视觉BERT技巧 | 发挥您首次遭遇的力量
Visual BERT Tips | Harness the Power of Your First Encounter
介绍
谷歌表示BERT是一个重要的进步,是搜索历史上最大的改进之一。它帮助谷歌更准确地理解人们的需求。Visual BERT的精通之处在于它可以通过查看单词前后的单词来理解句子中的单词。这有助于更好地理解句子的含义。就像我们通过考虑句子中的所有单词来理解句子一样。

BERT帮助计算机在不同情况下理解文本的含义。例如,它可以帮助分类文本,理解信息中的人们的情感,回答识别的问题,以及事物或人的名称。在谷歌搜索中使用BERT展示了语言模型的长足发展,并使我们与计算机的互动更加自然和有益。
学习目标
- 了解BERT的全称(来自Transformer的双向编码器表示)。
- 了解BERT是如何通过大量文本数据进行训练的。
- 理解预训练的概念以及它如何帮助BERT发展语言理解能力。
- 认识到BERT同时考虑了句子中单词的左右上下文。
- 在搜索引擎中使用BERT更好地理解用户查询。
- 探索BERT在训练中使用的遮蔽语言模型和下一个句子预测任务。
本文是数据科学博客马拉松的一部分。
BERT是什么?
BERT是双向编码器表示来自Transformer的缩写。它是一种特殊的计算机模型,可以帮助计算机理解和处理人类语言。它是一种能够像我们一样阅读和理解文本的智能工具。
BERT之所以特殊,是因为它可以通过查看单词前后的单词来理解句子中单词的含义。就像阅读一句话并通过考虑所有单词来理解其含义一样。

BERT使用来自书籍、文章和网站的文本进行训练。这有助于它学习单词之间的模式和联系。因此,当我们给BERT一个句子时,它可以根据其训练来推断每个单词的含义和上下文。
BERT理解语言的这种强大能力在许多不同的方式中得到应用。它还可以帮助分类文本、理解信息中的情感或情绪,并回答问题。
SST2数据集
数据集链接:https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2
在本文中,我们将使用上述数据集,该数据集包含从电影评论中提取的句子。值1表示正面标签,0表示负面标签。

通过在该数据集上训练模型,我们可以教给模型根据从标记数据中学到的模式将新句子分类为正面或负面。
模型:句子情感分类
我们的目标是创建一个情感分析模型,将句子分类为正面或负面。

通过将DistilBERT的句子处理能力与逻辑回归的分类能力相结合,我们可以构建一个高效准确的情感分析模型。

使用DistilBERT生成句子嵌入:利用预训练的DistilBERT模型为2,000个句子生成句子嵌入。

这些句子嵌入捕捉了句子的重要信息和上下文。
执行训练/测试拆分:将数据集分为训练集和测试集。

使用训练集来训练逻辑回归模型,而测试集将用于评估。
训练逻辑回归模型:使用scikit-learn利用训练集来训练逻辑回归模型。

逻辑回归模型学习根据句子嵌入将句子分类为正面或负面。
通过遵循这个计划,我们可以利用DistilBERT的强大功能生成信息丰富的句子嵌入,然后训练逻辑回归模型进行情感分类。评估步骤允许我们评估模型在预测新句子情感方面的性能。
如何计算单个预测?
以下是一个经过训练的模型如何使用示例句子“a visually stunning rumination on love”计算其预测的解释:
分词:将短语中的每个单词分割为较小的组件,称为标记。分词器还在开头插入特定的标记,如“CLS”,在结尾插入“SEP”。

标记到ID的转换:然后,分词器将每个标记替换为嵌入表中对应的ID。嵌入表是训练模型附带的组件,将标记映射到它们的数值表示。
输入的形状:经过分词和转换后,DistilBERT将输入句子转换为适合处理的正确形状。它将句子表示为带有唯一标记的标记ID序列。

请注意,使用库提供的分词器,您可以使用一行代码执行所有这些步骤,包括分词和ID转换。

在进行这些预处理步骤后,输入句子会以一种格式准备好,可以输入到DistilBERT模型进行进一步处理和预测。
通过DistilBERT的处理流程
确实,将输入向量通过DistilBERT的处理过程与BERT类似。输出将包含每个输入标记的向量,其中每个向量包含768个数字(浮点数)。

对于句子分类,我们只关注第一个向量,它对应于[CLS]标记。[CLS]标记被设计用来捕捉整个序列的总体上下文,因此在BERT等模型中,仅使用第一个向量([CLS]标记)进行句子分类是有效的。该标记的位置、其在预训练中的功能以及汇集技术都有助于其编码用于分类任务的重要信息的能力。此向量作为输入传递给逻辑回归模型。
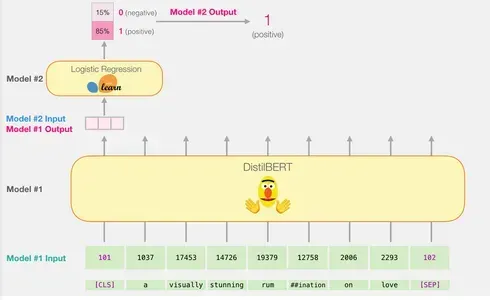
逻辑回归模型的作用是基于其在训练阶段的学习来对该向量进行分类。我们可以将预测计算想象为以下方式:
- 逻辑回归模型将输入向量(与[CLS]标记相关联)作为其输入。
- 它将一组学习到的权重应用于向量中的每个768个数字。
- 加权的数字相加,并添加额外的偏置项。
最后,求和结果通过sigmoid函数传递,产生预测分数。

逻辑回归模型的训练阶段和整个过程的完整代码将在下一节中讨论。
从头开始实现
本节将介绍训练这个句子分类模型的代码。
导入库
让我们从导入所需的工具开始。我们可以使用df.head()来查看数据框的前五行,以了解数据的样子。

导入预训练的DistilBERT模型和分词器
我们将对数据集进行分词处理,但与前面的示例有些不同。我们将批量处理所有句子,而不是一次处理一个句子。
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer,
'distilbert-base-uncased')
## 想要BERT而不是DistilBERT?
## 取消下面一行的注释:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer,
'bert-base-uncased')
# 加载预训练模型/分词器
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)例如,假设我们有一个电影评论数据集,我们希望同时对2000个评论进行分词处理。我们将使用一个名为DistilBertTokenizer的分词器,这是一个专门用于使用DistilBERT模型对文本进行分词处理的工具。
分词器将整个句子批量进行分词处理,将句子分割成称为标记的较小单元。它还添加特殊标记,如在每个句子开头的[CLS]和结尾的[SEP]。
分词处理
因此,每个句子都变成了一个id列表。数据集由一个列表的列表(或pandas Series/DataFrame)组成。较短的短语必须使用标记id 0进行填充,以使所有向量的长度相同。现在我们有了一个可以在填充之后提供给BERT的矩阵/张量:
tokenized = df[0].apply((lambda x: tokenizer.
encode(x, add_special_tokens=True)))

使用DistilBERT进行处理
填充的标记矩阵现在被转换为输入张量,并提交给DistilBERT。
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)DistilBERT的输出在完成此步骤后存储在last_hidden_states中。在我们的情况下,由于我们只考虑了2000个实例,因此这将是2000(2000个示例中最长序列的标记数)和768(DistilBERT模型中隐藏单元的数量)。
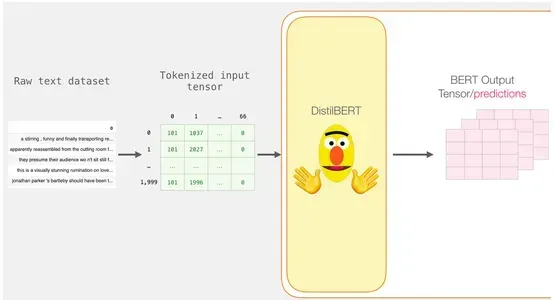
解压BERT输出张量
让我们检查3D输出张量的维度并提取它。假设您有包含DistilBERT输出张量的last_hidden_states变量。
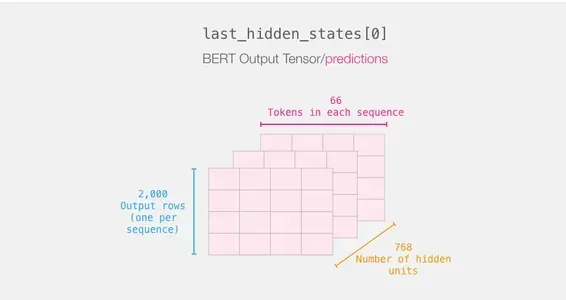
回顾句子的旅程
每一行都附有我们数据集中的文本。为了回顾第一句的处理流程,可以将其想象成如下所示:

切割重要部分
我们只选择立方体的那个切片用于句子分类,因为我们只对[BERT]标记的结果感兴趣。

为了从那个3D张量中获得我们感兴趣的2D张量,我们进行如下切片:
# 对所有序列的第一个位置进行切片,获取所有隐藏单元的输出
features = last_hidden_states[0][:,0,:].numpy()最后,特征是一个包含数据集中所有句子的句子嵌入的2D numpy数组。

应用逻辑回归
现在我们有了BERT的输出,我们可以使用这个数据集来训练我们的逻辑回归模型。我们的第一个数据集中的768列包括特征和标签。

在进行传统的机器学习的训练/测试集划分后,我们可以定义并训练我们的逻辑回归模型。
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)使用此方法,数据集被划分为训练集和测试集:

然后使用训练集来训练逻辑回归模型。
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)模型训练完成后,我们可以将其结果与测试集进行比较:
lr_clf.score(test_features, test_labels)这给出了模型约81%的准确率。
结论
总之,BERT是一个强大的语言模型,可以帮助计算机更好地理解人类语言。通过考虑单词的上下文并在大量文本数据上进行训练,BERT可以捕捉意义并提高语言理解能力。
要点
- BERT是一个帮助计算机更好地理解人类语言的语言模型。
- 它考虑了句子中单词的上下文,使其在理解意义方面更加智能。
- BERT在大量文本数据上进行训练以学习语言模式。
- 它可以针对特定任务进行微调,如文本分类或问题回答。
- BERT改进了搜索结果和应用中的语言理解。
- 它通过将陌生单词分解成较小的部分来处理。
- BERT与TensorFlow和PyTorch一起使用。
BERT改进了搜索引擎和文本分类等应用,使它们更加智能和有帮助。总体而言,BERT在使计算机更有效地理解人类语言方面迈出了重要的一步。
常见问题
文章中显示的媒体不属于Analytics Vidhya,是根据作者的选择使用的。





