机器学习评估指标:理论与概述
机器学习评估指标:概述

构建一个在新数据上能够很好泛化的机器学习模型非常具有挑战性。需要对模型进行评估,以了解模型是否足够好,或者是否需要进行一些修改以提高性能。
如果模型在训练集上没有学习到足够多的模式,它在训练集和测试集上的表现都会很差。这就是所谓的欠拟合问题。
如果模型对训练数据的模式学习得太多,甚至包括噪音,它在训练集上的表现会很好,但在测试集上的表现会很差。这种情况被称为过拟合。模型的泛化能力可以通过在训练集和测试集上测量的性能来获得。
在本文中,我们将介绍用于分类和回归问题的最重要的评估指标,这些指标将有助于验证模型是否很好地捕捉到了训练样本中的模式,并在未知数据上表现良好。让我们开始吧!
分类
当我们的目标是分类的时候,我们面临的是一个分类问题。选择最合适的评估指标取决于不同的方面,例如数据集的特征、是否不平衡以及分析的目标。
在展示评估指标之前,有一个重要的表格需要解释,称为混淆矩阵,它很好地总结了分类模型的性能。
假设我们想要训练一个模型来从超声图像中检测乳腺癌。我们只有两个类别,恶性和良性。
- 真正例:被预测为恶性癌症的晚期患者数量
- 真反例:被预测为良性癌症的健康人数量
- 假正例:被预测为恶性癌症的健康人数量
- 假反例:被预测为良性癌症的晚期患者数量

准确率

准确率是评估分类模型的最为人所知和流行的指标之一。它是正确预测的数量除以样本数量的比例。
当我们知道数据集是平衡的时候,就可以使用准确率。因此,输出变量的每个类别具有相同数量的观察值。
使用准确率,我们可以回答问题“模型是否正确预测了所有类别?”因此,我们有对于正类(恶性癌症)和负类(良性癌症)的正确预测。
精确率

与准确率不同,精确率是一种用于分类的评估指标,用于处理类别不平衡的情况。
精确率回答以下问题:“恶性癌症识别的比例实际上是多少?”。它的计算方法是真正例和正预测之间的比率。
如果我们关心假正例并希望将其最小化,我们会使用精确率。避免用虚假的恶性癌症新闻影响健康人的生活将会更好。
假正例的数量越少,精确率就越高。
召回率

与精确率一起,召回率是另一个应用于输出变量类别观察数量不同的指标。召回率回答以下问题:“我能够识别出多少患有恶性癌症的患者的比例?”。
如果我们关注假阴性的话,我们关心召回率。假阴性意味着患者患有恶性肿瘤,但我们无法识别出来。因此,应同时监控召回率和精确率,以在未知数据上获得理想的性能。
F1分数
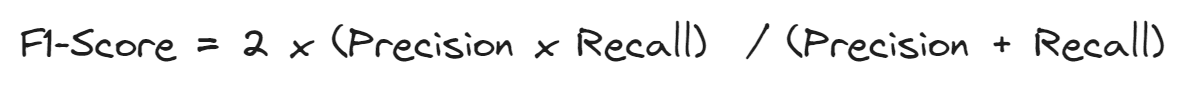
同时监控精确率和召回率可能会很混乱,最好有一个综合这两个指标的度量方式。这就是F1分数,它被定义为精确率和召回率的调和平均值。
如果精确率和召回率都很高,那么F1分数就会很高。如果召回率或精确率较低,F1分数将受到惩罚,并且其值也会较低。
回归

当输出变量是数值时,我们处理的是一个回归问题。与分类问题一样,根据分析目的选择评估回归模型的指标非常重要。
最常见的回归问题示例是房价预测。我们是希望准确预测房价还是只关心最小化整体误差呢?
在所有这些指标中,构建块都是残差,即预测值与实际值之间的差异。
MAE
 平均绝对误差计算平均绝对残差。
平均绝对误差计算平均绝对残差。
它不像其他评估指标那样严厉地惩罚高误差。每个误差都被平等对待,甚至是离群值的误差,因此该指标对离群值具有鲁棒性。此外,差异的绝对值忽略了误差的方向。
MSE
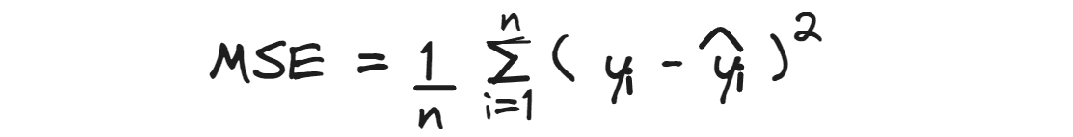
均方误差计算平均平方残差。
由于预测值与实际值之间的差异是平方的,它对较大的误差给予更大的权重,因此在不希望出现较大误差而是希望最小化整体误差时,它可能是有用的。
RMSE
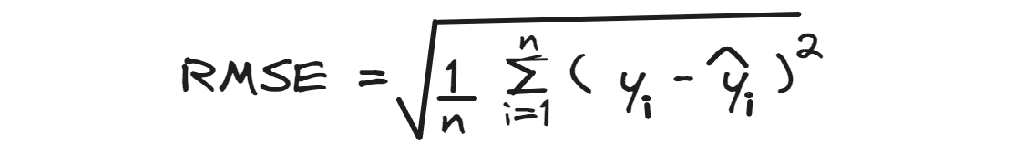
均方根误差计算平均平方残差的平方根。
当你理解了MSE,你只需要花一点时间来理解均方根误差,它只是MSE的平方根。
RMSE的好处是更容易解释,因为该指标在目标变量的尺度上。除了形状之外,它与MSE非常相似:它总是对较大差异给予更大权重。
MAPE
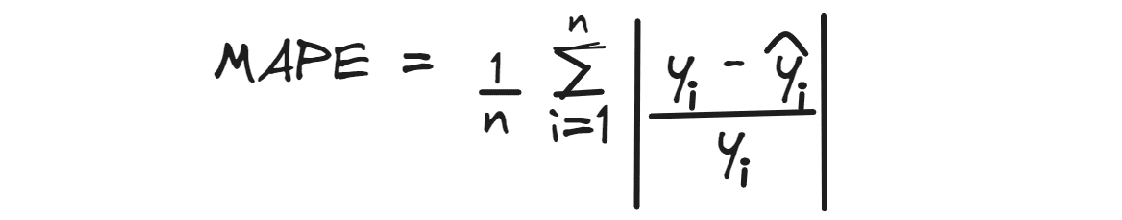
平均绝对百分比误差计算预测值与实际值之间的平均绝对百分比差异。
像MAE一样,它忽略了误差的方向,最理想的值理论上为0。
例如,如果我们获得了一个预测房价的MAPE值为0.3,那么平均而言,预测值低于实际值的30%。
最后的思考
希望您享受这些评估指标的概述。我只介绍了用于评估分类和回归模型性能的最重要的度量标准。如果您发现了其他救命的指标,在解决问题时对您有所帮助,但它们在这里没有提到,请在评论中提及。
Eugenia Anello目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在连续学习与异常检测的结合上。





