来积极和满足的体验。所以,这真的是一个好的推荐吗?
为什么测量推荐系统中的流行度偏差很重要?
流行度偏差发生在推荐系统推荐许多全球热门物品而不是个性化选择的情况下。这是因为算法通常通过推荐许多用户喜欢的内容来最大化参与度。
虽然热门物品仍然可能是相关的,但过于依赖流行度会导致个性化不足。推荐变得普遍化,无法考虑个人兴趣。许多推荐算法使用奖励整体流行度的指标进行优化。这种对已经受欢迎的内容的系统偏好随着时间的推移可能会导致问题。它导致过度推广正在流行或病毒式的物品,而不是独特的建议。对于企业而言,流行度偏差还可能导致一种情况,即公司拥有大量无法被用户发现的小众、鲜为人知的物品,使它们难以销售。
个性化推荐可以考虑到特定用户的喜好,为用户带来巨大的价值,尤其是对于与主流不同的小众兴趣。它们可以帮助用户发现专门为他们量身定制的新奇物品。
理想情况下,在推荐系统中应该在流行度和个性化之间取得平衡。目标应该是展示与每个用户共鸣的隐藏宝石,同时不时地添加普遍吸引人的内容。
如何测量流行度偏差?
平均推荐流行度
平均推荐流行度(ARP)是用于评估推荐列表中推荐物品流行度的指标。它根据训练集中这些物品收到的评分数量计算物品的平均流行度。从数学上讲,ARP的计算如下:

其中:
- |U_t| 是用户数量
- |L_u| 是针对用户u的推荐列表L_u中的物品数量。
- ϕ(i) 是“物品i”在训练集中被评分的次数。
简单来说,ARP通过将推荐列表中所有物品的流行度(评分数量)相加,然后在测试集中的所有用户上平均流行度,来衡量推荐列表中物品的平均流行度。
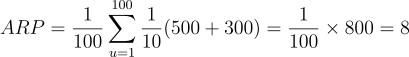
示例:假设我们有一个包含100个用户的测试集,|U_t| = 100。对于每个用户,我们提供一个包含10个物品的推荐列表,|L_u| = 10。如果物品A在训练集中被评分了500次(ϕ(A) = 500),物品B被评分了300次(ϕ(B) = 300),那么这些推荐的ARP可以计算如下:
在这个例子中,ARP值为8,表示根据训练集中的评分数量,推荐物品的平均受欢迎程度为8。
长尾物品的平均比例(APLT)
长尾物品的平均比例(APLT)指标计算推荐列表中长尾物品的平均比例。其表示为:

这里:
- |Ut| 表示用户总数。
- u ∈ Ut 表示每个用户。
- Lu 表示用户u的推荐列表。
- Γ 表示长尾物品集合。
简单来说,APLT量化了推荐给用户的物品中不太受欢迎或利基的物品的平均比例。较高的APLT表示推荐中包含更多这样的长尾物品。
例子:假设有100个用户(|Ut| = 100)。对于每个用户的推荐列表,平均而言,50个物品中的20个物品(|Lu| = 50)属于长尾集合(Γ)。使用公式,APLT为:
APLT = Σ (20 / 50) / 100 = 0.4
因此,在这种情况下,APLT为0.4或40%,表示平均而言,推荐列表中的40%物品来自长尾集合。
长尾物品的平均覆盖率(ACLT)
长尾物品的平均覆盖率(ACLT)指标评估了长尾物品在整体推荐中的比例。与APLT不同,ACLT考虑了长尾物品在所有用户中的覆盖率,并评估这些物品在推荐中的有效表示。ACLT的定义如下:
ACLT = Σ Σ 1(i ∈ Γ) / |Ut| / |Lu|
这里:
- |Ut| 表示用户总数。
- u ∈ Ut 表示每个用户。
- Lu 表示用户u的推荐列表。
- Γ 表示长尾物品集合。
- 1(i ∈ Γ) 是一个指示函数,如果物品i在长尾集合Γ中,则等于1,否则等于0。
简单来说,ACLT计算了每个用户推荐中长尾物品的平均比例。
例子:假设有100个用户(|Ut| = 100)和总共500个长尾物品(|Γ| = 500)。在所有用户的推荐列表中,有150个长尾物品被推荐(Σ Σ 1(i ∈ Γ) = 150)。所有推荐列表中的物品总数为3000(Σ |Lu| = 3000)。使用公式,ACLT为:
ACLT = 150 / 100 / 3000 = 0.0005
因此,在这种情况下,ACLT为0.0005或0.05%,表示平均而言,长尾物品中的0.05%在整体推荐中被覆盖。该指标有助于评估推荐系统中利基物品的覆盖率。
如何减少推荐系统中的流行度偏差
流行度感知学习
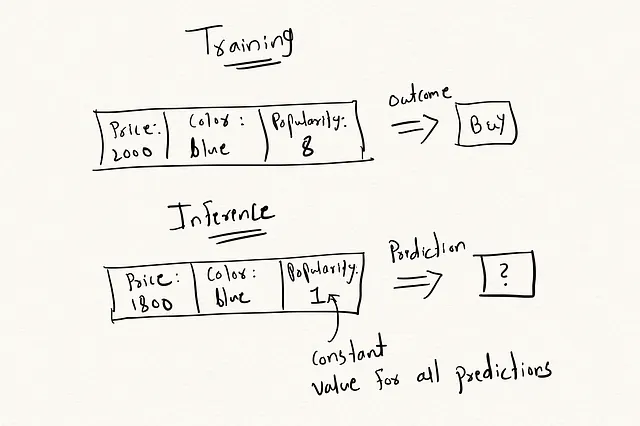
这个想法受到了位置感知学习(PAL)的启发,其中的方法是同时优化排名相关性和位置影响。我们可以将相同的方法应用于流行度得分,这个得分可以是上述提到的任何得分,比如平均推荐流行度。
- 在训练阶段,将物品流行度作为其中一个输入特征。
- 在预测阶段,用一个常数值替换它。
xQUAD框架
修复流行度偏差的一个有趣方法是使用称为xQUAD框架的东西。它使用来自当前模型的长列表的推荐(R)以及概率/可能性分数,并构建一个更多样化的新列表(S),其中|S| < |R|。这个新列表的多样性由超参数λ控制。
我试图包装框架的逻辑:

我们为集合R中的所有文档计算一个分数。我们选择具有最大分数的文档并将其添加到集合S,同时从集合R中删除它。


要选择要添加到“S”的下一个项目,我们计算R\S(R排除S)中每个项目的分数。对于每个选择添加到“S”的项目,P(v/u)增加,因此再次选择非流行项目的机会也增加。
参考文献
https://arxiv.org/pdf/1901.07555.pdf
https://www.ra.ethz.ch/cdstore/www2010/www/p881.pdf





