在机器学习中使用SHAP值进行模型解释性分析
使用SHAP值解释机器学习模型
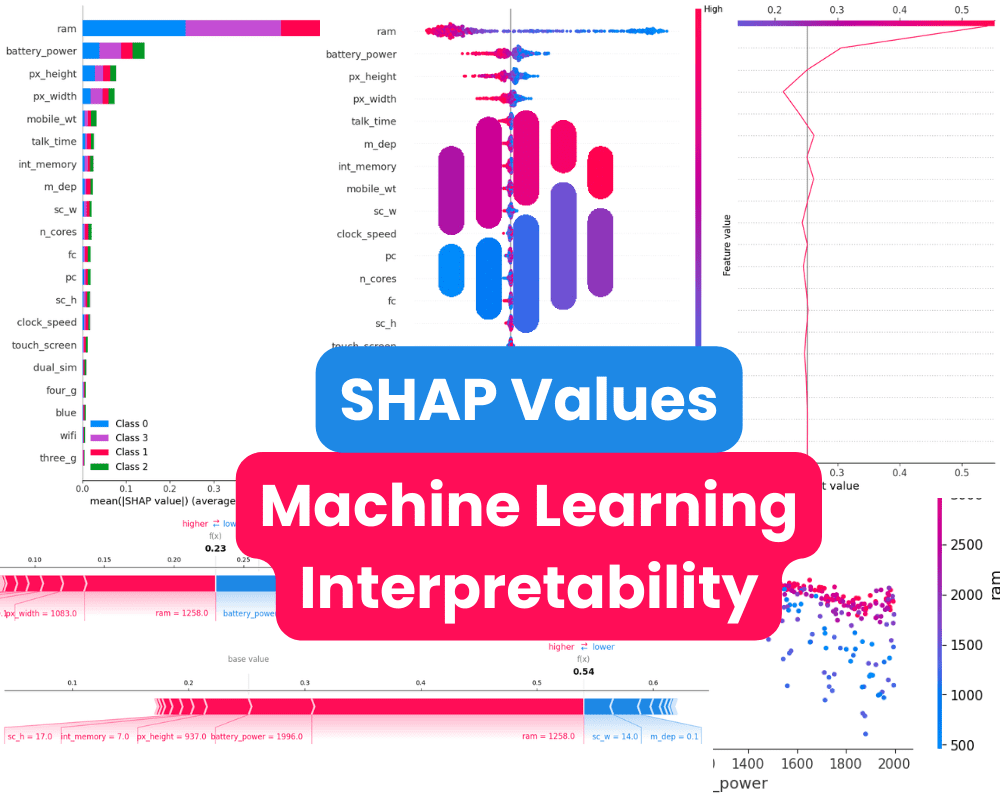
机器学习可解释性
机器学习可解释性是指用于解释和理解机器学习模型如何进行预测的技术。随着模型变得更加复杂,解释其内部逻辑并洞察其行为变得越来越重要。
这一点很重要,因为机器学习模型经常用于做出具有现实后果的决策,如医疗保健、金融和刑事司法等领域。如果没有可解释性,很难知道机器学习模型是否做出了良好的决策或者是否存在偏见。
在机器学习可解释性方面,有各种各样的技术可以考虑。其中一种流行的方法是确定特征重要性分数,这些分数显示了对模型预测影响最大的特征。SKlearn模型默认提供特征重要性分数,但您还可以利用SHAP、Lime和Yellowbrick等工具来更好地可视化和理解机器学习结果。
本教程将介绍SHAP值以及如何使用SHAP Python包解释机器学习结果。
SHAP值是什么?
SHAP值基于博弈论中的夏普利值。在博弈论中,夏普利值帮助确定在一个合作游戏中每个玩家对总奖励的贡献程度。
对于机器学习模型,每个特征被视为一个”玩家”。特征的夏普利值表示该特征在所有可能的特征组合中的平均贡献程度。
具体而言,SHAP值通过将某个特定特征存在与否的模型预测进行比较来计算。这个过程对于数据集中的每个特征和每个样本都进行迭代计算。
通过为每个预测分配每个特征一个重要性值,SHAP值提供了模型行为的局部、一致的解释。它们揭示了哪些特征对特定预测有最大的影响,无论是积极地还是消极地。这对于理解复杂的机器学习模型(如深度神经网络)的推理过程非常有价值。
开始使用SHAP值
在本节中,我们将使用Kaggle的Mobile Price Classification数据集构建和分析多分类模型。我们将根据ram、size等特征对手机价格进行分类。目标变量是<code>price_range</code>,其值为0(低成本)、1(中等成本)、2(高成本)和3(非常高成本)。
注意:代码源与输出可在Deepnote工作区中找到。
安装SHAP
使用<code>pip</code>或<code>conda</code>命令在您的系统上安装<code>shap</code>非常简单。
pip install shap
或者
conda install -c conda-forge shap
加载数据
该数据集干净且组织良好,类别已使用标签编码器转换为数字。
import pandas as pd
mobile = pd.read_csv("train.csv")
mobile.head()
准备数据
首先,我们将确定因变量和自变量,然后将它们拆分为单独的训练集和测试集。
from sklearn.model_selection import train_test_split
X = mobile.drop('price_range', axis=1)
y = mobile.pop('price_range')
# 训练集和测试集拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
训练和评估模型
之后,我们将使用训练集训练我们的随机森林分类器模型,并在测试集上评估其性能。我们获得了87%的准确率,这相当不错,并且我们的模型整体上平衡良好。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 模型拟合
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
# 预测
y_pred = rf.predict(X_test)
# 模型评估
print(classification_report(y_pred, y_test))
precision recall f1-score support
0 0.95 0.91 0.93 141
1 0.83 0.81 0.82 153
2 0.80 0.85 0.83 158
3 0.93 0.93 0.93 148
accuracy 0.87 600
macro avg 0.88 0.87 0.88 600
weighted avg 0.87 0.87 0.87 600
计算SHAP值
在这部分中,我们将创建一个SHAP树解释器,并使用它计算测试集的SHAP值。
import shap
shap.initjs()
# 计算SHAP值
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X_test)
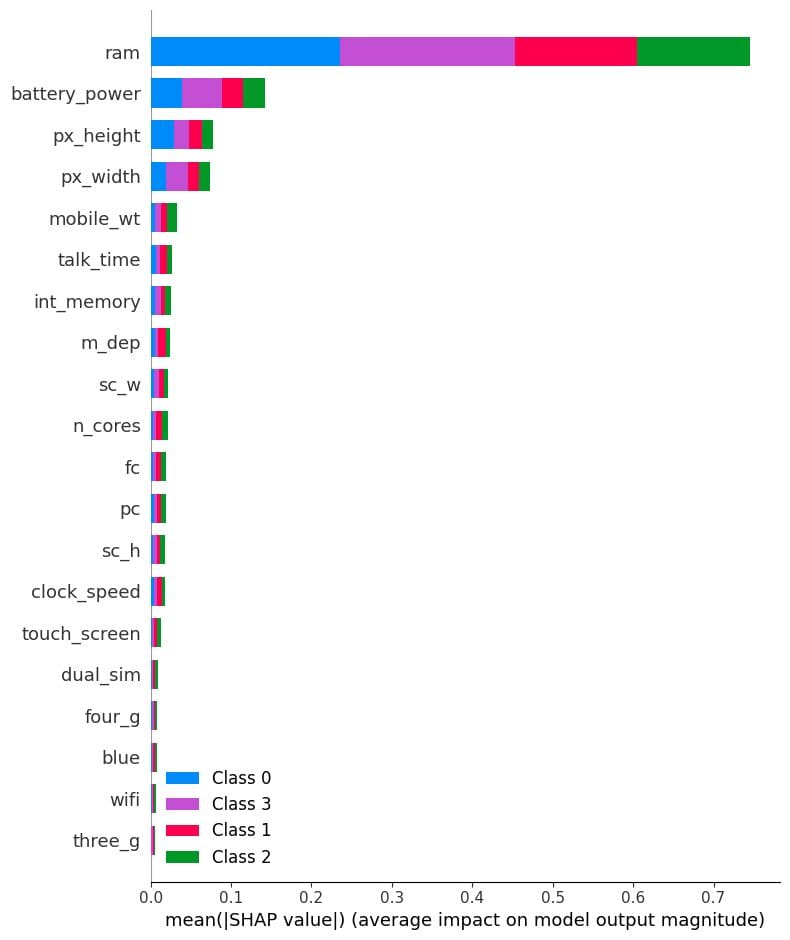
总结图
总结图是模型中每个特征的特征重要性的图形表示。它是了解模型如何进行预测以及识别最重要的特征的有用工具。
在我们的案例中,它显示了每个目标类别的特征重要性。结果显示,“ram”、“battery_power”和手机的大小在确定价格范围方面起着重要作用。
# 汇总特征的影响
shap.summary_plot(shap_values, X_test)
现在我们将可视化类别“0”的特征重要性。我们可以清楚地看到,“ram”、“battery”和手机大小对预测低成本手机有负面影响。
shap.summary_plot(shap_values[0], X_test) 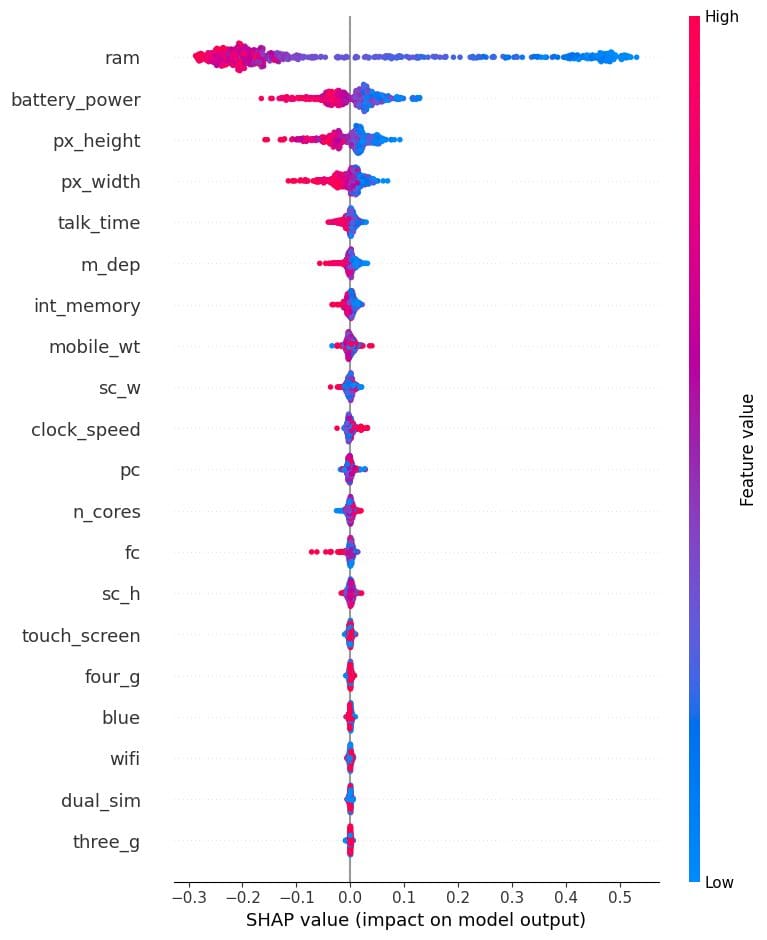
依赖图
依赖图是一种散点图,显示模型预测如何受特定特征的影响。在本示例中,特征是“battery_power”。
图的x轴显示“battery_power”的值,y轴显示shap值。当电池功率超过1200时,它开始对低端手机型号的分类产生负面影响。
shap.dependence_plot("battery_power", shap_values[0], X_test,interaction_index="ram") 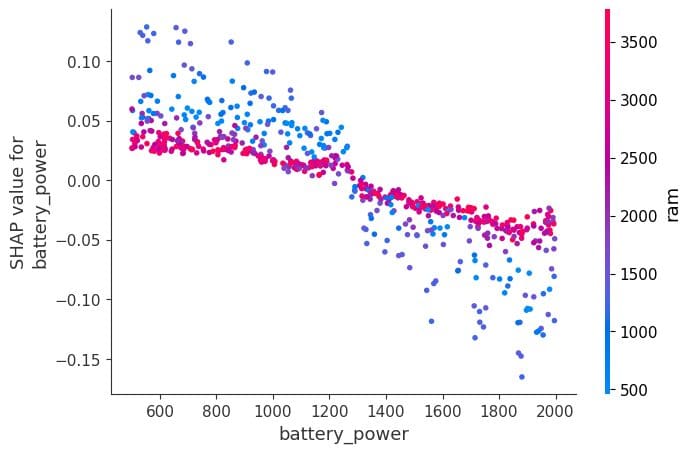
力图
让我们把注意力集中在单个样本上。具体来说,我们将仔细观察第12个样本,以查看哪些特征有助于“0”结果。为此,我们将使用一个力图,输入预期值、SHAP值和测试样本。
结果显示,ram、手机大小和时钟速度对模型有较大影响。我们还注意到,由于f(x)较低,模型不会预测“0”类。
shap.plots.force(explainer.expected_value[0], shap_values[0][12,:], X_test.iloc[12, :], matplotlib = True)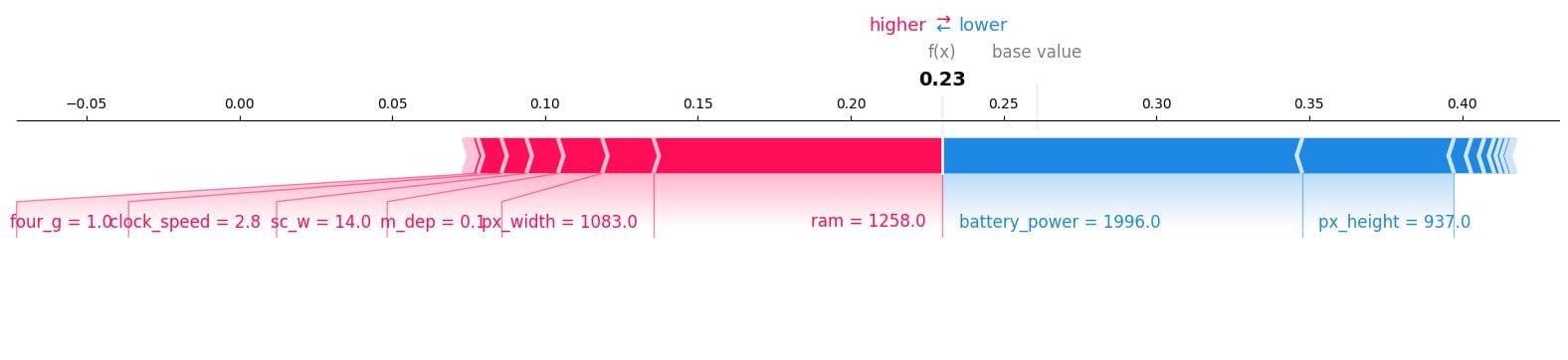
我们将对类别“1”绘制力量图,可以看到它是正确的类别。
shap.plots.force(explainer.expected_value[1], shap_values[1][12, :], X_test.iloc[12, :],matplotlib = True)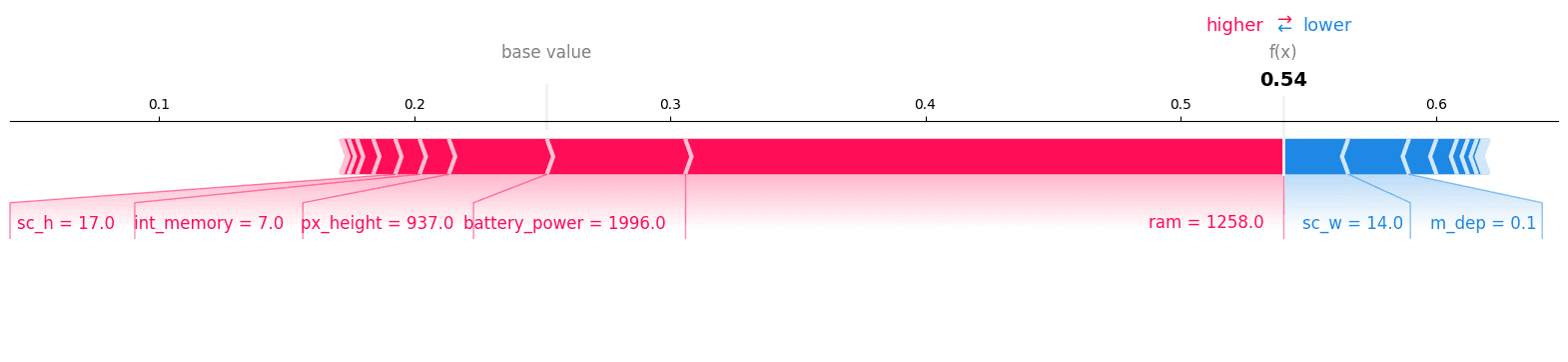
我们可以通过检查测试集的第12条记录来确认我们的预测。
y_test.iloc[12]
>>> 1决策图
决策图是理解机器学习模型决策过程的有用工具。它们可以帮助我们识别对模型预测最重要的特征,并识别潜在的偏差。
为了更好地理解影响模型对类别“1”的预测的因素,我们将检查决策图。根据这个图,似乎手机高度对模型有负面影响,而RAM有正面影响。
shap.decision_plot(explainer.expected_value[1], shap_values[1][12,:], X_test.columns)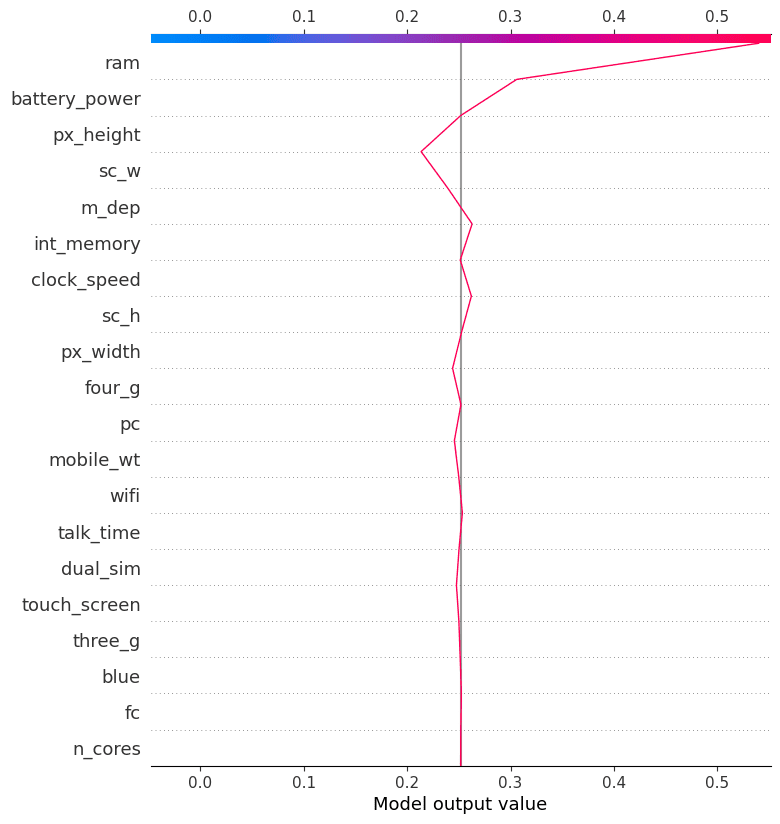
结论
在这篇博文中,我们介绍了SHAP值,一种解释机器学习模型输出的方法。我们展示了如何使用SHAP值解释个别预测和模型的整体性能。我们还提供了SHAP值在实践中的应用示例。
随着机器学习在医疗保健、金融和自动驾驶等敏感领域的扩展,解释性和可解释性将变得越来越重要。SHAP值提供了一种灵活、一致的方法来解释预测和模型行为。它可以用于深入了解模型如何进行预测、识别潜在的偏差,并改进模型的性能。 Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学家,热衷于构建机器学习模型。目前,他专注于内容创作,并在机器学习和数据科学技术方面撰写技术博客。Abid拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生构建一个AI产品。






