利用AWS上的生成式AI自动从放射学报告的发现中生成印象
利用AWS上的生成式AI生成印象
放射学报告是详尽的、冗长的文件,描述和解释放射学成像检查结果。在典型的工作流中,放射科医生监督、阅读和解释图像,然后简要总结关键发现。总结(或印象)是报告中最重要的部分,因为它帮助临床医生和患者专注于包含临床决策所需信息的报告的关键内容。创建清晰而有影响力的印象比简单地重申发现需要更多的努力。整个过程因此费时费力且容易出错。医生通常需要多年的培训才能积累足够的专长,写出简明扼要且信息丰富的放射学报告总结,进一步凸显了自动化该过程的重要性。此外,自动生成报告发现总结对于放射学报告至关重要。它可以将报告翻译成易读的人类语言,从而减轻患者阅读冗长和晦涩报告的负担。
为了解决这个问题,我们提出使用生成式人工智能(Generative AI),这是一种可以创造新内容和想法的人工智能类型,包括对话、故事、图像、视频和音乐。生成式人工智能由机器学习(ML)模型驱动,这些模型是在大量数据上进行预训练的非常大的模型,通常被称为基础模型(Foundation Models,FMs)。机器学习的最新进展(特别是基于Transformer的神经网络架构的发明)导致了包含数十亿个参数或变量的模型的兴起。本文提出的解决方案使用预训练的大型语言模型(LLM)进行微调,以根据放射学报告中的发现生成总结。
本文演示了使用AWS服务为放射学报告总结的任务进行公开可用的LLM的微调策略。LLM在自然语言理解和生成方面展示了显著的能力,作为基础模型,可以适应各种领域和任务。使用预训练模型有很多好处。它降低了计算成本,减少了碳排放,并且可以使用最先进的模型,而不需要从头开始训练一个模型。
我们的解决方案使用FLAN-T5 XL FM,使用Amazon SageMaker JumpStart,这是一个提供算法、模型和机器学习解决方案的机器学习中心。我们演示了如何在Amazon SageMaker Studio的笔记本中完成此任务。微调预训练模型涉及对特定数据进行进一步训练,以提高在不同但相关的任务上的性能。本解决方案涉及对FLAN-T5 XL模型进行微调,该模型是T5(文本到文本转换转换器)通用LLM的增强版本。T5将自然语言处理(NLP)任务重新构建为统一的文本到文本格式,与只能输出类别标签或输入段落的BERT风格模型形成对比。它在来自MIMIC-CXR数据集的91,544份自由文本放射学报告上进行了总结任务的微调。
解决方案概述
在本节中,我们讨论我们解决方案的关键组成部分:选择任务的策略,对LLM进行微调,以及评估结果。我们还说明了解决方案架构和实施解决方案的步骤。
确定任务的策略
有多种策略可以解决自动化临床报告总结的任务。例如,我们可以使用专门针对临床报告进行预训练的语言模型。或者,我们可以直接对公开可用的通用语言模型进行微调,以执行临床任务。在从头开始训练语言模型成本过高的情况下,使用微调的域无关模型可能是必要的。在本解决方案中,我们演示了使用FLAN-T5 XL模型进行微调,将其用于放射学报告的总结任务。以下图示说明了模型的工作流程。

典型的放射学报告组织有序且简洁。这类报告通常有三个关键部分:
- 背景 – 提供有关患者人口统计学信息的一般信息,包括患者的基本信息、临床历史和相关医疗历史以及检查程序的详细信息
- 发现 – 提供详细的检查诊断和结果
- 印象 – 简要总结最显著的发现或对发现的解释,并根据观察到的异常进行重要性评估和可能的诊断
使用放射学报告中的发现部分,该解决方案生成印象部分,对应于医生的总结。下图是放射学报告的示例。

针对临床任务微调通用语言模型(LLM)
在此解决方案中,我们对FLAN-T5 XL模型进行微调(调整模型的所有参数并针对任务进行优化)。我们使用临床领域数据集MIMIC-CXR对模型进行微调,MIMIC-CXR是一个公开可用的胸部X光照片数据集。要通过SageMaker Jumpstart对该模型进行微调,必须以{提示,完成}对的形式提供标记的示例。在这种情况下,我们使用MIMIC-CXR数据集中原始报告的{发现,印象}对。对于推断,我们使用以下示例中的提示:

该模型在具有64个虚拟CPU和488 GiB内存的加速计算ml.p3.16xlarge实例上进行了微调。为了验证,随机选择了数据集的5%。使用微调的SageMaker训练作业的经过时间为38,468秒(大约11小时)。
评估结果
完成训练后,评估结果至关重要。为了对生成的印象进行定量分析,我们使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation),这是用于评估摘要的最常用的度量标准。该度量标准将自动生成的摘要与参考摘要或一组参考(人工生成的)摘要或翻译进行比较。ROUGE1指的是候选项(模型的输出)与参考摘要之间的单词(单个词)重叠。ROUGE2指的是候选项和参考摘要之间的双词(两个词)重叠。ROUGEL是一个句子级度量标准,指的是两个文本片段之间的最长公共子序列(LCS)。它忽略文本中的换行符。ROUGELsum是一个摘要级度量标准。对于该度量标准,文本中的换行符不会被忽略,而是被解释为句子边界。然后计算每对参考和候选句子之间的LCS,然后计算并集LCS。对于一组给定的参考和候选句子的这些分数的聚合,计算平均值。
演示和架构
总体解决方案架构如下图所示,主要包括使用SageMaker Studio的模型开发环境,使用SageMaker端点进行模型部署,以及使用Amazon QuickSight的报告仪表板。
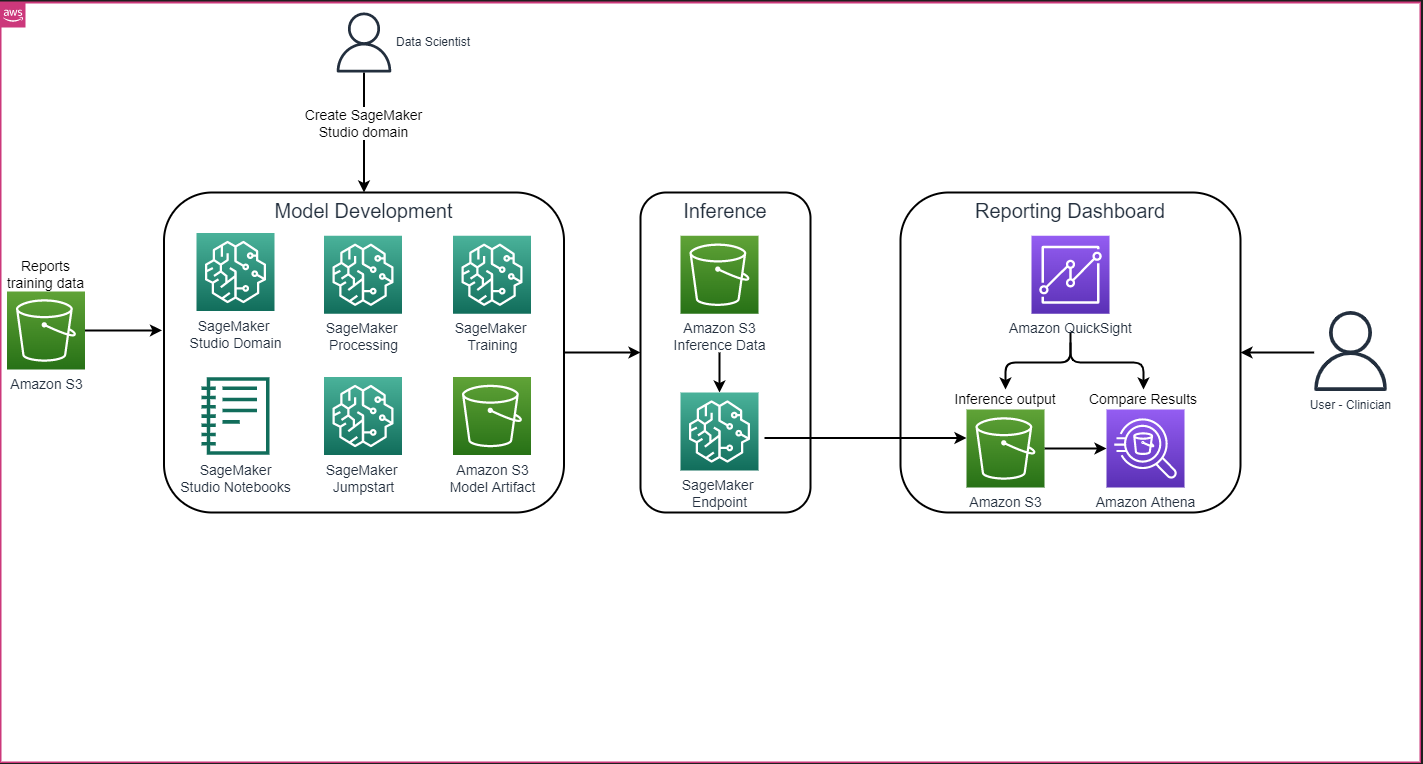
在接下来的几节中,我们将通过SageMaker Python SDK演示使用SageMaker JumpStart对特定领域任务的LLM进行微调。具体来说,我们将讨论以下主题:
- 设置开发环境的步骤
- 对模型进行微调和评估的放射学报告数据集概述
- 使用SageMaker Python SDK以编程方式进行FLAN-T5 XL模型的微调
- 预训练和微调模型的推断和评估
- 预训练模型和微调模型结果的比较
该解决方案可在AWS的GitHub存储库上获取。
先决条件
要开始使用SageMaker Studio,您需要一个AWS帐户。如果您还没有SageMaker Studio的用户配置文件,您需要为其创建一个。
本文中使用的训练实例类型是ml.p3.16xlarge。请注意,p3实例类型需要增加服务配额限制。
MIMIC CXR数据集可以通过数据使用协议访问,该协议需要用户注册并完成认证过程。
设置开发环境
要设置开发环境,您需要创建一个S3存储桶,配置一个笔记本,创建端点并部署模型,以及创建一个QuickSight仪表板。
创建S3存储桶
创建一个名为llm-radiology-bucket的S3存储桶,用于托管训练和评估数据集。这也将用于在模型开发过程中存储模型构件。
配置笔记本
完成以下步骤:
- 从SageMaker控制台或AWS命令行界面(AWS CLI)启动SageMaker Studio。
有关加入Amazon SageMaker域的更多信息,请参阅加入Amazon SageMaker域。
- 为清理报告数据和模型微调创建一个新的SageMaker Studio笔记本。我们使用一个带有Python 3内核的ml.t3.medium 2vCPU+4GiB笔记本实例。
- 在笔记本中安装相关软件包,如
nest-asyncio、IPyWidgets(用于Jupyter笔记本的交互式小部件)和SageMaker Python SDK:
!pip install nest-asyncio==1.5.5 --quiet
!pip install ipywidgets==8.0.4 --quiet
!pip install sagemaker==2.148.0 --quiet创建端点并部署用于推理的模型
要对预训练和微调的模型进行推理,可以在笔记本中创建端点并部署每个模型,具体步骤如下:
- 使用Model类从模型创建一个可以部署到HTTPS端点的模型对象。
- 使用模型对象的预构建
deploy()方法创建一个HTTPS端点:
from sagemaker import model_uris, script_uris
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
# 检索预训练模型的URI
pre_trained_model_uri =model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="inference")
large_model_env = {"SAGEMAKER_MODEL_SERVER_WORKERS": "1", "TS_DEFAULT_WORKERS_PER_MODEL": "1"}
pre_trained_name = name_from_base(f"jumpstart-demo-pre-trained-{model_id}")
# 创建预训练模型的SageMaker模型实例
if ("small" in model_id) or ("base" in model_id):
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
entry_point="inference.py",
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
)
else:
# 对于那些较大的模型,我们已经重新打包了推理脚本和模型构件
# 不需要Model的`source_dir`参数
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# 部署预训练模型。请注意,我们在通过Model类部署模型时需要传递Predictor类,
# 以便能够通过SageMaker API运行推理
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)创建QuickSight仪表板
创建一个QuickSight仪表板,使用Amazon Simple Storage Service (Amazon S3)中的Athena数据源来比较推理结果与基准结果。以下截图显示了我们的示例仪表板。 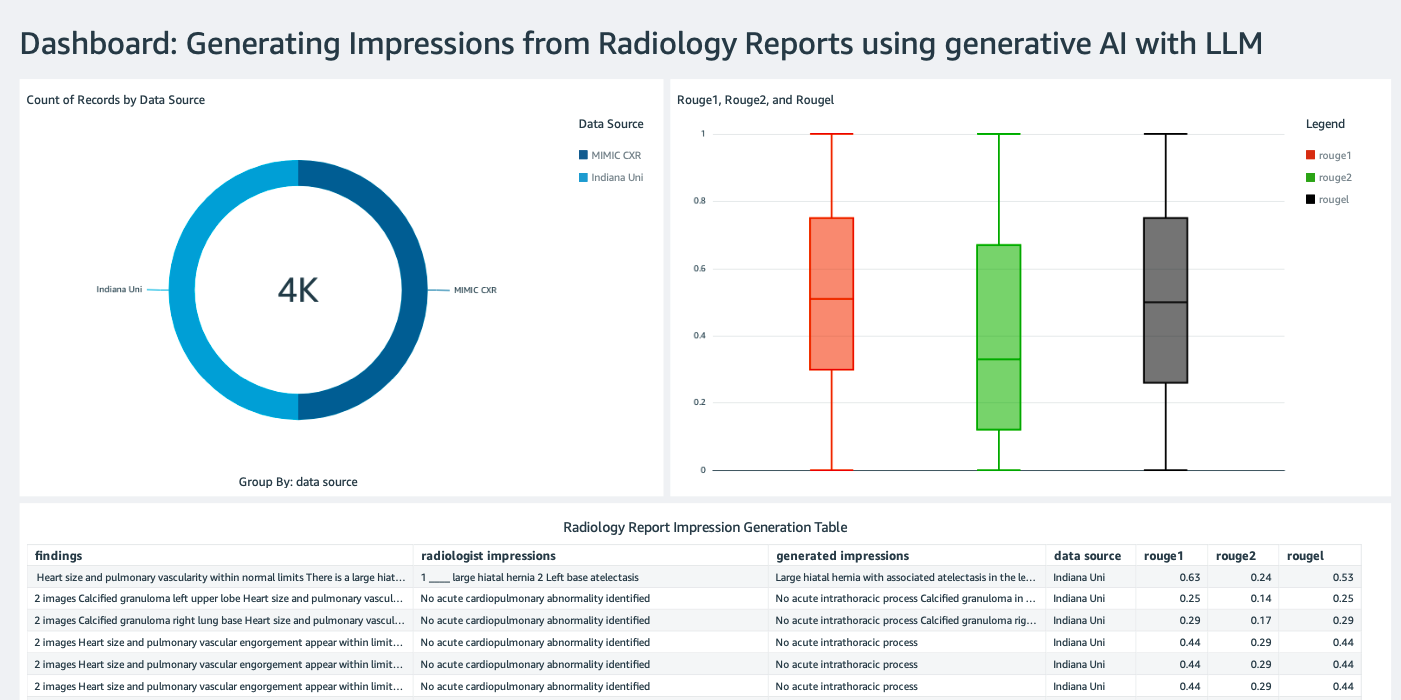
放射学报告数据集
模型现在已经进行了微调,所有模型参数都在从MIMIC-CXR v2.0数据集下载的91,544份报告上进行了调整。由于我们仅使用放射学报告文本数据,因此我们只从MIMIC-CXR网站下载了一个压缩的报告文件(mimic-cxr-reports.zip)。现在,我们在来自该数据集的另一个分离的子集的2,000份报告(称为dev1数据集)上评估微调后的模型。我们使用另外2,000份放射学报告(称为dev2)来评估来自印第安纳大学医院网络的胸部X射线收集的微调后的模型。所有数据集都以JSON文件格式读取,并上传到新创建的S3存储桶llm-radiology-bucket。请注意,默认情况下,所有数据集都不包含任何受保护的健康信息(PHI);所有敏感信息都由提供者用三个连续的下划线(___)替换。
使用SageMaker Python SDK进行微调
在微调过程中,将model_id指定为SageMaker JumpStart模型列表中的huggingface-text2text-flan-t5-xl。将training_instance_type设置为ml.p3.16xlarge,将inference_instance_type设置为ml.g5.2xlarge。从S3存储桶中读取以JSON格式存储的训练数据。下一步是使用所选的model_id提取SageMaker JumpStart资源URI,包括image_uri(Docker镜像的Amazon Elastic Container Registry(Amazon ECR)URI),model_uri(预训练模型的Amazon S3 URI)和script_uri(训练脚本):
from sagemaker import image_uris, model_uris, script_uris
# 训练实例将使用此镜像
train_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # 从model_id中自动推断
model_id=model_id,
model_version=model_version,
image_scope="training",
instance_type=training_instance_type,
)
# 预训练模型
train_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="training"
)
# 在训练实例上执行的脚本
train_script_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="training"
)
output_location = f"s3://{output_bucket}/demo-llm-rad-fine-tune-flan-t5/"此外,还设置了一个输出位置,作为S3存储桶中的一个文件夹。
只有一个超参数epochs被更改为3,其余都设置为默认值:
from sagemaker import hyperparameters
# 检索微调模型的默认超参数
hyperparameters = hyperparameters.retrieve_default(model_id=model_id, model_version=model_version)
# 我们将使用自定义值覆盖一些默认超参数
hyperparameters["epochs"] = "3"
print(hyperparameters)定义并列出要跟踪的训练指标,如eval_loss(用于验证损失)、loss(用于训练损失)和epoch:
from sagemaker.estimator import Estimator
from sagemaker.utils import name_from_base
model_name = "-".join(model_id.split("-")[2:]) # 获取ID中最有信息量的部分
training_job_name = name_from_base(f"js-demo-{model_name}-{hyperparameters['epochs']}")
print(f"{bold}作业名称:{unbold}{training_job_name}")
training_metric_definitions = [
{"Name": "val_loss", "Regex": "'eval_loss': ([0-9\\.]+)"},
{"Name": "train_loss", "Regex": "'loss': ([0-9\\.]+)"},
{"Name": "epoch", "Regex": "'epoch': ([0-9\\.]+)"},
]我们使用之前识别出的SageMaker JumpStart资源URI(image_uri,model_uri,script_uri)在训练数据集上创建一个估算器,并通过指定数据集的S3路径对其进行微调。Estimator类需要一个entry_point参数。在这种情况下,JumpStart使用transfer_learning.py。如果未设置此值,训练作业将无法运行。
# 创建SageMaker Estimator实例
sm_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
model_uri=train_model_uri,
source_dir=train_script_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
volume_size=300,
max_run=360000,
hyperparameters=hyperparameters,
output_path=output_location,
metric_definitions=training_metric_definitions,
)
# 在给定的S3路径上启动SageMaker训练作业
# 训练作业可能需要几个小时,建议设置wait=False,
# 并通过SageMaker控制台监控作业状态
sm_estimator.fit({"training": train_data_location}, job_name=training_job_name, wait=True)该训练作业可能需要几个小时才能完成,因此建议将wait参数设置为False,并在SageMaker控制台上监视训练作业的状态。 使用TrainingJobAnalytics函数在不同的时间戳上跟踪训练指标:
from sagemaker import TrainingJobAnalytics
# 在运行此单元格之前等待几分钟以启动作业
# 可以在作业仍在运行时调用此函数
df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe()部署推理端点
为了进行比较,我们为预训练模型和微调模型都部署推理端点。
首先,使用model_id检索推理Docker镜像URI,并使用此URI创建预训练模型的SageMaker模型实例。通过使用模型对象的预构建deploy()方法来部署预训练模型,创建一个带有HTTPS的端点。为了通过SageMaker API进行推理,请确保传递Predictor类。
from sagemaker import image_uris
# 检索推理docker镜像URI。这是基本的HuggingFace容器镜像
deploy_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # 从model_id自动推断
model_id=model_id,
model_version=model_version,
image_scope="inference",
instance_type=inference_instance_type,
)
# 检索预训练模型的URI
pre_trained_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# 部署预训练模型。请注意,当我们通过Model类部署模型时,需要传递Predictor类,
# 以便能够通过SageMaker API运行推理
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)重复上述步骤,创建微调模型的SageMaker模型实例并创建一个端点来部署模型。
评估模型
首先,设置摘要文本的长度、模型输出的数量(如果需要生成多个摘要,则应大于1)和beam搜索的数量。
将推理请求构建为JSON载荷,并使用它查询预训练模型和微调模型的端点。
计算聚合的ROUGE得分(ROUGE1、ROUGE2、ROUGEL、ROUGELsum),如前所述。
比较结果
下表显示了dev1和dev2数据集的评估结果。在dev1(来自MIMIC CXR放射学报告的2,000个发现)上,聚合平均ROUGE1和ROUGE2得分与预训练模型相比,大约提高了38个百分点。对于dev2,ROUGE1和ROUGE2得分分别提高了31个百分点和25个百分点。总体而言,微调使得在dev1和dev2数据集上的ROUGELsum得分分别提高了38.2个百分点和31.3个百分点。
|
评估 数据集 |
预训练模型 | 微调模型 | ||||||
| ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | ROUGE1 | ROUGE2 | ROUGEL | ROUGELsum | |
dev1 |
0.2239 | 0.1134 | 0.1891 | 0.1891 | 0.6040 | 0.4800 | 0.5705 | 0.5708 |
dev2 |
0.1583 | 0.0599 | 0.1391 | 0.1393 | 0.4660 | 0.3125 | 0.4525 | 0.4525 |
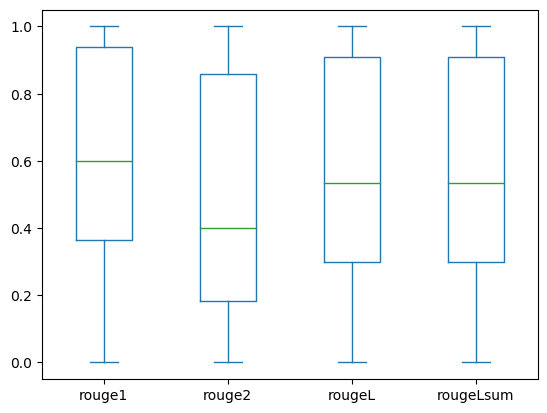
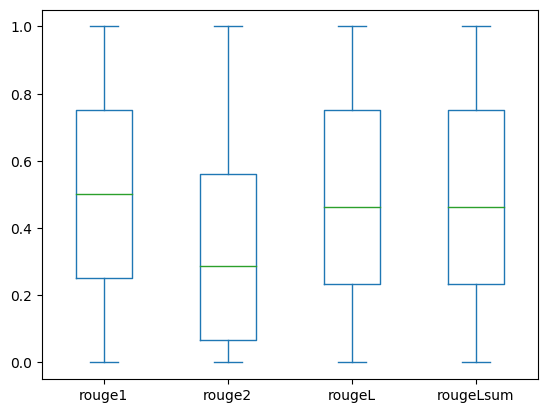
以下箱线图显示了使用微调模型评估的dev1和dev2数据集的ROUGE得分分布。
 |
 |
(a): dev1 |
(b): dev2 |
以下表格显示了评估数据集的ROUGE得分具有大致相同的中位数和平均值,因此它们是对称分布的。
| 数据集 | 得分 | 计数 | 平均值 | 标准差 | 最小值 | 25% 分位数 | 50% 分位数 | 75% 分位数 | 最大值 |
dev1 |
ROUGE1 | 2000.00 | 0.6038 | 0.3065 | 0.0000 | 0.3653 | 0.6000 | 0.9384 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.4798 | 0.3578 | 0.0000 | 0.1818 | 0.4000 | 0.8571 | 1.0000 | |
| ROUGE L | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
| ROUGELsum | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
dev2 |
ROUGE 1 | 2000.00 | 0.4659 | 0.2525 | 0.0000 | 0.2500 | 0.5000 | 0.7500 | 1.0000 |
| ROUGE 2 |





