“利用MySQL的JSON_ARRAYAGG函数进行黑客攻击,创建动态的多值维度”
使用MySQL的JSON_ARRAYAGG函数进行黑客攻击,创建动态多值维度
弥补MySQL的一个鲜为人知的缺点
介绍
假设我们是一个订阅盒子公司的数据团队成员。在MySQL数据库中,购买的交易记录被写入名为subscriptions的表中。除了元数据外,该表包含customer_id和subscription字段,大致如下:
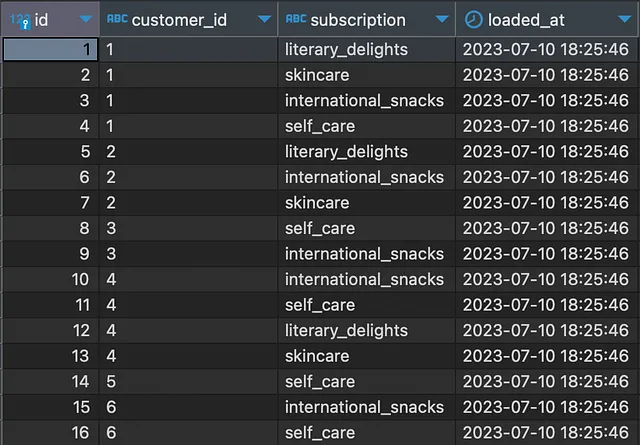
请注意,在这个示例场景中,一个客户可以有多个订阅。每个记录的唯一性由客户ID和订阅同时定义,即一个客户不能有相同的订阅两次。如果你想将这个测试数据加载到你自己的数据库中,你可以在这里找到相应的代码。
作为一个订阅盒子公司,我们的目标是销售更多的订阅盒子。为此,产品团队最近指出我们所有的现有客户都有多个订阅。他们对此表示好奇,想知道这对客户行为有何影响。他们要求我们的团队提供一个数据模型,显示用户购买的订阅组合以及哪些组合最常见。
市场团队对这个模型也表示了兴趣。他们认为这些结果可能对营销捆绑产品促销、客户画像和针对电子邮件营销活动有用。出于同样的原因,他们还要求查看每个客户购买的最常见的订阅数量。
简而言之,所请求的数据模型希望回答一些重要的问题,最终实现更高的订阅盒子销量。问题是,我们应该如何执行它呢?
在本文中,我们将通过弥补MySQL的一个鲜为人知的缺点来解决一个独特的数据建模挑战。我们将涵盖定性聚合、JSON数据类型以及如何强制MySQL对值列表进行排序,以产生不重复的多值维度。
目录
- 作为维度的聚合
- MySQL中JSON数据类型的简要概述
- JSON_ARRAYAGG
- 使用ROW_NUMBER来强制排序值
- 总结
作为维度的聚合
从概念上讲,我们需要做的事情相对简单:我们需要按客户将我们的订阅打包(分组)。然后,我们需要查看这些打包,并确定哪些是最常见的,以及其中有多少订阅。
在数据建模术语中,我们正在考虑某种形式的聚合:具体地说,按客户聚合订阅。
在定量意义上,我们通常会考虑到聚合函数(SUM,COUNT等),这主要是因为这是SQL中大多数聚合函数的功能。但我们也可以将连接的字符串值聚合成更长的类似列表的字符串。
然而,这其中的挑战在于访问、操作或以其他方式评估这些连接字符串中的值。MySQL将把值foo, bar, hello, world视为文本,而不是列表。
为什么这个问题很重要?主要是因为在我们的假设场景中,我们想要计算每个组合中的订阅数量。我们不想要一个长的逗号分隔字符串,我们想要更真正类似列表的东西。
在Python中解决这个问题很简单 – 使用pandas,可能是polars,甚至只是Python本地的数据结构。但有很多情况下这不是一个选择。也许数据团队只使用dbt;或者更常见的是,你在一个IT部门有严格限制的公司工作。
无论如何,如果你只能使用SQL,你需要一个能够提供最可读的代码和最灵活结果的解决方案。实现这一点并不直观。例如,当遇到这个问题时,我第一反应是使用GROUP_CONCAT函数,该函数根据你定义的分组连接字符串:
WITH subscriptions_grouped AS ( SELECT customer_id, GROUP_CONCAT(subscription) AS subscriptions FROM subscriptions GROUP BY customer_id )SELECT subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;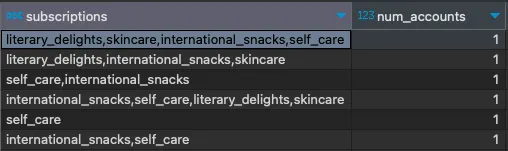
正如您所见,聚合工作在技术上是有效的,但它并不符合我们的业务逻辑。请看第一行和最后一行。”international_snacks, self_care”的组合与”self_care, international_snacks”的组合是相同的。(第二行和第四行也是如此。)
我们可以在GROUP_CONCAT内使用ORDER BY子句来解决这个问题:
WITH subscriptions_grouped AS ( SELECT customer_id, GROUP_CONCAT(subscription ORDER BY subscription) AS subscriptions FROM subscriptions GROUP BY 1 )SELECT subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;
但是,这仍然存在一个问题,即如何计算每个组合中有多少个订阅。
有一种方法可以做到这一点。但是,我认为它不仅过于复杂和不易读,而且还存在一些不太明显的陷阱。
在MySQL中,通过快速搜索如何计算逗号分隔字符串中的值的数量,可以找到一个来自StackOverflow的解决方案,翻译后如下(不包括subscriptions_grouped CTE):
SELECT subscriptions, LENGTH(subscriptions) - LENGTH(REPLACE(subscriptions, ',', '')) + 1 AS num_subscriptions, COUNT(*) AS num_accountsFROM subscriptions_groupedGROUP BY subscriptions;这本质上是计算逗号的数量,然后在结果上加1。这个方法是有效的。但是,不仅很难一眼就能理解,而且还容易引入错误:函数LENGTH和CHAR_LENGTH不计算相同的内容。
正如您可能猜到的,本文详细介绍了我在类似情况下工作时遇到的障碍。
最终,解决方案是使用原生的MySQL JSON数据类型进行一种有点巧妙但非常易于理解的变通方法。
MySQL中JSON数据类型的简要概述
MySQL的JSON数据类型在5.7.8版本中添加,为存储和建模提供了很多有用的工具。
在JSON数据类型的范围内(官方称之为“JSON文档”),有两种不同的数据结构:JSON数组和JSON对象。
JSON数组可以简单地被视为一个数组(如果您是Pythonista,则为列表):由方括号[ ]括起来的值,用逗号分隔。
- MySQL JSON数组值的示例:
["foo", "bar", 1, 2]
JSON对象可以被视为哈希表(或者在Python术语中再次是字典):由逗号分隔的键值对,用花括号{ }括起来。
- MySQL JSON对象值的示例:
{"foo": "bar", 1: 2}
MySQL有许多可以用于处理这两种格式的函数,几乎没有任何一种函数执行任何形式的聚合。
不过幸运的是,有两种函数可以做到。它们都返回JSON文档,这意味着我们可以使用MySQL的内置函数来访问其中的值。
JSON_ARRAYAGG
MySQL函数JSON_ARRAYAGG的作用与GROUP_CONCAT非常相似。最大的区别在于它返回一个JSON数组,再次,这个数组带有上面链接的几个有用的内置函数。
JSON数组数据类型以惊人的简洁性解决了我们的两个问题之一:可靠计算组合中订阅数量的问题。这是通过使用JSON_LENGTH函数完成的。语法非常直观:
SELECT JSON_LENGTH(JSON_ARRAY("foo", "bar", "hello", "world"));-- 此处使用JSON_ARRAY函数仅用于快速创建示例数组该语句的结果是4,因为生成的JSON数组中有4个值。
但让我们回到订阅的组合。不幸的是,JSON_ARRAYAGG不具备GROUP_CONCAT的排序功能。即使在基本查询之前的CTE中对subscription值进行排序,也无法得到所需的结果:
WITH subscriptions_ordered AS ( SELECT customer_id, subscription FROM subscriptions ORDER BY subscription ) , subscriptions_grouped AS ( SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptions, JSON_LENGTH(JSON_ARRAYAGG(subscription)) AS num_subscriptions FROM subscriptions_ordered GROUP BY customer_id )SELECT subscriptions, COUNT(*) AS num_accounts num_subscriptionsFROM subscriptions_groupedGROUP BY subscriptions;
每个组合中的订阅数量是存在的,这要归功于JSON_LENGTH函数,但由于顺序的原因,实际上相同的组合再次被错误地标记为不同。
使用ROW_NUMBER来强制排序值
ROW_NUMBER是一个窗口函数,用于创建索引。索引必须被定义,也就是说,您必须告诉它从哪里开始、如何递增(方向)以及何时结束。
我们可以通过应用ROW_NUMBER函数并告诉它按subscription字段排序来快速看一个例子:
SELECT customer_id, subscription, ROW_NUMBER() OVER(ORDER BY subscription) AS alphabetical_row_numFROM subscriptions;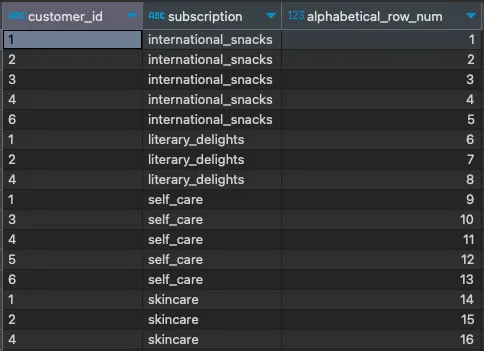
仔细观察结果。尽管我们没有在查询末尾使用ORDER BY语句,但数据仍然根据OVER子句中的ORDER BY进行排序。
但当然,这还不是我们想要的。接下来,我们需要在窗口函数中添加PARTITION BY子句,以便结果的排序与(实际上是由)每个客户ID相关联和限定。像这样:
SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_orderFROM subscriptions;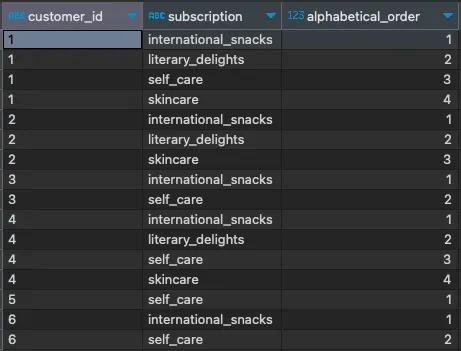
您可能看到这是怎么回事。
如果我们在CTE中对这些结果执行JSON_ARRAYAGG函数,我们可以看到重复的组合现在完全相同,这要归功于ROW_NUMBER函数将订阅强制按字母顺序排序:
WITH subscriptions_ordered AS ( SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_order FROM subscriptions )SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptionsFROM subscriptions_orderedGROUP BY 1ORDER BY 2;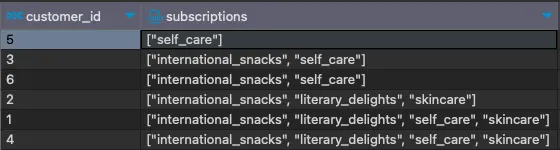
现在我们只需要在执行ROW_NUMBER之后添加分组CTE,并修改基本查询:
WITH subscriptions_ordered AS (SELECT customer_id, subscription, ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY subscription) AS alphabetical_order FROM subscriptions), subscriptions_grouped AS (SELECT customer_id, JSON_ARRAYAGG(subscription) AS subscriptions, JSON_LENGTH(JSON_ARRAYAGG(subscription)) AS num_subscriptions FROM subscriptions_ordered GROUP BY customer_id) SELECT subscriptions, COUNT(*) AS num_customers, num_subscriptions FROM subscriptions_grouped GROUP BY subscriptions ORDER BY num_customers DESC;这不仅给出了准确的不同订阅组合,还给出了购买这些组合的客户数量以及每个组合包含的订阅数量:

大功告成!
回顾
- 我们想知道有多少客户购买了不同的订阅组合,以及每个组合中有多少订阅。这带来了两个问题:如何最好地获取后者以及如何生成准确的不同订阅组合。
- 为了获取每个组合中的订阅数量,我们选择使用MySQL的JSON函数之一,
JSON_ARRAYAGG。聚合的结果以JSON数据类型返回,允许我们使用JSON_LENGTH函数。 - 然后,我们需要强制对JSON数组中的值进行排序,以防止重复的组合错误地出现为不同。为此,我们在基本查询之前使用了窗口函数
ROW_NUMBER在CTE中,按客户ID分区并按字母顺序(按升序)排序订阅。 - 这最终使我们能够聚合到准确的不同订阅组合;通过使用简单的
COUNT函数,我们能够看到有多少客户购买了每个组合。
谢谢阅读!🤓
希望对您有所帮助!如果您知道任何其他在SQL中的聪明技巧/解决方法(无论方言如何),我很愿意听听。SQL一直是转换结构化数据的事实上的通用语言,但它并不完美。我总是乐于了解创新和/或聪明应对现实挑战的解决方案。🔥
我经常写有关数据工程和分析主题的文章,目标始终是尽可能清晰简单地写作。如果本文中有任何令您困惑的地方,请在评论中让我知道。如果您有兴趣阅读更多类似的文章,请随时关注我和/或在LinkedIn上连接我。





