整理数据集偏移的框架
整理数据集偏移的框架' can be condensed as '数据集偏移框架'.
回顾模型退化的原因
与Marco Dalla Vecchia合作作为图片创建者
我们训练模型并使用它们来预测给定一组输入的某些结果。我们都知道这就是机器学习的游戏。我们对训练模型有很多了解,以至于现在它们已经发展成为AI,这是有史以来最大的智能水平。但是在使用它们时,我们并没有那么领先,我们继续探索和理解模型部署之后的每个重要方面。
因此,今天我们将讨论模型性能漂移的问题(或者简称为模型漂移),这也经常被称为模型失效或模型退化。我们所指的是我们的机器学习模型所提供的预测质量的问题。无论是分类还是数值,我们都关心预测与实际类别或值之间的差距。当我们部署模型时,如果这些预测的质量与之前相比下降,我们就谈论模型性能漂移。在文献中,您可能会找到此主题的其他术语,但至少在我们当前的对话中,还是使用模型性能漂移或简单的模型漂移这个术语。
我们所知道的
已经有几篇博客、书籍和许多论文对模型漂移的核心概念进行了探索和解释,所以我们首先要进入这个当前的画面。我们主要将这些想法整理成了协变量漂移、先验漂移和条件漂移的概念。后者通常也被称为概念漂移。已知这些漂移是模型漂移的主要原因(记住,预测质量下降)。其摘要定义如下:
- 协变量漂移:在没有改变P(Y|X)的情况下,P(X)的分布发生变化。这意味着输入特征的分布发生了变化,其中一些漂移可能导致模型漂移。
- 先验漂移:P(Y)的分布发生变化。在这里,标签或数值输出变量的分布发生变化。如果输出变量的概率分布发生变化,当前模型对给定预测的不确定性将很大,因此它可能会很容易地漂移。
- 条件漂移(又称概念漂移):条件分布P(Y|X)发生变化。这意味着对于给定的输入,输出变量的概率已经改变。据我们目前所知,这种漂移通常让我们没有太多机会保持预测的质量。真的吗?
许多来源列出了这些数据集漂移发生的例子。研究的一个核心机会是在不需要新标签的情况下检测这些类型的漂移[1, 2, 3]。最近发布了一些有趣的指标,以无监督的方式监控模型的预测性能[2, 3]。它们确实受到了不同数据集漂移概念的启发,并且相当准确地反映了数据的真实概率分布的变化。因此,我们将深入研究这些漂移的理论。为什么呢?因为也许我们可以对这些定义进行整理。通过整理,我们可能能够更轻松地向前推进,或者更清楚地理解整个框架。
为了做到这一点,让我们回到开始,慢慢推导故事。喝杯咖啡,慢慢阅读,跟着我一起。或者,不要漂移!
真实模型和估计模型
我们训练的机器学习模型试图使我们接近一个真实但未知的关系或函数,它将某个输入X映射到一个输出Y。我们自然区分真实未知模型和估计模型。然而,估计模型与真实未知模型的行为是相关的。也就是说,如果真实模型发生变化,而估计模型对这些变化不具有鲁棒性,那么估计模型的预测将不太准确。
我们可以监控的性能涉及估计函数,但模型漂移的原因在于真实模型的变化。
- 什么是真实模型?真实模型基于所谓的条件分布P(Y|X)。这是给定输入时输出的概率分布。
- 什么是估计模型?这是一个函数ê(x),它特别估计了P(Y|X=x)的期望值。这个函数是与我们的机器学习模型相关联的函数。
以下是这些元素的可视化表示:
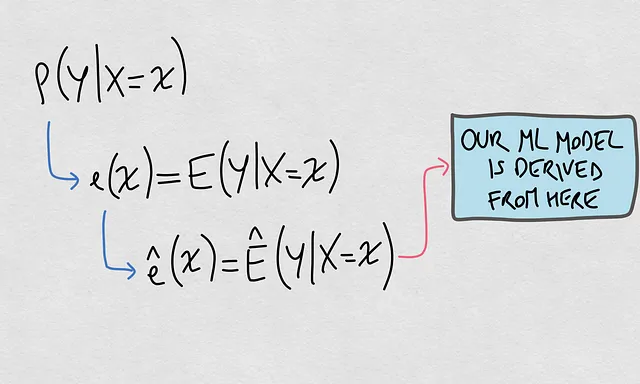
很好,现在我们澄清了这两个元素,我们准备组织所谓的数据集转换背后的思想以及这些概念之间的联系。
新的安排
模型漂移的全局原因
我们的主要目标是了解我们估计模型的漂移原因。由于我们已经理解了估计模型和条件概率分布之间的关系,我们可以在这里陈述我们之前已经知道的内容:我们估计模型漂移的全局原因是P(Y|X)的变化。
这个基本且表面上容易的原因比我们想象的更基础。我们假设我们的估计模型是对真实模型的良好反映。真实模型受P(Y|X)的影响。因此,如果P(Y|X)发生变化,我们的估计模型很可能会漂移。我们需要注意我们在推理中所遵循的路径,这个路径在上面的图中已经展示出来了。
我们之前已经知道这一点,那么它有什么新的内容呢?新的东西是我们现在将P(Y|X)的变化称为全局原因,而不仅仅是一个原因。这将对其他原因形成一个层次结构。这个层次结构将有助于我们很好地定位关于其他原因的概念。
具体原因:全局原因的元素
知道全局原因在于P(Y|X)的变化,我们自然而然地会深入研究构成这个条件概率的元素。一旦我们确定了这些元素,我们将继续讨论模型漂移的原因。那么这些元素是什么?
我们一直都知道。条件概率在理论上定义为P(Y|X) = P(Y, X) / P(X),即联合概率除以X的边际概率。但是我们可以再次展开联合概率,然后我们得到了几个世纪以前我们就知道的神奇公式:
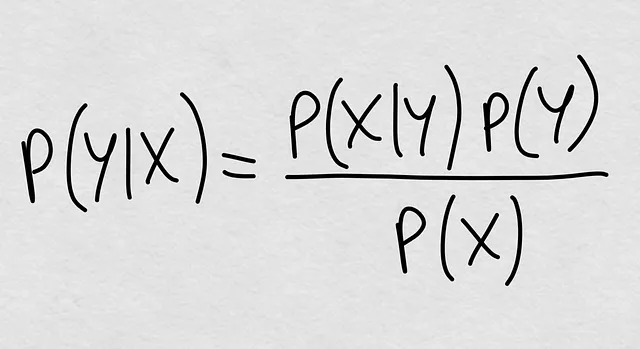
你已经看到我们要去哪里了吗?条件概率完全由三个元素定义:
- P(X|Y):逆条件概率
- P(Y):先验概率
- P(X):协变量的边际概率
因为这些是定义条件概率P(Y|X)的三个元素,我们可以得出第二个结论:如果P(Y|X)发生变化,这些变化来自定义它的三个元素中的至少一个。换句话说,P(Y|X)的变化由P(X|Y)、P(Y)或P(X)的任何变化定义。
也就是说,我们已经将我们当前的知识中的其他元素定位为模型漂移的具体原因,而不仅仅是P(Y|X)的并行原因。
回到本文的开头,我们列出了协变量转换和先验转换。我们可以注意到,还有另一个具体原因:逆条件分布P(X|Y)的变化。当我们谈论P(Y)的变化时,通常会提到这个分布,好像我们一般考虑了从Y到X的逆关系。
新的概念层次结构
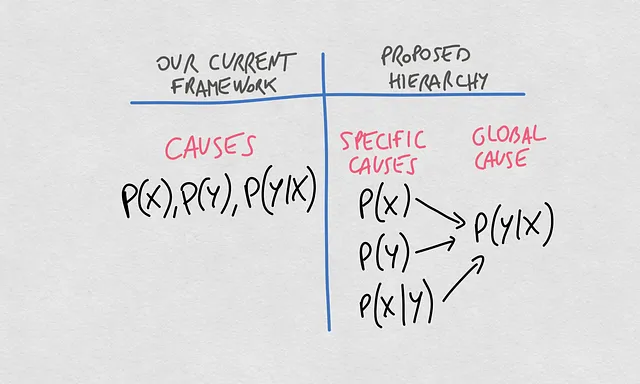
现在我们可以清楚地比较当前关于这些概念的思考和提出的层次结构。到目前为止,我们一直在讨论模型漂移的原因,通过确定不同的概率分布。主要的三个分布,P(X)、P(Y)和P(Y|X),被认为是我们的机器学习模型返回的预测质量漂移的主要原因。
我在这里提出的扭曲概念对概念进行了层次化。在这个概念中,估计关系X -> Y的模型的全局漂移的原因是条件概率P(Y|X)的变化。这些P(Y|X)的变化可以来自P(X)、P(Y)或P(X|Y)的变化。
让我们列举一些这个层次结构的含义:
- 我们可能会遇到P(X)发生变化的情况,但如果P(Y)和P(X|Y)也相应发生变化,那么P(Y|X)保持不变。
- 我们也可能会遇到P(X)发生变化的情况,但如果P(Y)或P(X|Y)没有相应发生变化,P(Y|X)将会发生变化。如果你之前对这个主题进行了一些思考,你可能已经看到,在某些情况下,我们会看到X的变化,而这些变化似乎并不完全独立于Y|X,所以最终,Y|X也会发生变化。在这里,P(X)是P(Y|X)变化的具体原因,而P(Y|X)又是模型漂移的全局原因。
- 前面两个陈述对P(Y)也成立。
由于这三个具体原因可能独立地发生变化,总体上,P(Y|X)的变化可以通过这些具体因素的变化共同解释。这可能是因为P(X)在这里稍微移动了一下,P(Y)在那里稍微移动了一下,然后这两个因素也使得P(X|Y)发生变化,最终共同导致P(Y|X)发生变化。
不要将P(X)和P(Y|X)视为相互独立的,P(X)是P(Y|X)的原因
在这一切中,估计的机器学习模型在哪里?
好的,现在我们知道所谓的协变量和先验偏移是条件偏移的原因,而不是与之平行的原因。条件偏移包括估计模型预测性能下降的一组具体原因。但是估计的模型实际上是一个决策边界或函数,而不是对所涉及概率的直接估计。那么这些原因对于真实的和估计的决策边界意味着什么?
让我们收集所有的要素,绘制连接所有要素的完整路径:

请注意,我们的机器学习模型可以通过分析或数值方法得出。此外,它可以作为参数化或非参数化表示。因此,我们的机器学习模型最终是决策边界或回归函数的估计,我们可以从预期条件值中得出。
这个事实对我们所讨论的原因有重要的影响。虽然P(X)、P(Y)和P(X|Y)中发生的大多数变化都会导致P(Y|X)和E(Y|X)的变化,但并不是所有的变化都一定意味着真实的决策边界或函数发生了变化。在这种情况下,如果估计的决策边界最初是准确的估计,那么估计的决策边界或函数仍然是有效的。看看下面的例子:
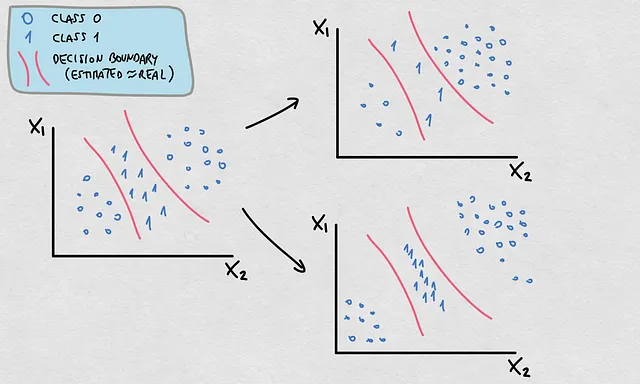
- 注意到P(Y)和P(X)发生了变化。点的密度和位置说明了不同的概率分布
- 这些变化使得P(Y|X)发生了变化
- 然而,决策边界仍然有效
这里有一个重要的一点。想象一下,我们只看P(X)的变化,而没有关于真实标签的信息。我们想知道预测的准确性如何。如果P(X)向决策边界的不确定区域移动,那么预测很可能是不准确的。因此,在协变量向决策边界的不确定区域移动的情况下,很可能也发生了条件偏移。但我们不会知道决策边界是否发生了变化。在这种情况下,我们可以量化P(X)发生的变化,这可以指示P(Y|X)发生了变化,但我们不会知道决策边界或回归函数发生了什么变化。以下是这个问题的表示:

既然我们已经说了这么多,现在是时候再说一句话了。当我们提到P(Y|X)的变化时,我们谈论的是条件转移。我们所说的概念漂移可能特指真实决策边界或回归函数的变化。在下面的示例中,我们可以看到一个典型的条件转移,其中决策边界发生了变化,但没有协变量或先验转移。事实上,这种变化来自于逆条件概率P(X|Y)的变化。
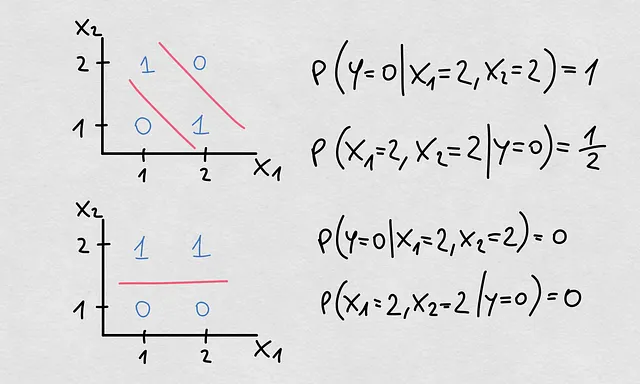
对我们当前监测方法的影响
我们关心了解这些原因,以便尽可能准确地开发监测我们机器学习模型性能的方法。对于现有的实际解决方案,这些提出的想法都不是坏消息。相反,通过这种新的概念层次结构,我们或许能够进一步努力检测模型性能退化的原因。我们有一些已经提出的方法和指标来监测我们模型的预测性能,主要是针对我们在这里列出的不同概念。然而,我们可能已经在指标的假设中混淆了这些概念[2]。例如,我们可能在假设中称之为“无条件转移”,但实际上可能是“决策边界没有变化”或“回归函数没有变化”。我们需要继续思考这个问题。
关于预测性能退化的更多内容
放大和缩小。我们已经深入研究了预测性能退化的原因框架。但是,我们还有另一个维度来讨论这个主题,即预测性能转移的类型。我们的模型因为这些列出的原因而受到影响,并且这些原因反映为不同形状的预测不一致性。主要有四种类型:偏差、斜率、方差和非线性转移。请查看这篇文章,了解硬币的另一面。
总结
在本文中,我们研究了模型性能退化的原因,并提出了一个基于我们之前已知概念的理论联系的框架。以下是主要观点:
- 概率P(Y|X)决定了真实的决策边界或函数。
- 估计的决策边界或函数被假设为对真实决策边界或函数的最佳近似。
- 估计的决策边界或函数就是机器学习模型。
- 机器学习模型可能会出现预测性能退化。
- 这种退化是由于P(Y|X)的变化引起的。
- P(Y|X)的变化是因为至少这些元素之一发生了变化:P(X)、P(Y)或P(X|Y)。
- 在没有决策边界或回归函数变化的情况下,P(X)和P(Y)可能会发生变化。
总的说来:如果机器学习模型发生漂移,那么P(Y|X)正在发生变化。反之则未必成立。
希望这些概念的框架只是机器学习预测性能退化这一重要主题的一个开端。虽然理论讨论仅仅是一种享受,但我相信这种联系将帮助我们在实践中更进一步地测量这些变化,同时优化所需的资源(样本和标签)。如果您对知识有其他贡献,请加入讨论。
是什么导致了您的模型在预测性能上发生漂移?
祝您思考愉快!
参考资料
[1] https://huyenchip.com/2022/02/07/data-distribution-shifts-and-monitoring.html
[2] https://www.sciencedirect.com/science/article/pii/S016974392300134X
[3]https://nannyml.readthedocs.io/en/stable/how_it_works/performance_estimation.html#performance-estimation-deep-dive
[4] https://medium.com/towards-data-science/understanding-dataset-shift-f2a5a262a766






