深入探究统计期望的科学

我们如何期待某件事情,期待任何事情意味着什么,以及产生含义的数学。
1988年夏天,我第一次踏上了船。那是从英格兰的多佛到法国的加来的一艘客运渡轮。那时我并不知道,我正赶上渡海黄金时期的尾巴。这是在廉价航空公司和海峡隧道几乎破坏了我仍然认为是最好的旅行方式之前。
我期待渡轮看起来像我在儿童读物中看到的许多船只之一。但实际上,我看到的是一座不可思议的巨大的,闪闪发光的白色摩天大楼,有小小的正方形窗户。而且,这座摩天大楼似乎因为某种令人困惑的原因而侧倒着休息。从码头上的视角,我看不到船体和烟囱。我看到的只是它长长的,扁平的,窗户饱满的外观。我看到了一座横向的摩天大楼。
回想起来,用统计的语言重新描述我的经历很有趣。我的大脑从我看到的船只图片的数据样本中计算出了渡轮的预期形状。但我的样本在人群中希望很小,平均数同样不具有代表性。我试图使用高度有偏见的样本平均值来解码现实。
晕船
这次穿越海峡的旅行也是我第一次晕船。人们说,当你晕船时,你应该走到甲板上,吸入新鲜,凉爽的海风,凝视地平线。唯一真正对我有效的方法是坐下来,闭上眼睛,慢慢地喝我的最爱苏打水,直到我的思维慢慢离开我的胃翻滚的令人痛苦的恶心感。顺便说一下,我并没有从本文的主题中慢慢游离开。我一会儿就会进入统计学。同时,让我解释一下为什么你在船上会生病,这样你就会看到与手头的主题有关的联系。
- 2023年最佳的7款人工智能绘画生成器
- 技术艺术家本周使用 NVIDIA Omniverse USD Composer 建造了伟大的毛象,在“NVIDIA Studio”中呈现
- 成功的离岸定制软件开发最佳实践
在你生命中的大多数日子里,你并没有在船上晃动。在陆地上,当你将身体倾斜到一侧时,你的内耳和身体的每个肌肉都告诉你的大脑你正在向一侧倾斜。是的,你的肌肉也在与你的大脑交流!你的眼睛也会热切地对这一反馈进行确认,你最终会感觉良好。但是在船上,眼睛和耳朵之间友好的协议全都混乱了。
在船上,当海洋使船倾斜,摇晃,摇摆,滚动,漂移,或任何其他事情时,你的眼睛告诉你的大脑可能与你的肌肉和内耳告诉你的大脑有着显着的不同。你的内耳可能会说:“小心!你正在向左倾斜。你应该调整你对世界出现的期望值。”但你的眼睛则说:“胡说八道!我坐在的桌子看起来对我来说非常平稳,上面放着的食物盘子也是如此。墙上的那幅尖叫的东西的照片看起来也是直的和平稳的。不要听耳朵的话。”

你的眼睛可能向你的大脑报告更加混乱的信息,比如“是的,你确实倾斜了。但是,这种倾斜不像你过度热衷的内耳所导致的那么显着或迅速。”
仿佛你的眼睛和内耳各自要求你的大脑创建两个不同的期望,即你的世界即将如何改变。你的大脑显然不能做到这一点。它会感到困惑。出于进化的原因,你的胃表达了强烈的排空愿望。
让我们尝试使用统计推理的框架来解释这种可怜的情况。这一次,我们将使用一些数学来辅助解释。
你是否应该期望晕船?深入了解晕船的统计数据
让我们定义一个随机变量 X,它取两个值:0和1。如果来自你的眼睛的信号不与来自你的内耳的信号一致,那么X为0。如果它们一致,则X为1:

理论上,每个X值都应该携带某个概率P(X=x)。概率P(X=0)和P(X=1)共同构成了X的概率质量函数。我们将其陈述如下:
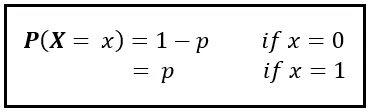
在绝大多数情况下,你的眼睛的信号将与你的内耳的信号一致。因此,p几乎等于1,而(1- p)是一个非常非常小的数字。
让我们大胆猜测(1- p)的值。我们将使用以下推理来得出估计值:根据联合国的数据,2023年人类出生时的平均寿命约为73岁。以秒为单位,相当于2302128000(约为23亿)。假设一个普通人在其一生中晕船的时间为16个小时,即28800秒。现在让我们不要为16小时争论。记住这是一个大胆的猜测。因此,28800秒为我们提供了(1-p)的工作估计值,即28000/2302128000 = 0.0000121626,p =(1-0.0000121626)= 0.9999878374。因此,在普通人的生命中的任何一秒钟,他们经历晕船的无条件概率仅为0.0000121626。
有了这些概率,我们将在某个约翰·多伊(John Doe)的一生中运行持续10亿秒的模拟。这大约是JD模拟生活的50%。 JD更喜欢在坚实的地面上度过大部分时间。他会参加偶尔的海上巡航,他经常会晕船。我们将模拟J在模拟的每个10亿秒内是否会感到晕船。为此,我们将进行1亿次具有p和(1-p)概率的伯努利随机变量的试验。每次试验的结果将是1(如果J晕船)或0(如果J没有晕船)。进行这个实验后,我们将获得10亿个结果。你也可以使用以下Python代码运行此模拟:
import numpy as npp = 0.9999878374num_trials = 1000000000outcomes = np.random.choice([0, 1], size=num_trials, p=[1 - p, p])让我们计算值为1(=不晕船)和0(=晕船)的结果数:
num_outcomes_in_which_not_seasick = sum(outcomes)num_outcomes_in_which_seasick = num_trials - num_outcomes_in_which_not_seasick我们将打印这些计数。当我打印它们时,我得到了以下值。每次运行模拟时,您可能会获得略微不同的结果:
num_outcomes_in_which_not_seasick= 999987794num_outcomes_in_which_seasick= 12206现在,我们可以计算 JD 是否应该在这 10 亿秒中的任何一秒钟内 期望 感到晕船。
期望值是两种可能结果的加权平均值:一和零,权重是两种结果的频率。因此,让我们执行此计算:

预期结果为 0.999987794,几乎是 1.0。数学告诉我们,在 JD 的模拟存在的 10 亿秒钟中的任何随机选择的一秒钟内,JD 不应该期望晕船。数据似乎几乎禁止了它。
现在让我们稍微调整上述公式。我们将从以下方式开始重新排列:

当以这种方式重新排列时,我们看到一个令人愉快的子结构出现。括号中的比率表示与两种结果相关的概率,特别是来自我们 10 亿数据样本的样本概率,而不是总体概率。它们是样本概率,因为我们使用来自 10 亿数据样本的数据计算它们。话虽如此,值 0.999987794 和 0.000012206 应该非常接近 p 和 (1-p) 的总体值。
通过插入概率,我们可以将期望公式重新表述如下:
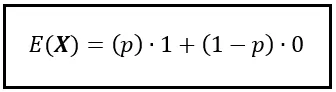
请注意,我们使用了期望的符号,即 E()。由于 X 是 Bernoulli(p) 随机变量,上述公式还向我们展示了如何计算Bernoulli 随机变量的期望值。 X ~ Bernoulli(p) 的期望值仅为 p。
样本均值、总体均值和让您听起来很酷的词汇
E(X) 也称为总体均值,用 μ 表示,因为它使用了概率 p 和 (1-p),这些概率是概率总体级别的值。这些是您将观察到的“真实”概率,如果您可以访问整个值的总体,这几乎是不可能的。统计学家在提到这些和类似措施时使用“渐近”一词。它们称为渐近,因为它们的意义仅当某些东西(例如样本大小)接近无限或整个人口的大小时才有意义。现在有一件事:我认为人们只是喜欢说“渐近”。我也认为这是对于您永远无法测量任何确切价值的麻烦真相的方便掩盖。
好消息是,无法得到人口的不可能性是统计学科中的“伟大的平等者”。无论您是新近毕业的毕业生还是经济学的诺贝尔奖获得者,那扇通向“人口”的大门对您来说都是紧闭的。作为统计学家,您被降职为使用样本,您必须默默忍受其缺点。但情况并没有听起来那么糟糕。想象一下,如果您开始知道事物的确切值。如果您可以访问人口。如果您可以使用准确的命中率计算平均值、中位数和方差。如果您可以用精确的预测未来。将几乎不需要估计任何东西。统计学的许多分支将停止存在。世界将需要数十万少量的统计学家,更不用说数据科学家了。想象一下对失业率、世界经济、世界和平的影响……
但我岔开了话题。我的观点是,如果X是伯努利(p)分布,那么要计算E(X),就不能使用实际的总体值p和(1-p)。相反,你必须使用p和(1-p)的估计值。这些估计值,你将使用一个适中大小的数据样本进行计算,而不是使用整个总体 – 没有机会这样做。因此,非常遗憾地告诉您,您能做到的最好的就是获得随机变量X的期望值的估计值。按照惯例,我们将p的估计值表示为p_hat(p上带有小帽子或帽子),将估计的期望值表示为E_cap(X)。
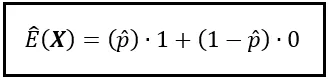
由于E_cap(X)使用样本概率,因此被称为样本均值。它用x̄或’x bar’表示。这是一个带有横杠的x。
总体均值和样本均值是统计学中的“蝙蝠侠”和“罗宾”。
大量的统计学研究致力于计算样本均值,并使用样本均值作为总体均值的估计。
这就是将统计学的广阔领域总结在一句话中的全部内容。😉
深入探讨期望
我们使用伯努利随机变量进行的思想实验在某种程度上揭示了期望的性质。伯努利变量是一个二进制变量,很容易处理。然而,我们经常使用的随机变量可以取许多不同的值。幸运的是,我们可以很容易地将期望的概念和公式扩展到多值随机变量上。让我们用另一个例子来说明。
多值离散随机变量的期望值
下表显示了一个有关205辆汽车的信息数据集的子集。具体来说,该表显示了每辆车发动机内的气缸数。
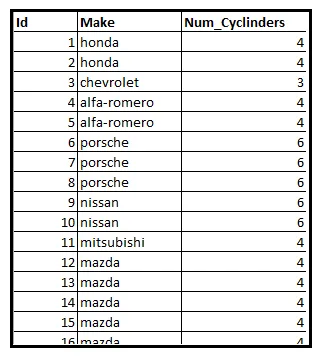
设Y是一个随机变量,包含从该数据集中随机选择的车辆的气缸数。我们碰巧知道该数据集包含气缸数为2、3、4、5、6、8或12的车辆。因此,Y的范围是集合E=[2、3、4、5、6、8、12]。
我们将数据行按气缸数分组。下表显示了分组计数。最后一列表示每个计数的样本出现概率。通过将组大小除以205计算出该概率:
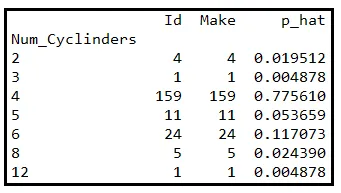
使用样本概率,我们可以构造概率质量函数 P(Y),如果我们将其绘制在Y上,它看起来像这样:
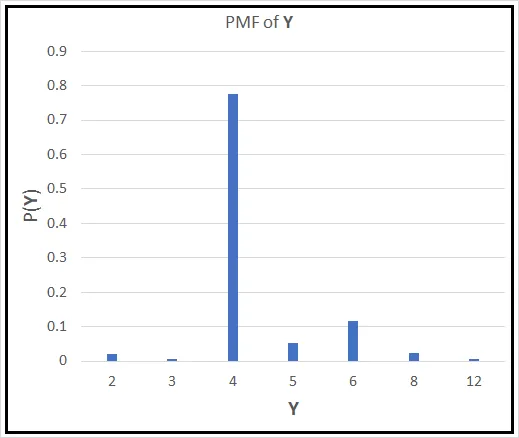
如果你随机选择一辆车,它就在你前面行驶,那么你会期望它的气缸数是多少?仅凭看这个概率质量函数,你会猜测它的气缸数是4。然而,这个猜测背后有着严密的数学支持。和伯努利分布的X一样,你可以通过以下方式计算Y的期望值:
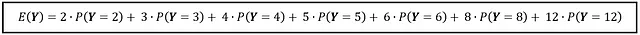
如果你计算这个总和,它会得出4.38049,这个数字非常接近你猜测的4个气缸。
由于Y的范围是集合E= [2,3,4,5,6,8,12],我们可以将这个总和表示为E的求和,如下所示:
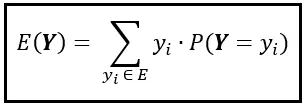
你可以使用上述公式来计算任何离散随机变量的期望值,其范围是集合E。
连续随机变量的期望值
如果你正在处理连续随机变量,情况会有所不同,如下所述。
让我们回到我们的车辆数据集。具体来说,让我们看看车辆的长度:
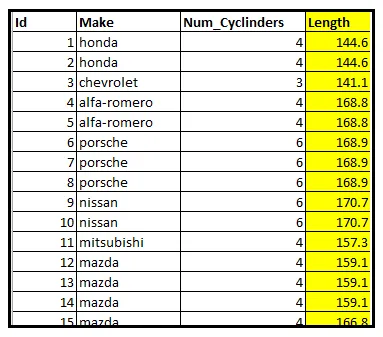
假设Z表示随机选择的车辆的长度(英寸)。Z的范围不再是离散值的集合。相反,它是实数集合ℝ的子集。由于长度始终为正数,它是所有正实数的集合,表示为ℝ >0。
由于所有正实数的集合具有(不可数的)无限个值,因此将概率分配给Z的每个单个值是没有意义的。如果你不相信我,可以进行一个快速的思想实验:想象给Z的每个可能值分配一个正的概率。你会发现这些概率将相加到无限大,这是荒谬的。因此,概率P(Z =z)根本不存在。相反,你必须使用概率密度函数f(Z =z)来对不同的Z值分配概率密度。
我们先前讨论过如何使用概率质量函数计算离散随机变量的期望值。
我们能否将这个公式用于连续随机变量?答案是肯定的。要知道如何做,想象一下你有一个电子显微镜。
将显微镜对准Z的范围,该范围是所有正实数的集合(ℝ >0)。现在,将其放大到一个难以想象的微小区间(z,z+δz]内。在这个微观尺度上,您可能会观察到,出于所有实际目的(现在,这不是一个有帮助的术语吗),概率密度f(Z=z)在δz上是恒定的。因此,f(Z=z)和δz的乘积可以近似于随机选择的车辆长度落在开放-关闭区间(z,z+δz]内的概率。
利用这个近似概率,您可以如下近似Z的期望值:
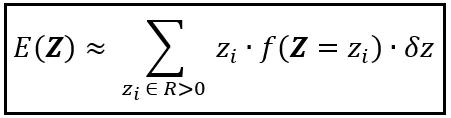
请注意,我们是如何从公式E(Y)到这个近似值的。从E(Y)到E(Z),我们做了以下事情:
- 我们用实值z_i替换了离散的y_i。
- 我们用f(Z=z)δz替换了P(Y=y),它是Y的PMF,是在微观区间(z,z+δz]中找到z的近似概率。
- 我们用连续的无限范围Z(即ℝ >0)代替了离散的有限范围Y,即E。
- 最后,我们用近似符号代替等号。这就是我们的罪过所在。我们作弊了。我们偷偷地把概率f(Z=z)δz作为准确概率P(Z=z)的近似值。我们作弊了,因为连续的Z不存在确切的概率P(Z=z)。我们必须为这个过失做出赔偿,这正是我们接下来要做的。
现在,我们要执行我们的杰作,我们的拿手好戏,并在这样做的过程中,挽救自己。
由于ℝ >0是正实数的集合,在ℝ >0中有无数个大小为δz的显微镜区间。因此,对ℝ >0的求和是对无数个项的求和。这个事实为我们提供了用完全积分替换近似求和的完美机会,如下所示:
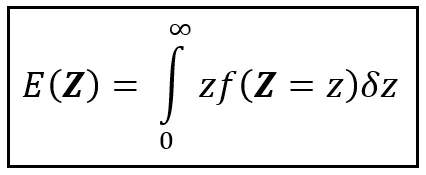
通常,如果Z的范围是实值区间[a,b],我们将确定积分的限制设置为a和b,而不是0和∞。
如果您知道Z的PDF,如果z乘以f(Z=z)在[a,b]上的积分存在,您将解决上面的积分,并为此获得E(Z)。
如果Z在范围[a,b]上均匀分布,其PDF如下:
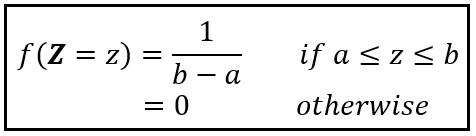
如果你设置a=1和b=5,
f(Z =z) = 1/(5–1) = 0.25。
概率密度在Z =1到Z =5之间是一个恒定的0.25,其他地方都是零。这是Z的概率密度函数的样子:
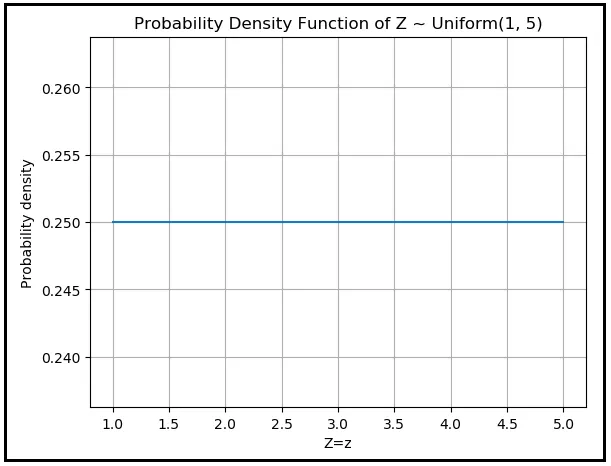
它基本上是一条从(1,0.25)到(5,0.25)的连续平坦水平线,在其他地方都是零。
一般来说,如果Z的概率密度在区间[a,b]上均匀分布,那么Z的概率密度函数在[a,b]上是1/(b-a),其他地方为零。你可以使用以下过程来计算E(Z):
![计算在区间[a,b]上均匀分布的连续随机变量的期望值的过程(作者提供的图像)](https://miro.medium.com/v2/resize:fit:640/format:webp/1*weJ-3ui55WQ4vDWyr8WvIw.png)
如果a=1和b=5,则Z ~ Uniform(1, 5)的均值简单地为(1+5)/2 = 3。这符合我们的直觉。如果在1和5之间的无限多个值每个值出现的可能性相等,我们会期望均值等于1和5的简单平均值。
现在,我不想泄气您,但实际上,你更有可能看到双重彩虹落在你的前院,而不是遇到连续随机变量,你将使用积分法来计算它们的期望值。

你看,那些看起来可爱的PDFs,可以通过积分得到相应变量的期望值,它们有一种嵌入在大学教科书章末练习中的习惯。它们就像家猫。它们不会‘出门’。但作为一个实践统计学家,‘外面’才是你生活的地方。在外面,你会发现自己盯着连续值的数据样本,比如车长。为了模拟这种现实世界的随机变量的概率密度函数,你可能会使用一些知名的连续函数,如正态分布、对数正态分布、Chi-square分布、指数分布、Weibull分布等,或混合分布,即看起来最适合你的数据的分布。
这里有一些这样的分布:

对于许多常用的概率密度函数,有人已经费劲心思用积分法(x乘以f(x))推导出其分布的均值,就像我们用均匀分布所做的那样。这里有一些这样的分布:

最后,在某些情况下,实际上是在许多情况下,真实生活数据集展现了过于复杂的模式,无法由任何一个分布进行建模。这就像你感染了一种病毒,它给你带来了一大堆症状。为了帮助你克服这些症状,你的医生会给你开一种药物组合,每种药物都有不同的强度、剂量和作用机制。当你遭遇到展现出许多复杂模式的数据时,你必须部署一支由多个概率分布组成的小军队来对其进行建模。这样不同分布的组合被称为混合分布。常用的混合分布是强大的高斯混合,它是几个正态分布随机变量的多个概率密度函数的加权和,每个随机变量都有不同的均值和方差组合。
在给定实值数据样本时,你可能会做一些非常简单的事情:你会取连续值数据列的平均值,并将其任命为样本均值。例如,如果你计算汽车数据集中的汽车长度的平均值,它为174.04927英寸,然后就完成了。但这不是全部,也不是完成了所有工作。因为你还有一个问题需要回答。
你的样本均值有多准确?感觉它的准确性
你如何知道你的样本均值作为总体均值的估计值是多么准确?在收集数据时,你可能运气不好,或懒惰,或者“数据受限”(这经常是老套的懒惰的好姿势)。无论哪种情况,你所面对的样本都不是比例随机的。它不能很好地代表人口的不同特征。让我们以汽车数据集为例:你可能收集了大量小型汽车的数据,但大型汽车的数据却太少。而且,你的样本中可能完全没有豪华轿车。因此,你计算出来的平均长度将过度偏向于人口中只有小型汽车的平均长度。不管你喜不喜欢,你现在正在工作,实际上是基于这样的信仰,即几乎每个人都开小型汽车。
要忠于自己
如果你收集了一个严重有偏的样本,而你不知道或者不关心它,那么愿上天帮助你在你所选择的职业中前进。但是,如果你愿意考虑可能存在的偏见,并且你有一些线索可以了解你可能缺少哪些数据(例如运动车型),那么统计学将用强大的机制来帮助你估计这种偏见。
不幸的是,无论你如何努力,你永远无法收集到一个完全平衡的样本。它总会包含偏见,因为人口中各种元素的确切比例对你来说永远无法获得。记得那扇通往人口的大门吗?记得门上的标志总是写着“关闭”吗?
你最有效的行动是收集一个包含人口中所有存在的东西大约相同比例的样本,也就是所谓的平衡样本。这个平衡样本的平均值是你可以使用的最好的样本均值。
但是,自然界的法则并不总是让统计学家的帆船顺风顺水。有一种自然的壮观属性表现在一个被称为中心极限定理(CLT)的定理中。你可以使用CLT来确定你的样本均值估计了人口均值的程度。
CLT并不是处理严重有偏样本的万能药。如果你的样本主要由中型汽车组成,你已经重新定义了人口的概念。如果你有意研究只有中型汽车的情况,那么你是免责的。在这种情况下,可以放心使用CLT。它将帮助你估计你的样本均值与中型汽车人口均值之间的接近程度。
另一方面,如果你的存在目的是研究有史以来生产的所有车辆总体,但你的样本大多数是中型汽车,那么你就有问题了。对于统计学的学生,让我稍微改一下话来重申一下。如果你的大学论文是关于宠物打哈欠的频率,但你的招募对象是20只猫和你邻居的贵宾犬,那么无论是否使用CLT,也无论是否使用任何统计魔法,都无法帮助你评估你的样本均值的准确性。
中心极限定理的本质
对中心极限定理的全面理解是另一篇文章的内容,但它陈述的本质是:
如果你从总体中抽取随机样本数据点并计算样本的平均值,然后重复这个过程多次,你将得到许多不同的样本平均值。好吧,这很显然!但接下来会发生一些惊人的事情。如果你绘制所有这些样本平均值的频率分布,你会发现它们总是正态分布的。更重要的是,这个正态分布的均值总是你所研究的总体的均值。正是这个宇宙个性中令人毛骨悚然的魅力,中心极限定理使用(还有什么?)数学语言来描述。
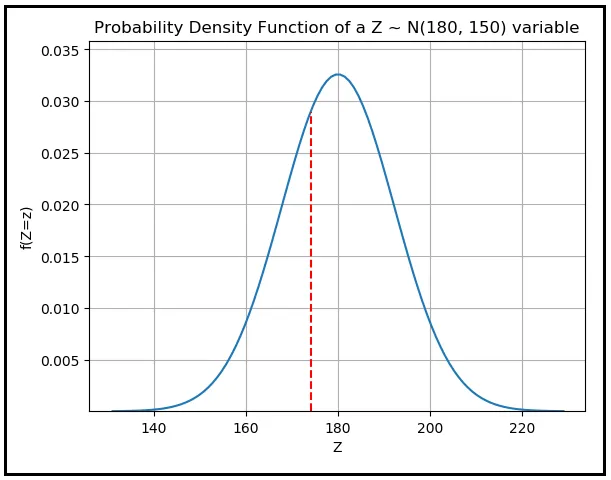
现在我们来看看如何使用中心极限定理。我们将按照以下方式开始:
使用来自单一样本的样本平均值Z _bar,我们将说明总体均值μ在区间[μ_low,μ_high]内的概率为(1-α):
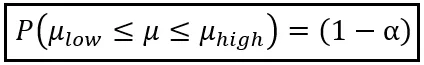
你可以将α设置为从0到1的任何值。例如,如果你将α设置为0.05,你将得到(1-α)为0.95,即95%。
为了使这个概率(1-α)成立,μ_low和μ_high的界限应该按以下方式计算:
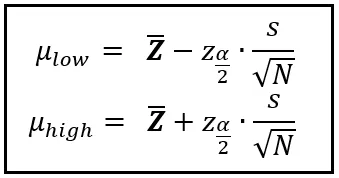
在上面的方程中,我们知道什么是Z _bar,α,μ_low和μ_high。其余的符号值得解释。
变量s是数据样本的标准偏差。
N是样本大小。
现在我们来到了z_α/2。
z_α/2是你将从标准正态分布的概率密度函数(PDF)的X轴上读取的一个值。标准正态分布是连续随机变量的PDF,它具有零均值和标准偏差为1。z_α/2是该分布的X轴上的值,使得PDF曲线下在该值左侧的面积为(1-α/2)。以下是当你将α设置为0.05时,这个面积的样子:
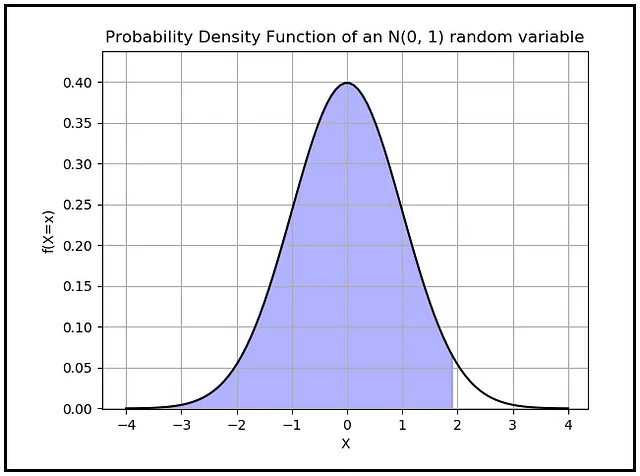
蓝色区域的计算结果为(1-0.05/2)=0.975。请记住,任何PDF曲线下的总面积始终为1.0。
总之,一旦你从单一样本计算出平均值(Z _bar),你可以建立围绕这个平均值的界限,使得总体均值在这些界限内的概率是你选择的值。
让我们重新审视估计这些边界的公式:
这些公式为我们提供了一些关于样本均值本质的见解:
- 随着样本方差s的增加,下界(μ_low)的值减小,而上界(μ_high)的值增加。这实际上将μ_low和μ_high彼此分开,并将它们远离样本均值。相反,随着样本方差的减小,μ_low从下方靠近Z _bar,μ_high从上方靠近Z _bar。区间边界从两侧基本上收敛于样本均值。实际上,区间[μ_low,μ_high]与样本方差成正比。如果样本在其均值周围广泛(或紧密)分散,那么更大的(或更小的)分散会降低(或增加)样本均值作为总体均值的估计的可靠性。
- 注意,区间的宽度与样本大小(N)成反比。在两个显示类似方差的样本之间,较大的样本将比较小的样本产生更紧密的平均值。
让我们看看如何计算汽车数据集的这个区间。我们将计算[μ_low,μ_high],以便有95%的机会总体均值μ在这些范围内。
为了获得95%的机会,我们应该将α设置为0.05,以便(1-α)= 0.95。
我们知道Z _bar为174.04927英寸。
N为205辆车。
可以轻松计算样本标准差。它为12.33729英寸。
接下来,我们将处理z_α / 2。由于α为0.05,α / 2为0.025。我们要找到z_α / 2的值,即z_0.025。这是标准正态随机变量的PDF曲线上X轴上的值,其中曲线下的面积为(1-α / 2)=(1-0.025)= 0.975。通过参考标准正态分布的表,我们发现该值对应于X =1.96左侧的区域。
将所有这些值代入,我们得到以下界限:
μ_low = Z_bar -(z_α / 2 · s /√N)= 174.04927 -(1.96 · 12.33729 / 205)= 173.93131
μ_high = Z_bar +(z_α / 2 · s /√N)= 174.04927 +(1.96 · 12.33729 / 205)= 174.16723
因此,[μ_low,μ_high] = [173.93131英寸,174.16723英寸]
有95%的机会总体均值位于此间隔内。看看这个间隔多么紧凑。它的宽度只有0.23592英寸。在这个微小的间隙中,有174.04927英寸的样本均值。尽管样本中可能存在所有偏差,但我们的分析表明,174.04927英寸的样本均值是未知总体均值的一个非常好的估计。
超越第一维:多维样本空间中的期望
到目前为止,我们关于期望的讨论都仅限于单个维度,但它不必如此。我们可以轻松地将期望的概念扩展到二维、三维或更高维。要计算多维空间上的期望,我们只需要一个在 N 维空间上定义的联合概率质量(或密度)函数。联合概率质量函数或密度函数将多个随机变量作为参数,并返回同时观察这些值的概率。
在本文的前面,我们定义了一个随机变量Y,它代表从汽车数据集中随机选择的车辆中的气缸数。 Y是您典型的单维离散随机变量,其期望值由以下公式给出:
让我们引入一个新的离散随机变量X。 X和Y的联合概率质量函数用P(X=x_i,Y=y_j)表示,或简单地用P(X,Y)表示。这个联合概率质量函数将我们从Y所占据的舒适的一维空间中抬升出来,将我们放置在一个更有趣的二维空间中。在这个二维空间中,单个数据点或结果由元组(x_i,y_i)表示。如果X的范围包含“p”个结果,Y的范围包含“q”个结果,那么二维空间将具有(p x q)个联合结果。我们使用元组(x_i,y_i)来表示每个这些联合结果。要在这个二维空间中计算E(Y),我们必须按以下方式调整E(Y)的公式:
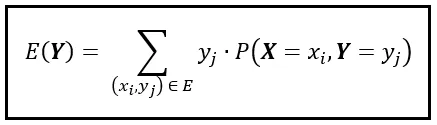
请注意,我们正在对二维空间中的所有可能的元组(x_i,y_i)求和。让我们将这个总和分解成一个嵌套求和,如下所示:
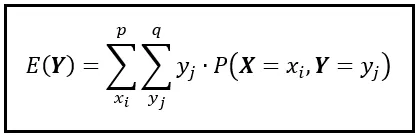
在嵌套求和中,内部求和计算出 y_j 和 P(X=x_i,Y=y_j)的乘积,对所有 y_j 的值进行求和。然后,外部求和为每个 x_i 的值重复内部求和。然后,它收集所有这些个体总和,并将它们加起来计算E(Y)。
我们可以通过简单地将求和嵌套在彼此之内来将上述公式扩展到任意数量的维度。您只需要一个在 N 维空间上定义的联合概率质量函数。例如,以下是如何将公式扩展到四维空间:
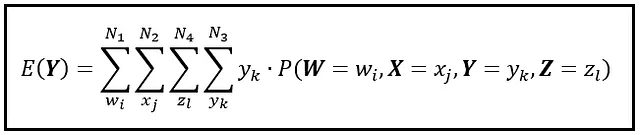
请注意,我们始终将Y的求和放在最深层。您可以以任何顺序排列其余的求和——您将得到E(Y)的相同结果。
你可能会问,为什么要定义一个联合概率质量函数,并且在其中进行所有这些嵌套求和?当在N维空间中计算E(Y)时,它的意义是什么?
理解多维空间中期望的含义的最佳方法是在真实的多维数据上说明其用途。
我们将使用的数据来自某艘船,这艘船与我搭乘的穿越英吉利海峡的那艘船不同,不幸的是它没有到达另一边。

下图显示了RMS Titanic 887名乘客数据集中的一些行:
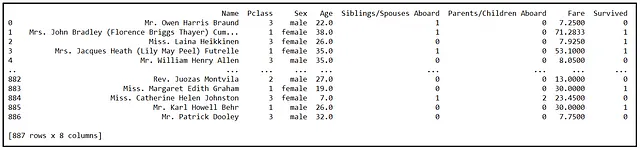
Pclass列代表乘客的舱位等级,取值为1、2或3。 Siblings/Spouses Aboard和Parents/Children Aboard变量是二进制(0/1)变量,表示乘客是否有任何兄弟姐妹、配偶、父母或子女在船上。在统计学中,我们常常而又有些残忍地将这些二进制指示变量称为虚拟变量。它们没有任何蠢笨的地方,不应该被贬低。
从表格中可以看出,有8个变量共同识别数据集中的每个乘客。每个这8个变量都是一个随机变量。我们面临的任务有三个:
- 我们需要定义一组随机变量的联合概率质量函数,
- 使用这个联合概率质量函数,我们要说明如何计算这个多维概率质量函数中一个变量的期望值,
- 我们要理解如何解释这个期望值。
为了简化问题,我们将“年龄”变量划分为大小为5岁的区间,并将区间标记为5、10、15、20……80。例如,年龄为20的分段意味着乘客的实际年龄在(15,20]年之间。我们将分段的随机变量称为Age_Range。
一旦对年龄进行分段,我们将按Pclass和Age_Range对数据进行分组。以下是分组计数:
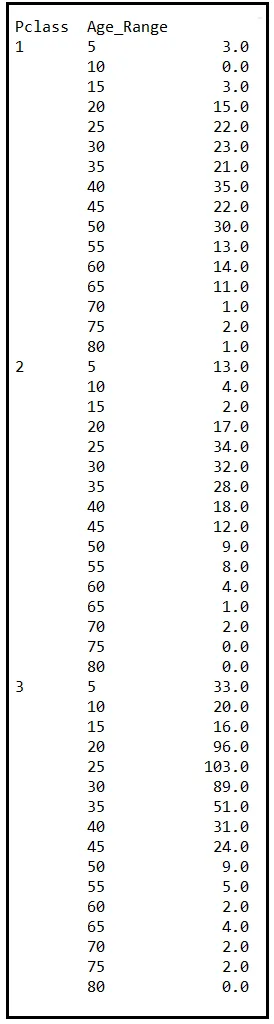
上表包含泰坦尼克号上每个集属(组)的乘客数量,这些集属由Pclass和Age_Range特征定义。顺便说一句,集属是统计学家非常崇拜的另一个词(与渐近相同)。这里有个提示:每次想说“组”,都说“集属”。我保证,无论你要说什么,都会立即听起来重要十倍。例如:“给八个不同的集属的酒精爱好者(对不起,品酒家)喝假酒,并记录他们的反应。”你懂我在说什么吧?
说实话,“集属”确实具有“组”的精确含义。但是,偶尔说一次“集属”,看到听众脸上的尊敬感增长,这也是很有益的。
无论如何,我们将在频率表中再添加一列。这一新列将保存观察到的特定组合Pclass和Age_Range的概率。这个概率,P(Pclass,Age_Range),是频率(即名称列中的数字)与数据集中的乘客总人数(即887)之比。
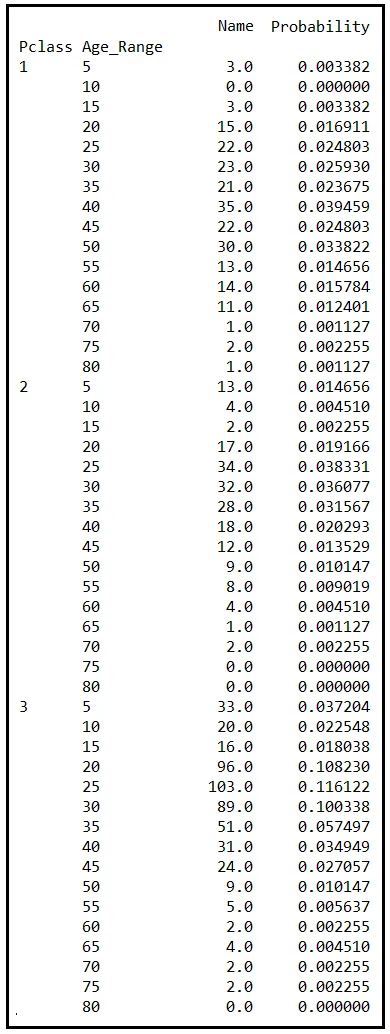
P(Pclass,Age_Range)是随机变量Pclass和Age_Range的联合概率质量函数。它给出了我们观察到由特定组合的Pclass和Age_Range描述的乘客的概率。例如,看看Pclass为3且Age_Range为25的行。相应的联合概率是0.116122。这个数字告诉我们,大约12%的泰坦尼克号3等舱的乘客年龄在20-25岁之间。
与一维PMF一样,联合PMF在其组成随机变量的所有值的所有组合上的评估结果也总和为1.0。如果您的联合PMF不总和为1.0,则应仔细查看您如何定义它。它的公式可能有错误,更糟糕的是,在您的实验设计中可能有错误。
在上述数据集中,联合PMF确实总和为1.0。请放心相信我!
要直观了解联合PMF,P(Pclass,Age_Range)的外观,您可以在三维中绘制它。在3D图中,将X和Y轴分别设置为Pclass和Age_Range,将Z轴设置为概率P(Pclass,Age_Range)。你将看到一个迷人的3D图表。
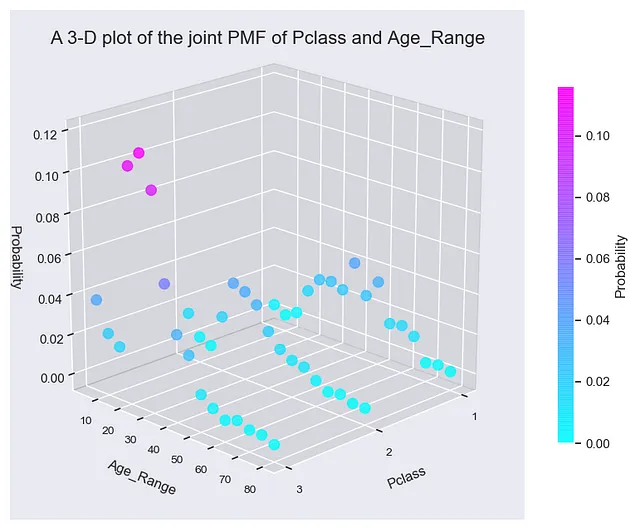
如果您仔细观察,您会注意到联合PMF由三个平行图组成,每个图对应泰坦尼克号上的一个船舱等级。这个3D图表展示了泰坦尼克号上人类的一些人口统计学信息。例如,在所有三个船舱等级中,年龄在15到40岁的乘客占了大部分人口。
现在让我们在这个二维空间中计算E(Age_Range)。E(Age_Range)由以下公式给出:
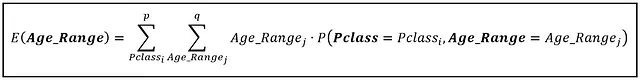
我们在所有Age_Range值上运行内部求和:5,10,15,…,80。我们在所有Pclass值上运行外部求和:[1,2,3]。对于每个(Pclass,Age_Range)组合,我们从表中选择联合概率。 Age_Range的期望值为31.48252537岁,相当于35岁的分段值。我们可以期望泰坦尼克号上的“平均”乘客年龄在30到35岁之间。
如果你对泰坦尼克号数据集中Age_Range列求平均值,你将得到完全相同的值:31.48252537岁。那么为什么不只是取Age_Range列的平均值来得到E(Age_Range)呢?为什么要建立一个 Rube Goldberg 机器来在 N 维空间中嵌套求和,最终得到同样的值呢?
这是因为在某些情况下,你只有联合概率质量函数和随机变量的范围。在这种情况下,如果你只有P(Pclass,Age_Range),并且你知道Pclass的范围为[1,2,3],Age_Range的范围为[5,10,15,20,…,80],你仍然可以使用嵌套求和技术来计算E(Pclass)或 E(Age_Range)。
如果随机变量是连续的,可以使用多重积分在多维空间中找到期望值。例如,如果X,Y和Z是连续随机变量,且f(X,Y,Z)是定义在3维连续空间元组(x,y,z)上的联合概率密度函数,则在这个三维空间上定义的Y的期望值如下图所示:
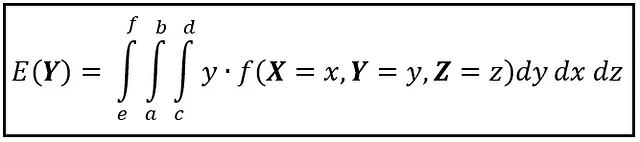
与离散情况类似,首先对要计算其期望值的变量进行积分,然后对其余变量进行积分。
一个著名的例子,演示了多重积分方法用于计算期望值,其规模对于人眼来说太小而无法感知。我指的是量子力学的波函数。波函数在笛卡尔坐标系中表示为Ψ(x,y,z,t),在极坐标系中表示为Ψ(r,θ,ɸ,t)。它用于描述那些喜欢生活在非常狭小空间中的微小事物的属性,比如原子中的电子。波函数Ψ返回一个形如A + jB的复数,其中A表示实部,B表示虚部。我们可以将|Ψ|²解释为在时间t时描述由元组(x,y,z)或(r,θ,ɸ)描述的4维空间中的联合概率密度函数。特别是对于氢原子中的电子,我们可以将|Ψ|²解释为在(x,y,z)或(r,θ,ɸ)周围的极小空间内找到电子的近似概率。通过知道|Ψ|²,我们可以在 x,y,z 和 t 上运行四重积分来计算电子在 X,Y 或 Z 轴(或其极坐标等效轴)上的期望位置。
结束语
我以晕船的经历开始了这篇文章。如果我使用 Bernoulli 随机变量来模拟一个非常复杂且有些难以理解的人类困境,那么你应该不会怪我。我的目标是用随机变量的有趣和舒适的语言来说明期望如何在生物水平上影响我们。
从看似简单的伯努利变量开始,我们将我们的描绘性刷子划过了统计画布,一直到量子波函数的宏伟多维复杂性。在这个过程中,我们试图理解期望如何在离散和连续尺度、单个和多个维度以及微观尺度上运作。
期望还在另一个领域产生了巨大影响。这个领域是条件概率,在这个领域中,我们计算一个随机变量X在假设某些其他随机变量A、B、C等已经取了值“a”、“b”、“c”时,将取到值“x”的概率。在所有我们已经看到的期望公式中,如果你用相同条件的条件版本替换概率(或概率密度),你将得到相应的条件期望公式。它表示为E(X=x|A=a,B=b,C=c),是回归分析和估计领域的核心。这将成为未来文章的素材!
引用和版权
数据集
汽车数据集是在CC BY 4.0许可下从UC Irvine机器学习存储库下载的。
泰坦尼克号数据集是从Kaggle下载的,采用CC0许可。
图片
本文章中的所有图片版权均为Sachin Date的CC-BY-NC-SA,除非图片下方提到了不同的来源和版权。
如果你喜欢这篇文章,请关注我的Sachin Date,获取关于回归、时间序列分析和预测等主题的技巧、方法和编程建议。




