蒙特卡洛逼近方法:你应该选择哪种方法以及何时选择?
蒙特卡洛逼近方法选择与时机
是逆变换、随机游走Metropolis-Hastings还是吉布斯?一项重点研究数学基础、Python从零开始实现和各种方法的优缺点的分析
近似抽样简介
对于大多数实用的概率模型,准确推断是不可计算的,因此我们必须求助于某种形式的近似方法。
——《模式识别与机器学习¹》
由于我们刚才看到的概率模型中的确定性推断通常是不可计算的,因此我们现在转向基于数值抽样的近似方法,这些方法被称为Monte Carlo技术。我们将使用这些方法来研究的关键问题是计算给定概率分布p(z)的目标函数f(z)的期望。回想一下,期望的简单定义是一个积分:
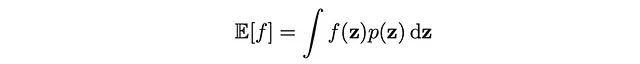
正如我们将看到的,这些积分在计算上过于复杂,因此我们将在本文中转向抽样方法。
在本文中,我们将研究3种核心抽样方法:逆变换、马尔可夫链蒙特卡洛(MCMC)和吉布斯抽样。通过了解这些方法的基本统计属性和计算要求,我们将了解到:
- 逆变换抽样最适合从已知且简单的分布中高精度模拟数据,尤其是在低维情况下。
- 随机游走Metropolis-Hastings最适合复杂、多模态或未知分布,其中全局探索和/或收敛是优先考虑的;具体而言,Metropolis算法——Metropolis-Hastings的一个特定实例——可用于对称分布。
- 吉布斯抽样最适合高维问题,其中条件分布易于抽样,并且效率是首要考虑的。
目录
- 逆变换抽样• 算法原理• Python实现• 先决条件• 优缺点
- 马尔可夫链蒙特卡洛• Metropolis-Hastings算法• 特殊情况:对称分布的Metropolis算法• 优缺点
- 吉布斯抽样• 算法• 条件• 吉布斯与Metropolis-Hastings的关系
- 比较:变换法与Met-Hastings与吉布斯的优缺点
1. 变换方法:逆累积分布函数
逆变换抽样,顾名思义,使用目标分布的逆累积分布函数(CDF)生成遵循所需分布的随机数。基本思想是:
- 生成均匀随机数:我们从0到1之间的均匀分布中抽取一个数U。
- 应用逆累积分布函数:使用目标分布的CDF的逆函数,将U转换为遵循目标分布的样本。
下面是从分布中绘制的样本(蓝色)的快速示例(红色):
逆CDF是一种计算上简单且通用的方法,用于从我们知道CDF的分布(例如正态、指数、伽玛或贝塔分布)中进行抽样。
PDF,CDF和逆CDF
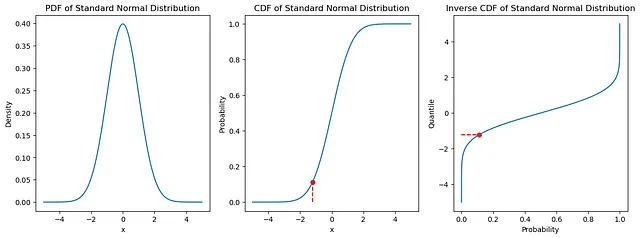
直观地说,CDF是PDF的累积值,等于PDF的积分;然后我们取CDF函数的逆来得到该方法所使用的最终逆CDF。
形式上,如果a是一个随机变量,则a的CDF由以下给出:
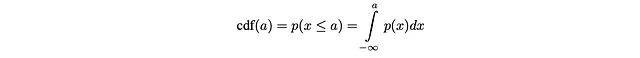
CDF F具有以下关键特性:
- F是连续的
- F是非递减的
- F的范围为0 ≤ cdf(a) ≤ 1,其中a ∈ R
逆CDF算法的工作原理是什么?
该算法由以下要素组成:
输入:
U:U是在0和1之间均匀分布的随机变量。- 这作为逆CDF的输入概率,并将被转化为所需分布的样本。
参数:
F:目标分布的CDF。- 有了F,我们可以简单地计算其逆F^-1,并用它将输入值映射到所需的域。
输出:
x:从目标分布中抽取的随机样本。- 这是通过将逆CDF应用于来自均匀分布(输入)的随机数生成的。
Python实现
现在,让我们从头开始实现这个方法。我们将使用指数函数,因为它很容易将我们通过逆CDF绘制的样本与精确分布进行比较:
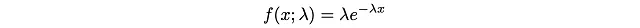
通过标准的微积分积分技术,我们发现目标CDF F(x)为:
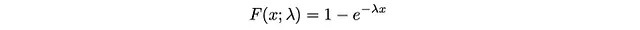
这个CDF的逆是:
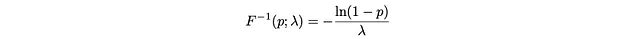
我们将使用逆CDF方法生成5000个样本:
import numpy as npimport matplotlib.pyplot as plt# 用lambda = 1的指数分布的逆CDFdef inverse_cdf(p): return -np.log(1 - p)# 使用逆CDF生成1000个样本值uniform_samples = np.random.uniform(0, 1, 1000)transformed_samples = inverse_cdf(uniform_samples)# 生成x值和真实的PDFx_values = np.linspace(0, np.max(transformed_samples), 1000)pdf_values = np.exp(-x_values)
逆CDF算法工作的要求
逆CDF方法有一个关键的假设:
- CDF F可逆:CDF F必须是可逆的,即每个输入都必须有唯一的输出
这个约束条件排除了一些函数。例如,下面是一些常见但不可逆(因此不能与逆CDF一起使用)的函数类型:
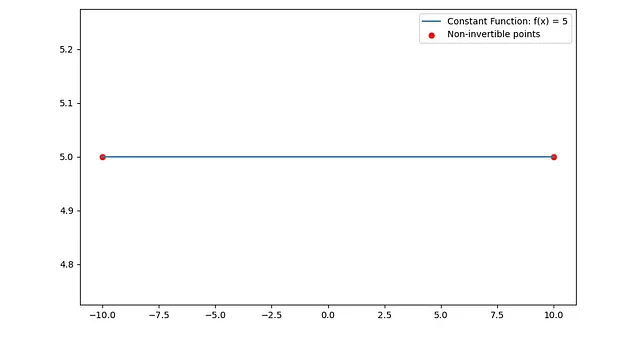
- 常数函数:任何形式为f(x) = c的常数函数都不可逆,因为每个输入都映射到相同的输出,因此该函数不是一对一的。
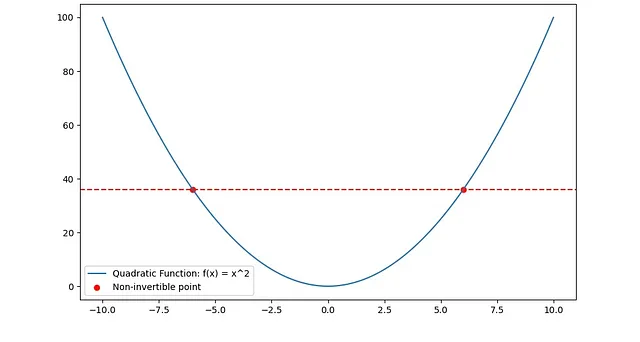
2. 某些二次函数:例如f(x) = x^2是不可逆的,因为它是多对一的(考虑f(x) = 1,x可以是1或-1)。
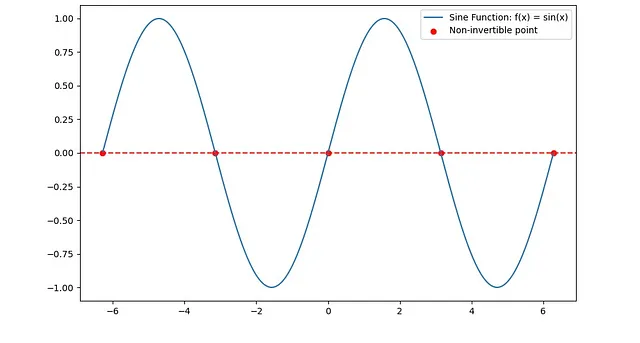
3. 某些三角函数:例如f(x) = sin(x)在整个定义域上不可逆,因为它们是周期性的,尽管在限定域内它们可以可逆。
为什么逆CDF有效?
关键思想是,将一个在0和1之间均匀分布的随机变量通过应用目标分布的CDF的逆,可以转化为具有特定分布的随机变量,假设已知和可处理。
优点
- 算法简单性:在低维数据中非常容易实现,因此在不同领域和任务中应用广泛。
- 样本准确性:假设CDF及其逆表示精确的目标分布,与其他方法(如MCMC)相比,该方法具有相对较高的准确性。
缺点
- 计算复杂性:对于某些分布,逆CDF可能没有闭合形式的表达式,使计算具有挑战性或昂贵。
- 高维度困难:在高维空间中应用可能很困难,尤其是在变量之间存在依赖关系时。
- 可逆性约束:任何时候,如果CDF是不可逆的,该方法就无效。这排除了一些函数,正如我们上面看到的。
- 局限于已知分布:逆CDF仅适用于已知分布,需要准确的CDF形式。
考虑到所有这些限制,我们只能将逆CDF应用于几个类别的分布。实际上,在大数据和未知分布的情况下,这种方法很快就会变得不可用。
在考虑这些优缺点的基础上,现在让我们来看另一个解决这些限制的随机抽样框架:马尔可夫链蒙特卡洛(MCMC)。
2. 马尔可夫链蒙特卡洛(MCMC)
正如我们刚才看到的,逆CDF转换方法非常受限,特别是在高维样本空间中。而马尔可夫链蒙特卡洛(MCMC)在处理维度时具有良好的可扩展性,使我们能够从更大的一类分布中进行采样。
Metropolis-Hastings算法如何工作?
从直观的角度来看,该算法按照以下步骤工作:与逆CDF类似,我们有一个目标分布,我们从中进行采样。然而,我们需要额外的内容:当前状态z*,并且q(z|z*)依赖于z*,从而创建了一个具有样本z¹、z²、z³等的马尔可夫链。只有当样本满足某个准则时,才会将其接受到链中,由于该准则在算法的不同变体之间有所不同,我们将在下文中定义。
让我们将其形式化为更具算法性质的结构。
该算法运行周期,并且每个周期按照以下步骤进行:
- 从建议分布中生成样本z*。
- 以概率接受该样本,然后我们将接受该值的概率定义为接受概率,在Metropolis-Hastings中定义为:
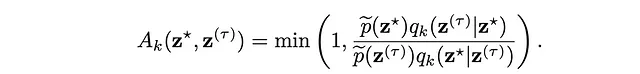
其中
- z*是当前状态。
- z^T是提议的新状态。
- p(z*)是根据期望分布的状态z*的概率。
- p(z^T)是根据期望分布的状态z^T的概率。
这个接受阈值背后的逻辑是确保更可能的状态(根据期望分布)被更频繁地访问。
现在,这是算法的最一般化版本;如果建议分布被认为是对称的,即从状态x到x′的移动的概率与从x′到x的移动的概率相同,即q(x′|x) = q(x|x′),那么我们可以使用Metropolis-Hastings的一种特殊情况,该情况需要一个更简单的接受阈值。
对称分布的Metropolis算法
这是一个特定的MCMC算法,我们选择在建议分布对称的情况下使用,即对于所有1和0的值,解释为“从任意状态A转换到状态B的概率等于从B转换到A的概率”。因此,算法的每一步变为:
- 从建议分布中生成样本z*。
- 以概率接受该样本:

Metropolis-Hastings算法和Metropolis算法
让我们将这两个算法放在一起进行比较。正如我们之前看到的,唯一的区别在于接受阈值,其他步骤都完全相同:

优点
- 收敛到平衡分布:在某些情况下,随机游走可以收敛到所需的平衡分布,尽管在高维空间中可能需要很长时间。
- 计算成本低:与其他复杂的采样方法相比,随机游走通常需要较少的计算资源,适用于计算效率是优先考虑的问题。
- 应用的多样性:由于其与自然发生的模式的高相似性,随机游走在各种领域都有应用:• 物理学:液体和气体中分子的布朗运动。• 网络分析• 金融市场:模拟股价的变动• 种群遗传学
缺点:
- 对初始化敏感:算法的性能可能对起始值的选择敏感,特别是如果初始化值远离高密度区域。
- 局部极值问题:根据提议分布的复杂性,算法可能会陷入局部极值,并且难以沿分布遍历到其他区域。
现在,记住Metropolis-Hastings算法,让我们来看另一个特殊实例:Gibbs抽样。
3. Gibbs抽样
Gibbs抽样是Metropolis-Hastings的一个特殊实例,每一步都被接受。首先让我们看一下Gibbs抽样算法本身。
Gibbs算法如何工作?
这个想法相对简单,最好通过一个涉及从分布p(z1, z2, z3)中抽样的微观示例进行说明。算法的步骤如下:
- 在时间步骤T,将起始值初始化为:
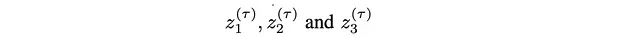
2. 为z1绘制新值:

3. 从条件中绘制第二个位置z2的新值:
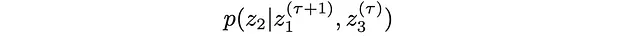
4. 最后为最后一个位置z3绘制新值:
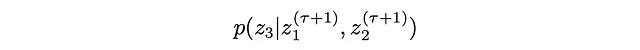
5. 重复此过程,循环遍历三个变量z1…z3,直到达到一定的满意阈值。
广义算法
形式上,该算法首先初始化起始位置,然后进行T个连续步骤
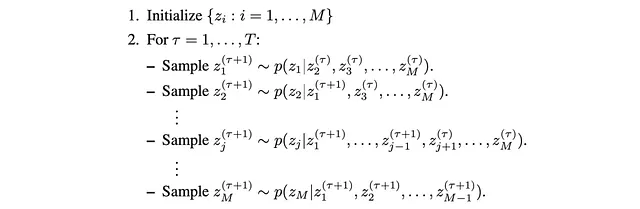
Gibbs抽样从目标分布中正确抽样的条件
- 不变性。目标分布p(z)在每个Gibbs步骤中保持不变,因此p(z)在整个马尔可夫链中保持不变。
- 遍历性。如果条件分布都不为零,则暗示着遍历性,因为在有限步骤内可以到达z空间中的任意点。
- 足够的预烧。正如我们在任何需要随机初始化的方法中所看到的,前几个样本依赖于初始化,但在多次迭代后,这种依赖性会减弱。
这与Metropolis-Hastings有什么关系?
在Metropolis-Hastings中,我们将接受阈值定义为:
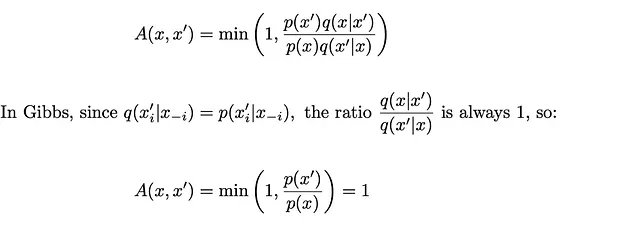
因此,Metropolis-Hastings的提议步骤总是被接受的,就像我们在Gibbs算法中看到的那样。
变体
由于Gibbs方法一次更新一个变量,因此连续样本之间存在强依赖关系。为了克服这个问题,我们可以使用一种中间策略来从变量组而不是单个变量中进行抽样,称为阻塞Gibbs。
同样,由于马尔可夫链的性质,连续抽取的样本之间会存在相关性。为了生成独立的样本,我们可以在序列内使用子抽样。
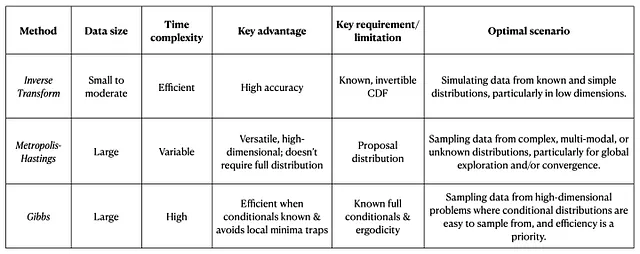
4. 优点/缺点: 逆变换采样 vs Metropolis-Hastings vs Gibbs
现在我们已经了解了每种算法的工作原理和应用领域,让我们总结一下每种方法的定义特征。
1. 逆变换采样
- 数据大小:适用于中等大小的数据集。
- 时间:对于单变量分布通常高效。
- 数据复杂度:适用于简单分布,其中累积分布函数(CDF)及其反函数是已知且易于计算的。
- 如果要避免的情况:采样高维变量/分布。
- 最大优势:如果CDF准确反映目标分布,则准确性高。
- 要求:必须知道并且可逆的CDF。
2. Metropolis-Hastings(MCMC)
- 数据大小:可扩展且适用于大型数据集。
- 时间:根据目标分布的复杂性可能计算密集。
- 数据复杂度:适用于复杂或多模态分布。
- 最大优势:- 可在不知道归一化常数(完整形式)的情况下对分布进行抽样- 适用于探索分布的全局结构并保证收敛
- 缺点:可能因以下原因导致收敛速度非常慢:- 复杂或多峰目标分布,因为算法可能陷入局部模式并难以在它们之间过渡;- 变量高度相关;- 高维空间;- 初始值或步长选择不当。
3. Gibbs抽样
- 数据大小:适用于小型和大型数据集。
- 时间:通常比随机行走Metropolis-Hastings更高效,因为它不需要接受/拒绝步骤。
- 数据复杂度:最适用于处理高维分布,其中可以从每个变量的条件分布中进行抽样。
- 最大优势:- 可以轻松计算条件分布;- 相对于随机行走,更不容易陷入局部最小值陷阱。
- 要求:- 马尔可夫链遍历性 – 必须知道并且易于处理全条件分布
总结:
结论
感谢您一直陪伴阅读至此!在本文中,我们介绍了三种重要的近似抽样方法:逆CDF、Metropolis Hastings MCMC和Gibbs Sampling MCMC。我们探讨了每个算法的功能、各自的优缺点以及典型的使用情况。
逆CDF提供了一种从已知分布中进行抽样的直接方法,当其CDF可逆时。它在计算效率上具有优势,但对于高维或复杂分布不太适用。Metropolis Hastings MCMC提供了一种更通用的方法,可以从难以处理的分布中进行抽样。然而,它需要更多的计算资源,并且可能对调整参数(如提议分布)敏感。Gibbs Sampling MCMC在联合分布复杂但可以分解为简单条件分布时特别高效。它在机器学习中被广泛使用,但对于高维问题可能收敛较慢且占用内存较多。
[1] Bishop, C. M. (2016). Pattern Recognition and Machine Learning (Softcover reprint of the original 1st edition 2006 (corrected at 8th printing 2009)). Springer New York.
*除非另有说明,所有图片均由作者创建。




