最强大的机器学习模型解析(Transformers, CNNs, RNNs, GANs …)
最强大的机器学习模型解析' can be condensed to '机器学习模型解析' which means 'analysis of powerful machine learning models'.

机器学习是一个庞大的领域,要找到一个能够概述当前技术前沿的模型和技术的来源是理所当然的困难。话虽如此,本文将更多地进行概念性探索,而不是对这些模型的具体科学分析。事实上,我实际上建议如果可能的话,深入研究每一个模型。我还想提供这些模型在实践中的使用示例,因为在我看来,理论应该始终与实践联系在一起。如果我遗漏了任何信息,请随时提供反馈并要求更多。
在开始之前,这里是要涵盖的模型列表。
- CNNs(卷积神经网络)
- RNNs(循环神经网络)
- Transformers
- GANs(生成对抗网络)
CNNs
CNN(卷积神经网络)是一种在拓扑数据上表现出色并以某种方式进行了改进以更好地进行模式检测的神经网络(Arthur Arnx)。那么它与其他神经网络有什么不同呢?首先,让我简要概述一下神经网络是什么。
简而言之,神经网络是一个处理输入数据并产生输出的节点“映射”。它由层组成,将一个节点集合映射为另一个节点集合,将输入传播和转化为结果。传播是通过权重进行的,这些权重是在每一次传播步骤中改变我们的输入以产生我们期望的结果的值。在每次传播步骤之后,应用一个偏置。权重和偏差是我们真正寻找的东西:它们是训练网络时改变的数字。

然而,CNN有何特别之处呢?区分CNN的是它在其层堆栈中利用了卷积 层。这并不意味着CNN不能有其他类型的层(通常是有的),但卷积使其特殊。以下是这个层的工作原理。
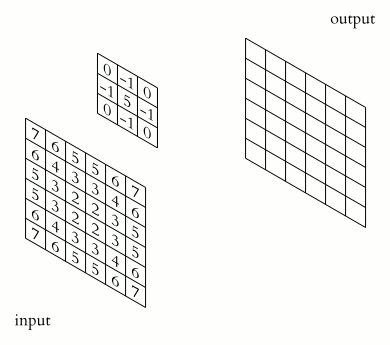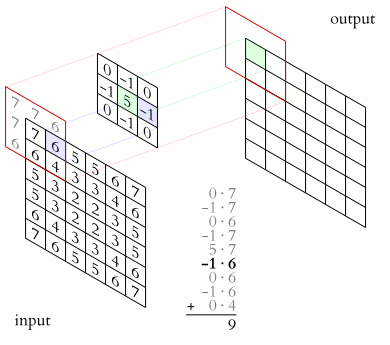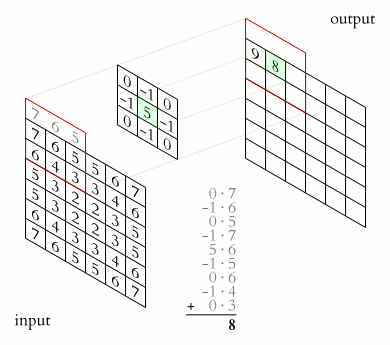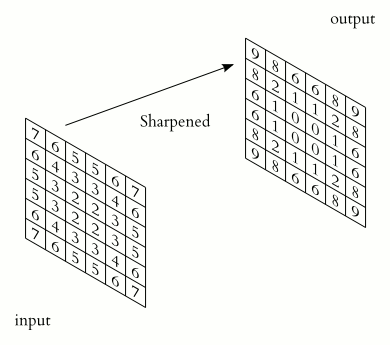
如果你把图像中的每个像素都看作亮度值,那么图像只是一个由数字组成的二维矩阵。卷积将对这个矩阵应用一个卷积核,从而产生一个输出矩阵。卷积核只是一个在图像的每个区域上起到过滤器作用的较小矩阵。
较小的矩阵“步进”通过图像的较大矩阵以产生一个输出矩阵。
这里有几个关键的观点。
- 卷积核在某种程度上应用于图像的每个像素及其周围区域,但在整个过程中保持不变。这是因为卷积核旨在检测该像素区域内的某种模式或特征。
- 卷积核通常比图像本身要小得多,这对于训练非常有帮助。
- 卷积核的背后的思想是任何图像都可以被分解为一组模式。例如,假设我们有一张脸。想象一下,有一个能够检测圆的卷积核。它的输出将在图像的顶部附近包含2个明亮的斑点(它检测到的眼睛)。现在想象一下,还有一个可以检测两条线紧挨在一起的卷积核。输出将在底部附近有一个明亮的斑点(它检测到的嘴巴)。最后,想象一下,最后一个应用的卷积核可以检测到这2个圆和底部的2条线的组合。那么它将识别出这张脸。
- 卷积层可以应用多个这样的卷积核来生成多个新图像。然后将它们堆叠在一起并向前传递到网络中。然后,另一个卷积层将有另一组要应用的卷积核。
- CNN通常还包含池化层,用于减小图像的大小和复杂度。
显然,我在这里错过了更多的细节和数学,但是卷积神经网络(CNNs)背后的主要直觉在于卷积核。
一些使用CNNs的流行工具和产品包括Google Photos,DeepMind的AlphaGo和特斯拉的Autopilot系统。
循环神经网络(RNNs)
正如您所看到的,CNNs主要用于图像处理。另一方面,RNNs主要用于自然语言处理(NLP)和一些其他领域,如时间序列分析。为了理解RNNs背后的架构,让我们首先强调一下使用简单神经网络进行NLP时的一些问题。让我们来看一个标准的NLP问题 – 文本自动完成。我们模型的输入是一段文本,输出是另一段文本。问题在于我们的输入是一个可变大小的(可以是几个词或很多词),而简单的神经网络通常有一个固定的输入大小。另一个问题是捕捉输入中单词之间的复杂关系以产生正确的输出。请记住,英语中有成千上万的单词,而这些单词在句子中的顺序并不一定改变意义。那么,如何确保句子“The fluffy cat came here on Sunday”与“On Sunday, the cat which was fluffy came here”相似,但与“The Sunday came here on a fluffy cat”不同?
RNNs的直觉来自于信息在其中流动的方式。让我们以一个句子为例,看看RNN如何处理它 – “The cat eats”。
让我们将句子看作一个词序列 – “The”,“cat”和“eats”(实际上可能表示为一系列数字或向量)。RNN现在将按顺序处理这个序列(这就是名称中“循环”部分的含义)。首先,它将接收单词“The”并通过自己的一组权重和偏差生成一些输出x1。然后,它将取x1和序列中的下一个单词 – “cat”,将其通过相同的一组权重和偏差传递,得到下一个输出x2。然后,它将取x2和序列中的下一个单词 – “eats”,得到下一个输出x3。通过这种方式,您可以看到RNN如何将其先前的输出和下一个输入结合起来,产生一些新的输出。RNN的当前“状态”称为隐藏状态。以下是一段动画,可能会帮助您从Michael Phi撰写的一篇很棒的文章中建立这种直觉。

这如何用于预测您提问后的下一个单词呢?嗯,想象一下每个输出 – x1,x2,x3实际上代表一个新的单词。我们可以训练网络,使输出实际上是下一个单词的预测。所以,让我们再次看一下我们的句子被处理的过程。
“The” -> 通过我们的模型 -> 产生x0,我们训练我们的模型,使x0能够正确地推断为“cat”
“cat”和先前的输出x0 -> 通过我们的模型 -> 产生x1,经过训练后,x1能够正确地推断为“eats”
“eats”和先前的输出x1 -> 通过我们的模型 -> 产生x2。我们发现x2现在代表着单词“tuna”!我们可以将其用于我们的下一个“输入”
“tuna”和先前的输出x2 -> 通过我们的模型 -> 产生x3……依此类推
RNNs的主要直觉在于:
- RNNs始终通过这个隐藏状态跟踪先前的信息,并捕捉单词之间的关系,或者说任何顺序数据的关系。
- 相同的模型逐个地应用于序列的每个部分,使得RNNs可以进行训练(而不是让一个庞大的模型一次处理整个输入)。
在这个方法中,您可能已经能够想象到一些问题。一旦文本变得很长,我们最初的几个单词几乎不对当前的隐藏状态产生贡献,这并不理想。此外,我们被迫按顺序进行处理,因此我们的处理和训练速度都受到算法本身的限制。
尽管如此,这些强大模型还有很多值得探索的地方,所以我鼓励您深入了解!
一些使用RNN的热门工具和产品包括Google翻译、OpenAI的GPT2和Spotify的推荐系统。
Transformer
Transformer!这是当前机器学习领域的热门话题。GPT4和BERT(Google自己的高级语言模型)都基于Transformer架构。那么它们是怎样的呢?
嗯,Transformer主要用于NLP问题,就像RNN一样,所以它们必须解决与我之前描述的语言处理相关的类似问题。然而,有一些关键思想与RNN有所不同,可以缓解这些问题。
- 位置编码 – 虽然序列在语言中的重要性在RNN中通过隐藏状态自然得到保留,但Transformer直接将这些信息嵌入到输入中。位置编码被添加到词嵌入(单词的向量表示)中,确保捕捉到每个单词在句子中的位置。因此,“dog”的表示会根据它在文本中的位置而改变。
- 庞大的训练数据集规模 – 为了利用位置编码的好处,Transformer必须在庞大的数据集上进行训练。这些不同的词序差异被捕捉到数据中,因此如果不看到各种不同的顺序和词类型的可能性,模型将无法发挥最佳性能。
- 自注意力 – 模型学会更关注某些词及其与输入中的每个其他词的关系。毕竟,一些词在预测或翻译中会承载更多的意义和能量,特别是如果与其他词组合在一起。它是如何学会做到这一点的呢?同样,是通过庞大的训练数据集规模和其架构。
然而,Transformer背后的架构稍微复杂,很难在这么短的文章中解释清楚。尽管如此,我将尝试给您提供一个非常高层次的概述。Transformer由解码器和编码器组成。编码器由一堆相同的层组成,其作用是处理文本并为解码器提供输入,以捕捉文本的最重要信息。解码器的作用是接收此输入并产生我们期望的输出,类似于一堆相同层的类似过程。下面是一个展示这种架构的图示,附有一篇很好的文章(作者为Ketan Doshi)链接,详细介绍了这个主题。
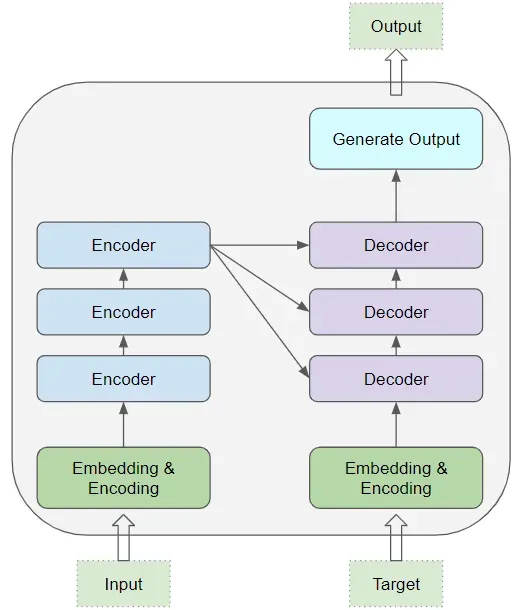
我强烈推荐您深入研究这个主题,特别是“自注意力”机制,它是Transformer的核心。
生成对抗网络(GAN)
生成对抗网络(GAN)基本上是指两个相互竞争的模型。GAN通常指的是训练这些模型的学习方法,而不是模型本身。实际上,两个模型的架构对于概念本身并不是非常重要,只要一个是生成模型,另一个是分类器。
让我们从描述训练模型的标准监督学习技术开始。
- 我们将一些输入提供给模型,它会产生一些输出
- 我们将这个输出与期望的输出进行比较,并以某种方式更新模型以取得更好的效果
然而,当我们想要创建一个生成逼真输出的模型时,这就出现了问题(例如图像生成或音乐生成)。这就是GAN的用武之地。在GAN中,我们有两个模型,一个是生成器模型,另一个是判别器模型。
以生成图像的生成器模型为例。我们首先让这个模型生成一些虚假图像,然后找到一些真实图像。然后,我们将所有这些图像的组合输入到我们的判别器模型中,判别器模型将它们分类为真实或虚假。如果我们的生成器模型表现良好,判别器模型会被难倒,并且大约一半的时间得出正确答案。显然,这在开始时不会发生(我们的判别器通常会进行轻微的预训练),因此以监督学习的方式(我们自己知道哪些图像是真实的或虚假的),我们训练判别器模型在下一次做得更好。我们还可以训练生成器模型,因为我们知道它能够欺骗判别器模型的程度。训练完成时,我们可以生成能够以约50%的概率欺骗判别模型的图像。
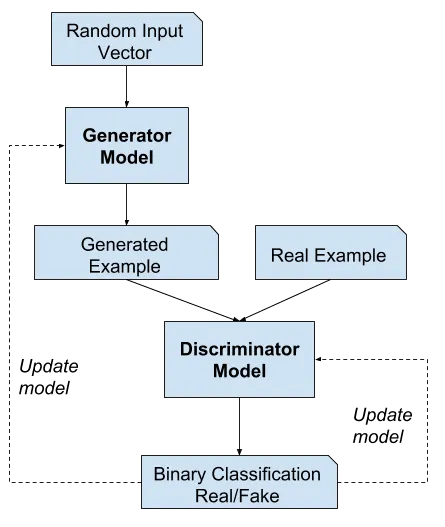
一些使用GAN在现实世界中的例子包括Runway ML、Midjourney艺术生成(请查看我的关于艺术的先前文章!)以及OpenAI的DALL * E。





