确保LLMs可靠的少样本提示选择
Reliable Few-Shot Prompt Selection for LLMs
作者:克里斯·莫克,乔纳斯·穆勒
在本文中,我们使用OpenAI的达芬奇大型语言模型(GPT-3/ChatGPT的基础模型)通过少量提示来尝试对大型银行的客户服务请求进行意图分类。按照常规做法,我们从可用的人工标注的请求示例数据集中获取少量提示示例以包含在提示模板中。然而,结果表明,由于现实世界的数据杂乱且容易出错,达芬奇模型的预测是不可靠的。通过手动修改提示模板以减少可能存在的噪音数据,可以稍微提高达芬奇模型在客户服务意图分类任务中的性能。如果我们改为使用像“自信学习”这样的以数据为中心的人工智能算法,只选择高质量的少量示例用于包含在提示模板中,达芬奇模型的预测结果将变得更加准确。
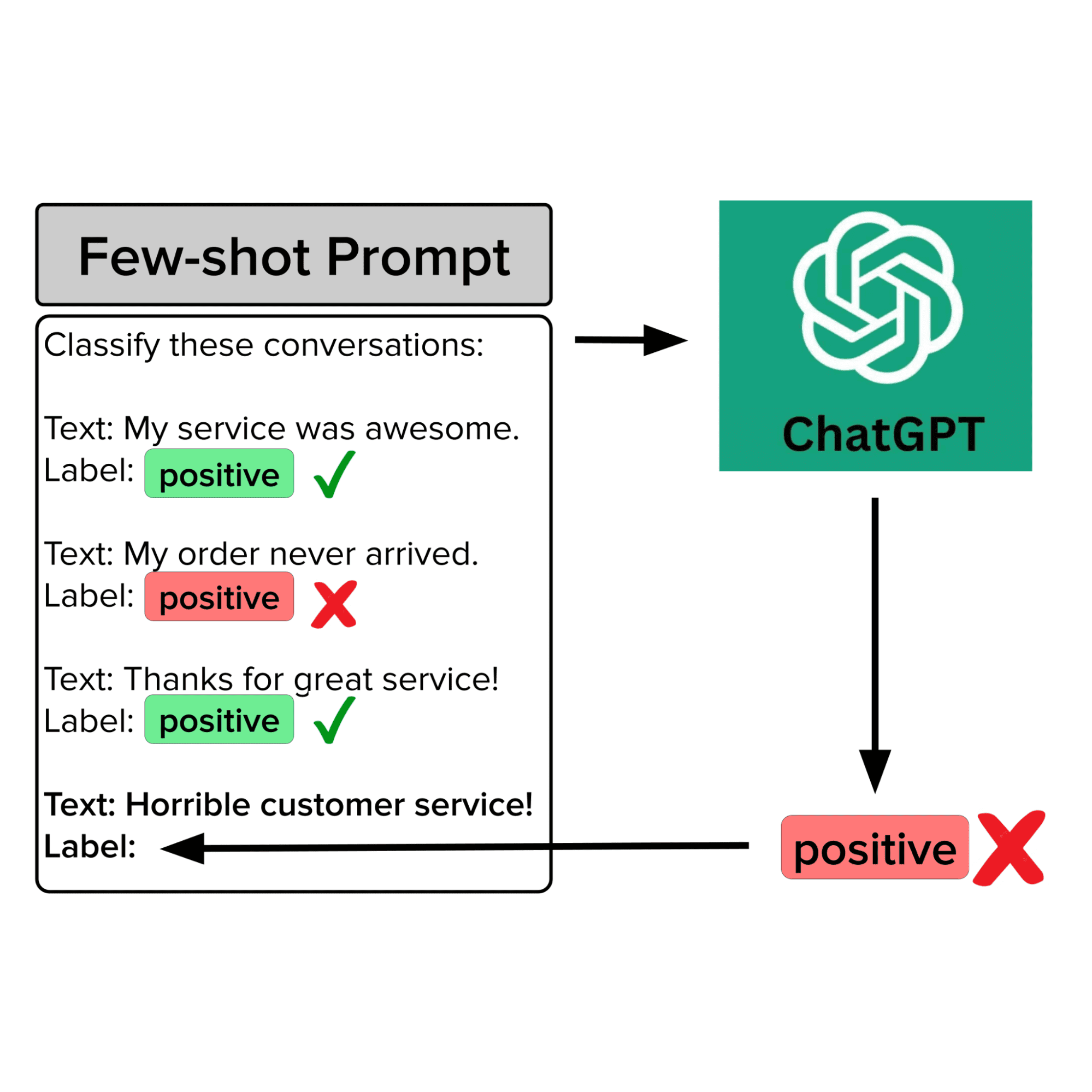
让我们考虑如何策划高质量的少量示例,以便提示达芬奇模型产生最可靠的预测结果。确保少量提示中有高质量示例的需求似乎是显而易见的,但许多工程师并不知道有算法/软件可以帮助您更系统地完成这个任务(事实上,这是数据中心人工智能的整个科学学科)。这种算法数据策划具有许多优点,它是:完全自动化的、系统性的,并且广泛适用于除意图分类之外的一般达芬奇模型应用。
- 这篇AI论文探讨了大型语言模型(LLMs)在文本标注任务中的潜力,重点关注ChatGPT
- 网络犯罪分子使用WormGPT破坏电子邮件安全
- “认识 FreedomGPT:一种基于 Alpaca 构建的开源 AI 技术,经过编程以识别和优先考虑道德因素,不经过任何审查过滤”
银行意图数据集
本文研究了一个包含在线银行查询和相应意图注释(下面是标签)的50类变种的Banking-77数据集。我们使用一个固定的测试数据集来评估预测该标签的模型,该测试数据集包含约500个短语,并且有一个包含约1000个带标签短语的候选池,我们考虑将其作为我们的少量示例之一。

您可以在这里和这里下载候选少量示例和测试集。这是一个可以运行以重现本文中所示结果的笔记本。
少量提示
少量提示(也称为上下文学习)是一种自然语言处理技术,使预训练的基础模型能够在没有任何显式训练(即模型参数更新)的情况下执行复杂任务。在少量提示中,我们向模型提供有限数量的输入-输出对,作为提示模板的一部分,该模板包含在提示中用于指导模型如何处理特定输入。提示模板提供的额外上下文帮助模型更好地推断出所需的输出类型。例如,给定输入:“旧金山在加利福尼亚吗?”,如果该提示与一个固定的模板相结合,使新的提示看起来像这样:
文本:波士顿在马萨诸塞州吗?
标签:是
文本:丹佛在加利福尼亚吗?
标签:否
文本:旧金山在加利福尼亚吗?
标签:
少量提示在文本分类场景中特别有用,特别是当您的类别是特定于领域的时候(这通常是不同业务中的客户服务应用的情况)。

在我们的案例中,我们有一个包含50个可能类别(意图)的数据集,以为达芬奇预训练模型提供上下文,使其能够学习类别之间的差异。使用LangChain,我们从我们的候选示例池中随机选择每个类别的一个示例,并构建一个包含50个示例的提示模板。我们还追加了一个列出可能类别的字符串,以确保LLM的输出是一个有效的类别(即意图类别)。
上述50个示例的提示作为LLM的输入,用于对测试集中的每个示例进行分类(上面的目标文本是此输入中在不同测试示例之间发生变化的唯一部分)。将这些预测与实际标签进行比较,以评估使用所选的少量提示模板产生的LLM准确性。
基线模型性能
# 此方法处理:
# - 收集每个测试示例
# - 格式化提示
# - 查询LLM API
# - 解析输出
def eval_prompt(examples_pool, test, prefix="", use_examples=True):
texts = test.text.values
responses = []
examples = get_examples(examples_pool, seed) if use_examples else []
for i in range(len(texts)):
text = texts[i]
prompt = get_prompt(examples_pool, text, examples, prefix)
resp = get_response(prompt)
responses.append(resp)
return responses# 评估上述50个示例的提示。
preds = eval_prompt(examples_pool, test)
evaluate_preds(preds, test)
>>> 模型准确率:59.6%将每个测试示例都通过LLM运行使用上述50个示例的提示,我们获得了59.6%的准确率,对于一个50类问题来说这已经不错了。但是对于我们银行的客户服务应用来说,这还不够令人满意,所以让我们仔细看看候选示例数据集(即“pool”)。当机器学习表现不佳时,往往是数据的问题!
我们数据中的问题
通过对我们的少样本提示所抽取的候选示例池进行仔细检查,我们发现数据中存在错误标记的短语和异常值。以下是一些明显标记错误的示例。

先前的研究观察到许多受欢迎的数据集中包含错误标记的示例,因为数据注释团队并不完美。
客户服务数据集中常常包含不相关的示例,这些示例是意外包含进来的。在这里,我们看到了一些看起来奇怪的示例,它们与有效的银行客户服务请求不相符。

为什么这些问题很重要?
随着LLM的上下文规模增长,提示中包含许多示例变得越来越常见。因此,如果你的少样本示例的数据源中存在像上面展示的问题(许多现实世界的数据集都会有这样的问题),那么错误的示例可能会出现在你的提示中。本文的其余部分将探讨这个问题的影响以及我们如何减轻它。
我们能否警告LLM可能存在噪声的示例?
如果我们在提示中加入一个“免责声明警告”,告诉LLM提供的少样本示例中可能存在错误的标签,会怎么样?这里我们考虑对我们的提示模板进行以下修改,仍然包含与以前相同的50个少样本示例。

prefix = '请注意,示例中的一些标签可能存在噪声并且被错误指定。'
preds = eval_prompt(examples_pool, test, prefix=prefix)
evaluate_preds(preds, test)
>>> 模型准确率:62.0%使用上述提示,我们获得了62%的准确率。稍微好一点,但对于我们银行的客户服务系统来说还不够好!
我们能否完全删除噪声示例?
由于我们不能信任少样本示例池中的标签,如果我们将它们完全从提示中删除,只依赖强大的LLM呢?与其进行少样本提示,我们进行零样本提示,其中提示中仅包含LLM应该进行分类的示例。零样本提示完全依赖LLM的预训练知识以获得正确的输出。

preds = eval_prompt(examples_pool, test, use_examples=False)
evaluate_preds(preds, test)
>>> 模型准确率:67.4%在完全删除质量低下的少样本示例后,我们实现了67.4%的准确率,这是到目前为止我们取得的最好成绩!
似乎嘈杂的少样本示例实际上会损害模型的性能,而不是像它们应该做的那样提升它。
我们能否识别和纠正嘈杂的示例?
与其修改提示或完全删除示例,改进数据集的更聪明(但更复杂)的方法是通过手动找到和修复标签问题来消除干扰模型的嘈杂数据点,并添加一个准确的数据点以通过少样本提示来提高其性能,但手动进行这样的更正是繁琐的。在这里,我们使用Confident Learning算法来自动找到和修复标签问题的平台Cleanlab Studio轻松地纠正数据。
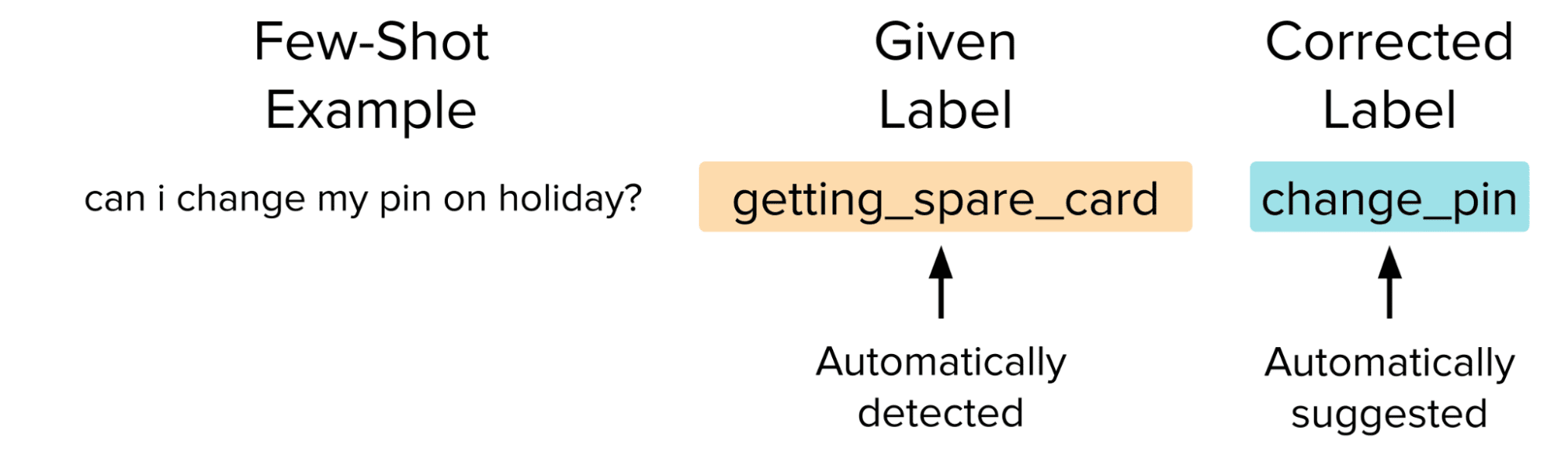
通过使用Confident Learning估计更合适的标签替换估计的错误标签后,我们对原始的50-shot提示进行了重新运行,每个测试示例都使用了自动纠正的标签,这确保我们为LLM提供了50个高质量的示例作为少样本提示。
# 使用纠正后的标签获取源示例。
clean_pool = pd.read_csv("studio_examples_pool.csv")
clean_examples = get_examples(clean_pool)
# 使用高质量示例评估原始的50-shot提示。
preds = eval_prompt(clean_examples, test)
evaluate_preds(preds, test)
>>> 模型准确率:72.0%经过这样的操作,我们实现了72%的准确率,对于这个50类问题来说是非常令人印象深刻的。
我们现在已经证明了嘈杂的少样本示例会严重降低LLM性能,并且仅仅手动更改提示(通过添加警告或删除示例)是次优的。为了实现最高的性能,您还应该尝试使用Confident Learning等数据中心的AI技术来纠正您的示例。
数据中心的AI的重要性
本文强调了确保语言模型可靠的少样本提示选择的重要性,特别关注银行业中的客户服务意图分类。通过探索一家大型银行的客户服务请求数据集,并使用Davinci LLM的少样本提示技术,我们遇到了由嘈杂和错误的少样本示例引起的挑战。我们证明,仅仅修改提示或删除示例不能保证模型的最佳性能。相反,像Cleanlab Studio这样实现Confident Learning算法的数据中心的AI工具,通过识别和纠正标签问题,可以显著提高准确性。这项研究强调了算法数据策划在获取可靠的少样本提示中的作用,并强调了这些技术在增强不同领域的语言模型性能中的实用性。 Chris Mauck是Cleanlab的数据科学家。






