使用Kafka和Risingwave构建一条Formula 1流数据管道
使用Kafka和Risingwave构建F1流数据管道
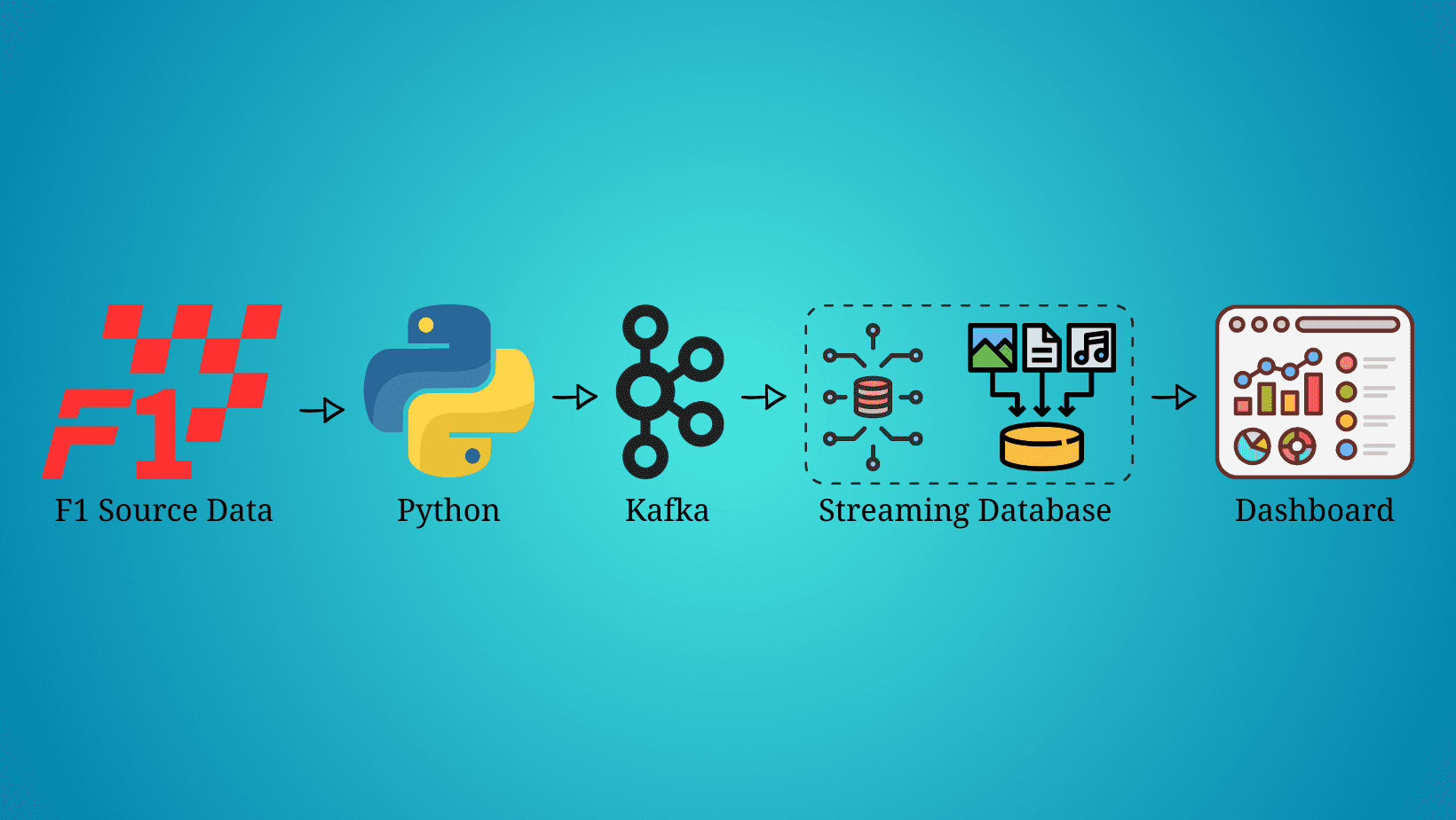
实时数据已经到来,并且将会持续存在。毫无疑问,每天流式数据的数量呈指数增长,我们需要找到最佳的方法来提取、处理和可视化这些数据。例如,每辆F1赛车在一个周末比赛中产生约1.5TB的数据(来源)。
在本文中,我们不会传输赛车的数据,而是会传输、处理和可视化比赛的数据,模拟我们正在观看一场F1比赛的实况。在开始之前,重要的是要提到,本文不会专注于每个技术是什么,而是关注如何在流式数据管道中实现它们,所以需要一些关于Python、Kafka、SQL和数据可视化的知识。
- 一项新的人工智能研究揭示了机器学习模型在描述化学气味方面达到了与人类相当的技能水平
- 字节跳动和加州大学圣地亚哥分校的研究人员提出了一种多视角扩散模型,能够根据给定的任何文本生成一组物体或场景的多视角图像
- 使用Pandas进行数据清洗
先决条件
- F1源数据:在这个数据流水线中使用的F1数据是从Kaggle下载的,可以在F1世界锦标赛(1950-2023)中找到。
- Python:在构建此流水线时使用的是Python 3.9版本,但任何大于3.0的版本都可以工作。有关如何下载和安装Python的详细信息,请参阅官方Python网站。
- Kafka:Kafka是此流水线中使用的主要技术之一,因此在开始之前必须安装它。此流水线是在MacOS上构建的,因此使用brew来安装Kafka。更多详细信息可以在官方brew网站上找到。我们还需要一个Python库来使用Python与Kafka进行交互。此流水线使用kafka-python。安装详细信息可以在它们的官方网站上找到。
- RisingWave(流式数据库):市场上有多个流式数据库可供选择,但本文使用的是RisingWave,是最好的之一。开始使用RisingWave非常简单,只需要几分钟的时间。有关如何入门的完整教程可以在官方网站上找到。
- Grafana仪表板:在这个流水线中使用Grafana实时可视化Formula 1数据。有关如何入门的详细信息可以在这个网站上找到。
传输源数据
现在我们已经具备了所有的先决条件,是时候开始构建Formula 1数据流水线了。源数据存储在一个JSON文件中,因此我们需要提取并通过一个Kafka主题发送它。为此,我们将使用以下Python脚本。
作者提供的代码
设置Kafka
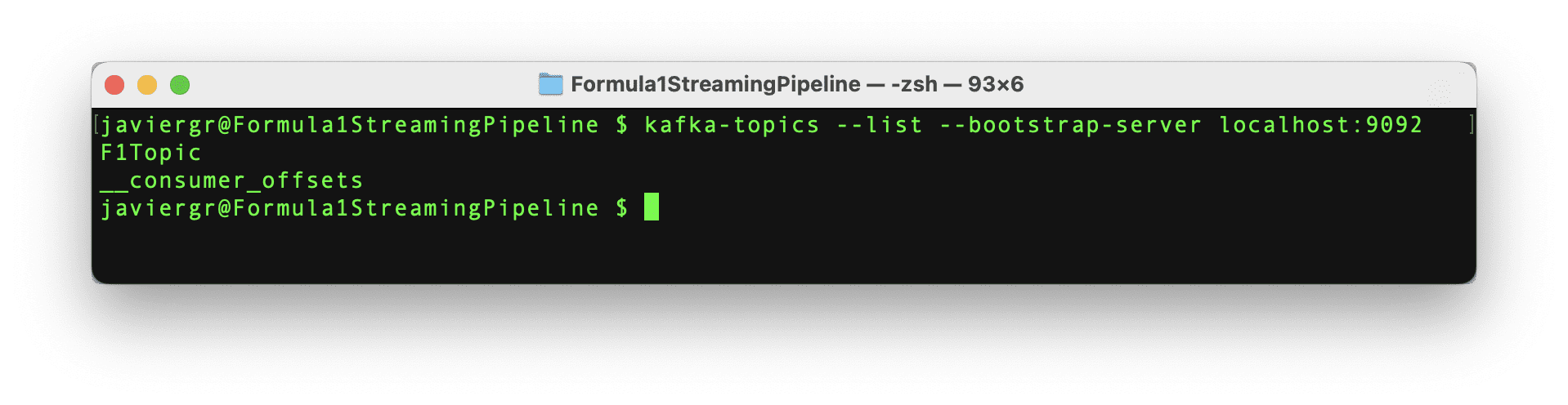
用于传输数据的Python脚本已经准备好开始传输数据了,但是Kafka主题F1Topic尚未创建,因此让我们创建它。首先,我们需要初始化Kafka。为此,我们必须启动Zookeper,然后启动Kafka,最后使用以下命令创建主题。请记住,Zookeper和Kafka应该在一个单独的终端中运行。
作者提供的代码
设置流式数据库RisingWave
一旦安装了RisingWave,启动它非常简单。首先,我们需要初始化数据库,然后通过Postgres交互终端psql连接到它。要初始化流式数据库RisingWave,请执行以下命令。
作者提供的代码
上述命令会以playground模式启动RisingWave,其中数据会暂时存储在内存中。该服务被设计为在30分钟不活动后自动终止,并且在终止时将删除存储的任何数据。此方法仅建议用于测试,生产环境应使用RisingWave Cloud。
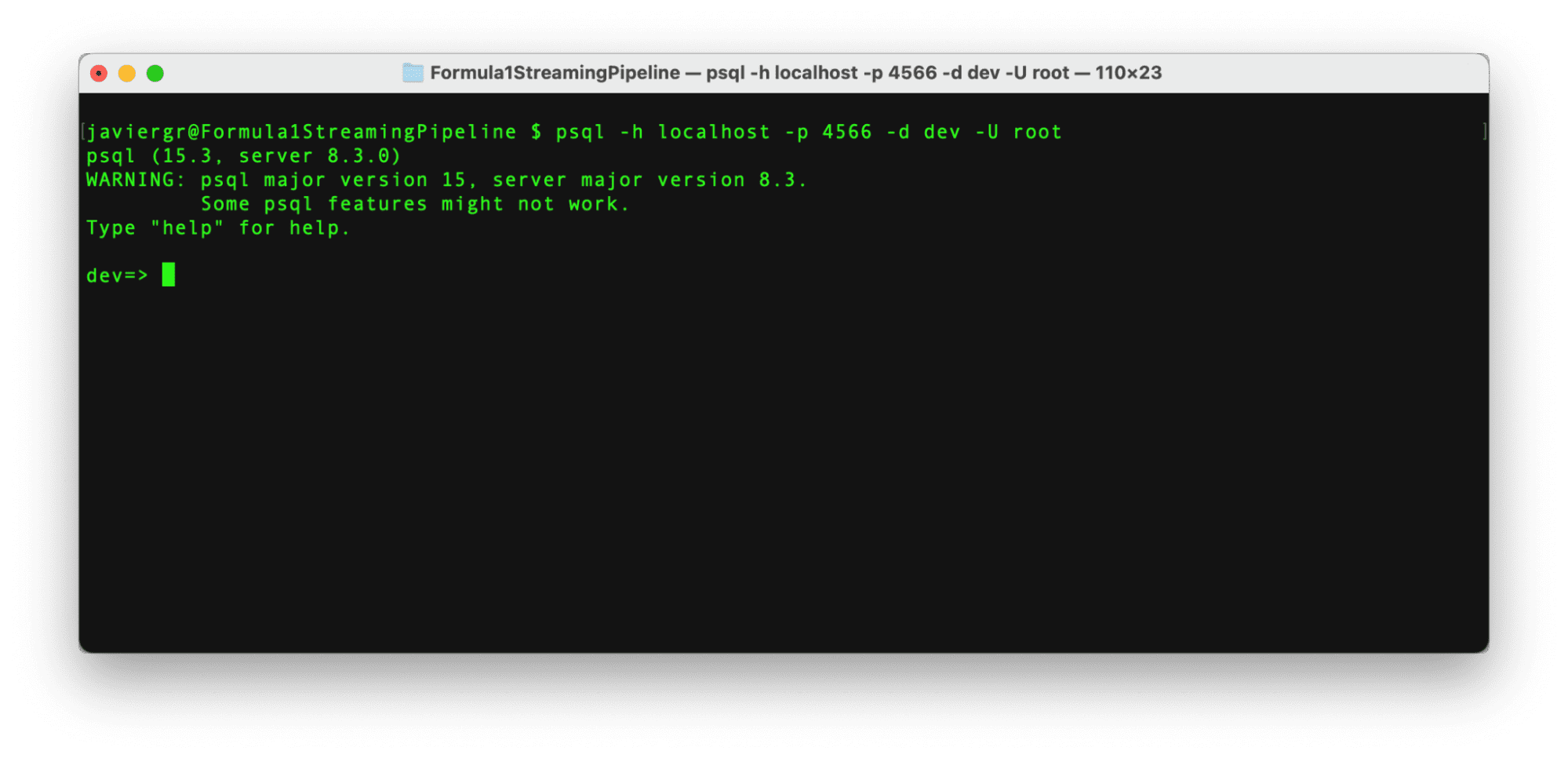
RisingWave运行起来后,是时候通过以下命令在一个新终端中连接到它的Postgress交互终端了。
作者编写的代码
连接建立后,现在是从Kafka主题中拉取数据的时候了。为了将流式数据传入RisingWave,我们需要创建一个源。这个源将建立Kafka主题和RisingWave之间的通信,所以让我们执行以下命令。
作者编写的代码
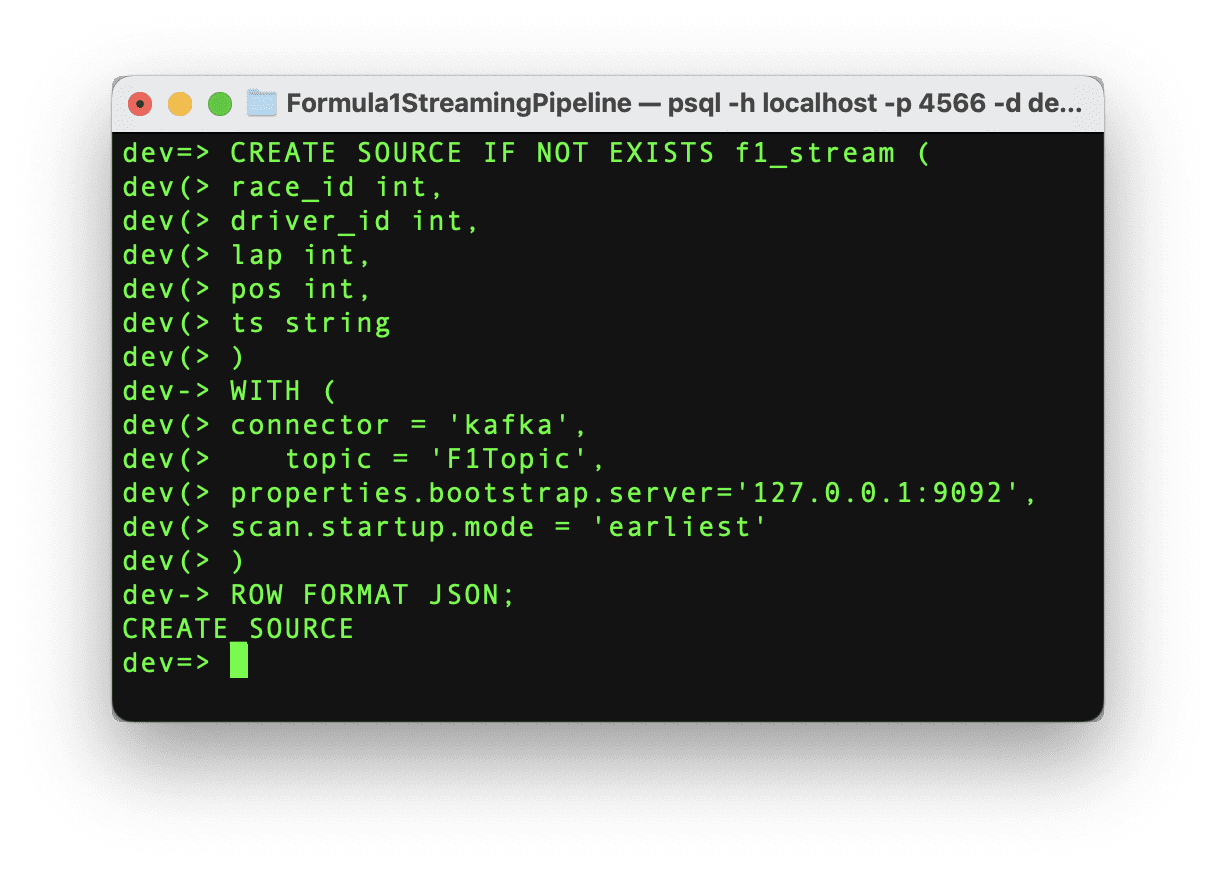
如果命令成功运行,则我们可以看到消息“CREATE SOURCE”和源已经创建。值得强调的是,一旦源被创建,数据不会自动被摄入RisingWave中。我们需要创建一个物化视图来开始数据移动。这个物化视图还将帮助我们在下一步创建Grafana仪表盘。
让我们使用以下命令创建与源数据相同架构的物化视图。
作者编写的代码
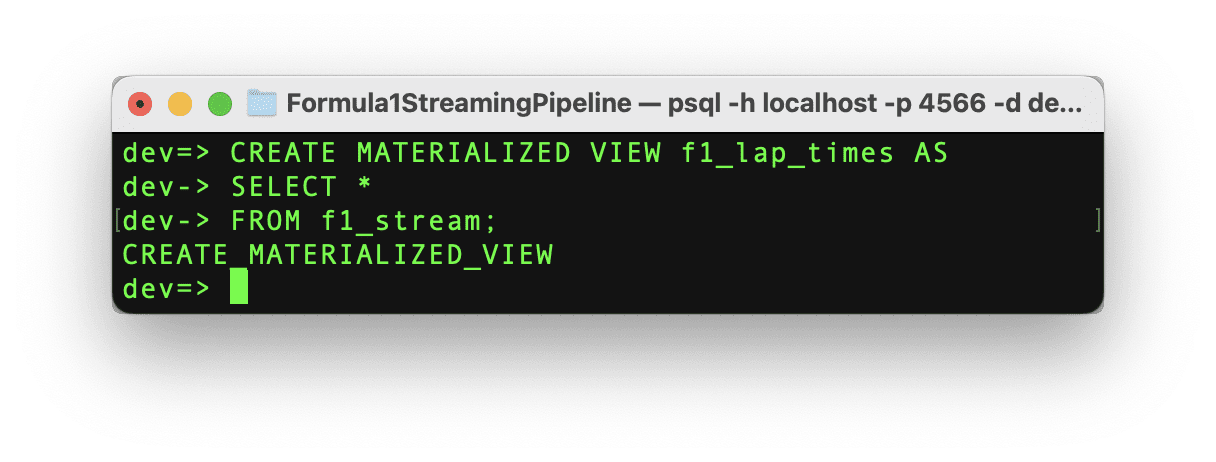
如果命令成功运行,则我们可以看到消息“CREATE MATERIALIZED_VIEW”和物化视图已经创建,现在是测试它的时候了!
执行Python脚本以开始流式传输数据,并在RisingWave终端实时查询数据。RisingWave是一个与PostgreSQL兼容的SQL数据库,所以如果您熟悉PostgreSQL或任何其他SQL数据库,查询流式数据将会很顺利。
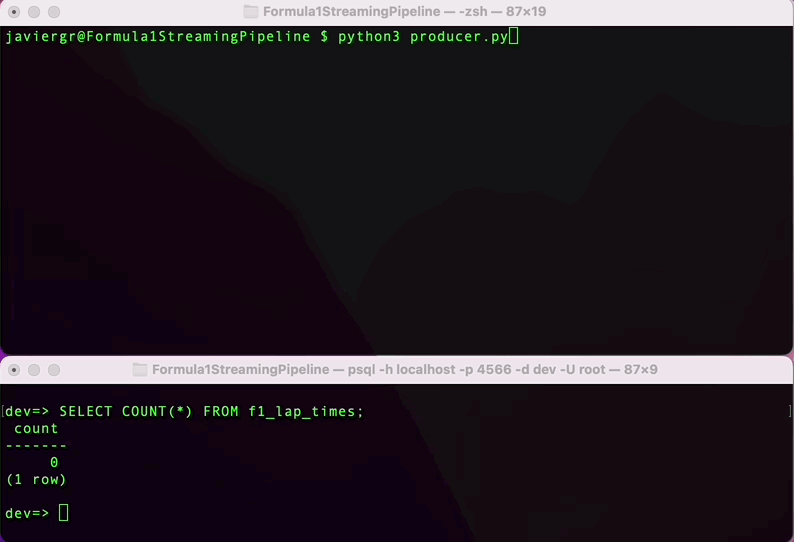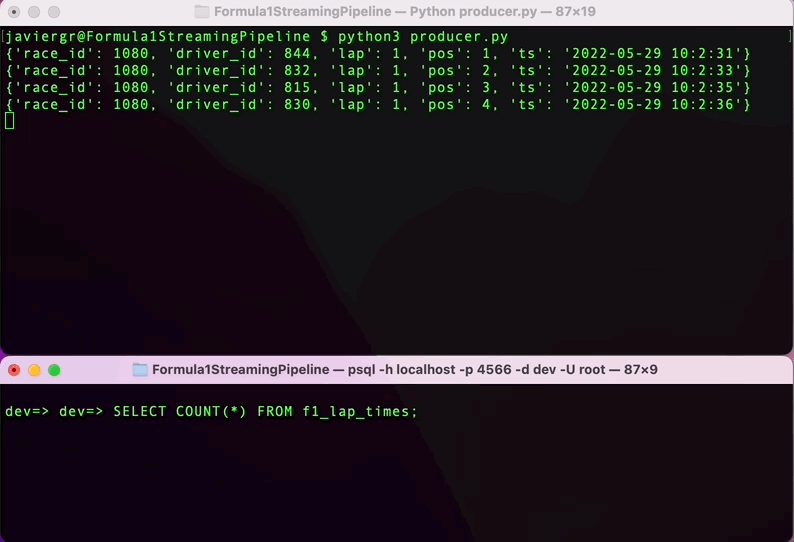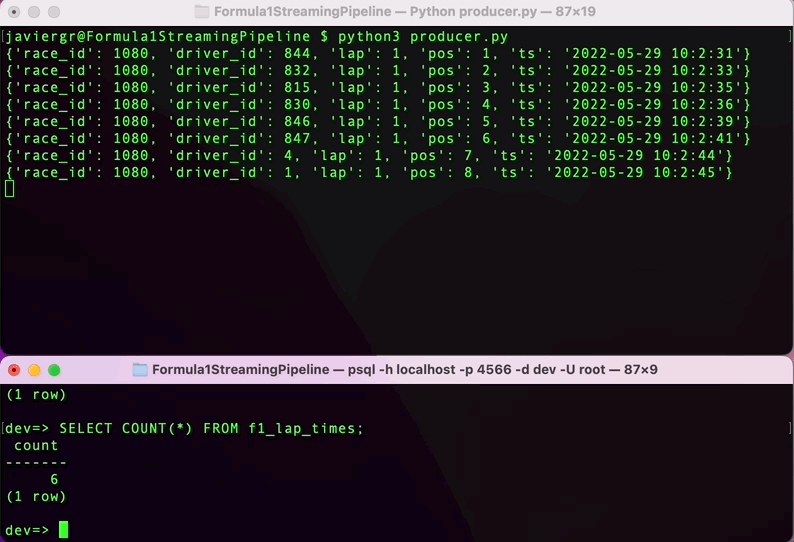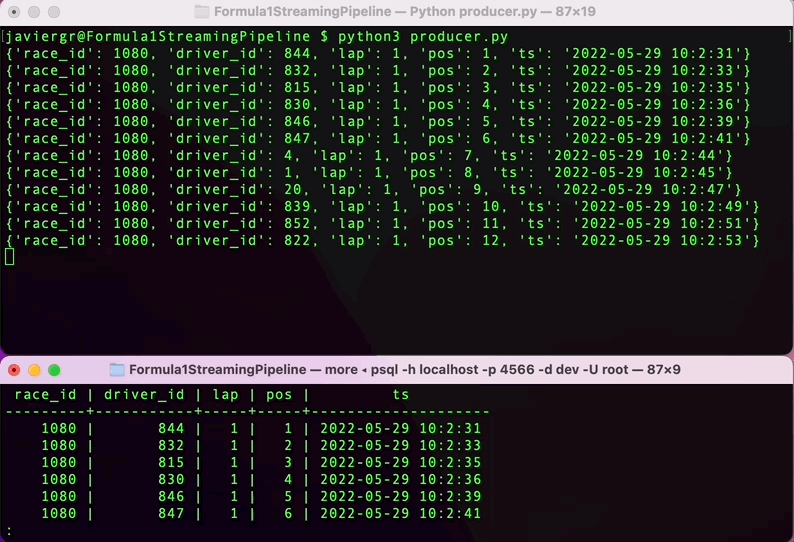
正如您所看到的,流式管道现在已经启动,但是我们还没有充分利用流式数据库RisingWave的优势。我们可以添加更多的表来实时连接数据并构建一个完全功能的应用程序。
让我们创建比赛表,这样我们就可以将流式数据与比赛表连接起来,并获取比赛的实际名称而不是比赛ID。
作者编写的代码
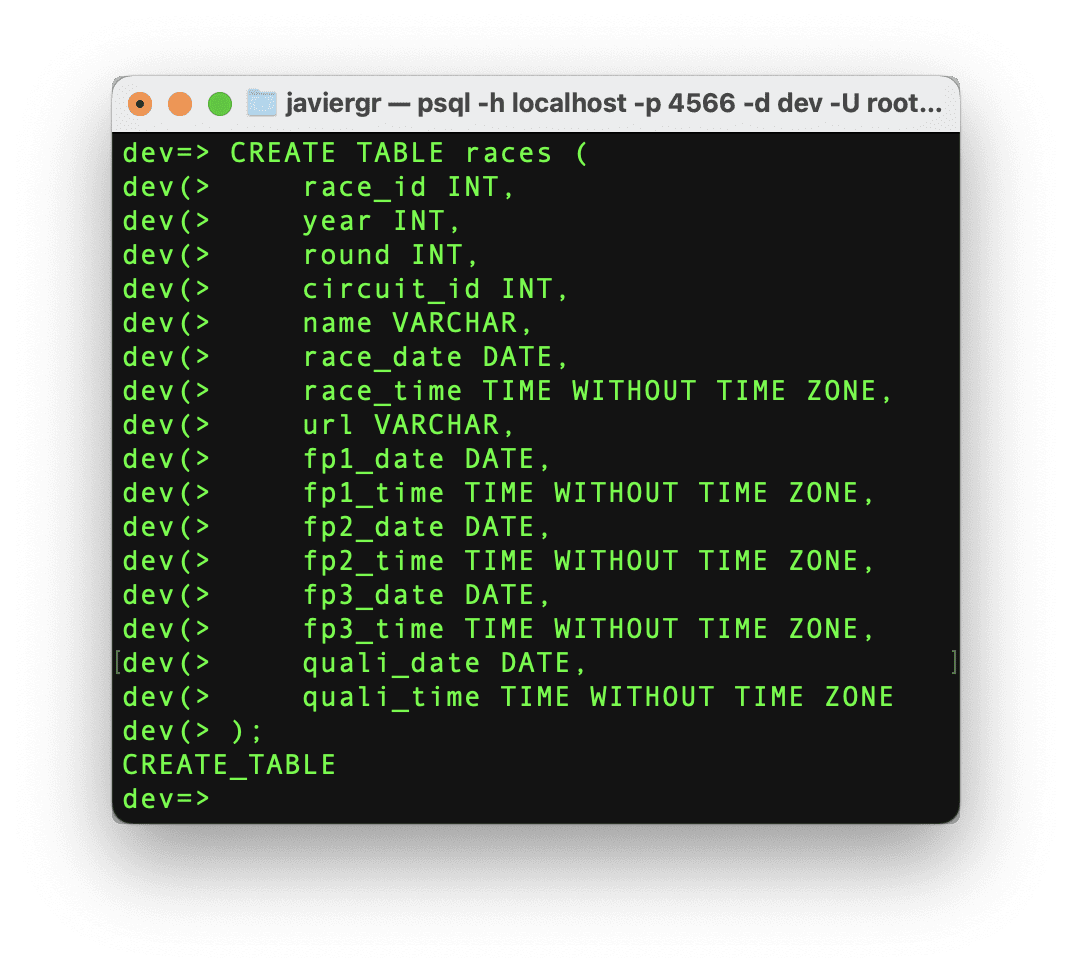
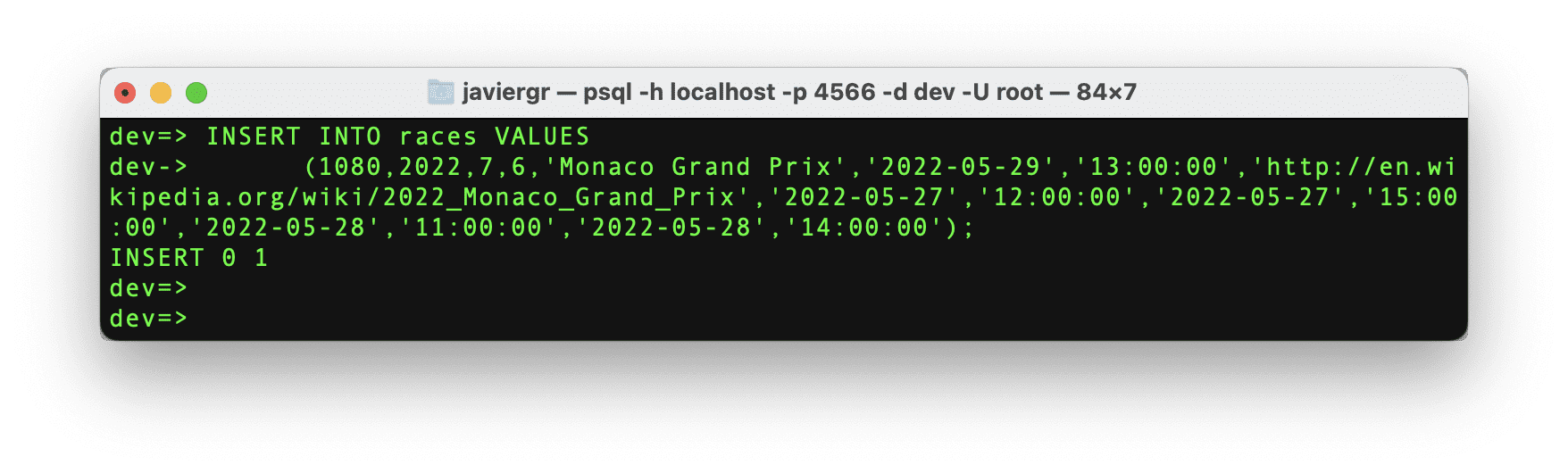
现在,让我们插入我们需要的特定比赛ID的数据。
作者编写的代码
我们将按照相同的过程来处理司机表。
作者编写的代码
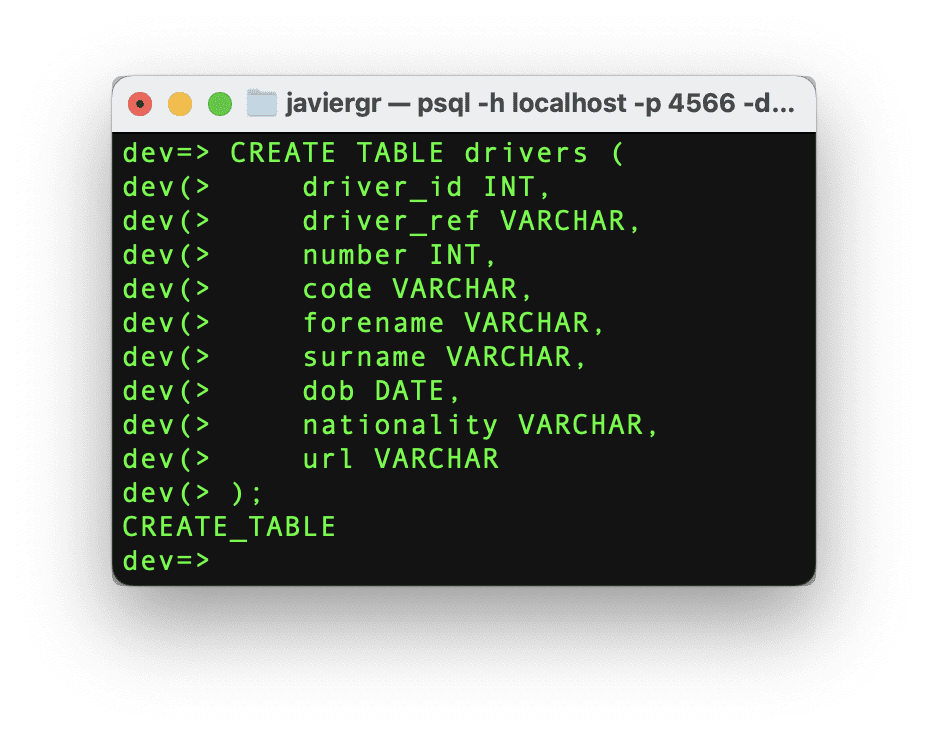
最后,让我们插入司机数据。
作者编写的代码
我们已经准备好开始连接流式数据的表,但是我们还需要物化视图,这是所有魔法发生的地方。让我们创建一个物化视图,在这个视图中,我们可以实时看到前三个位置的数据,连接司机ID和比赛ID以获取实际名称。
作者编写的代码
最后但并非最不重要的,让我们创建最后一个物化视图,以查看在整个比赛中司机获得第一名的次数。
作者编写的代码
现在,是时候构建Grafana仪表盘并通过物化视图实时查看所有连接的数据了。
设置Grafana仪表盘
在这个流式数据管道中的最后一步是在实时仪表盘中可视化流式数据。在创建Gafana仪表盘之前,我们需要创建一个数据源,以建立Grafana和我们的流式数据库RisingWave之间的连接,按照以下步骤进行。
- 转到配置>数据源。
- 点击添加数据源按钮。
- 从支持的数据库列表中选择PostgreSQL。
- 填写PostgreSQL连接字段,如下所示:
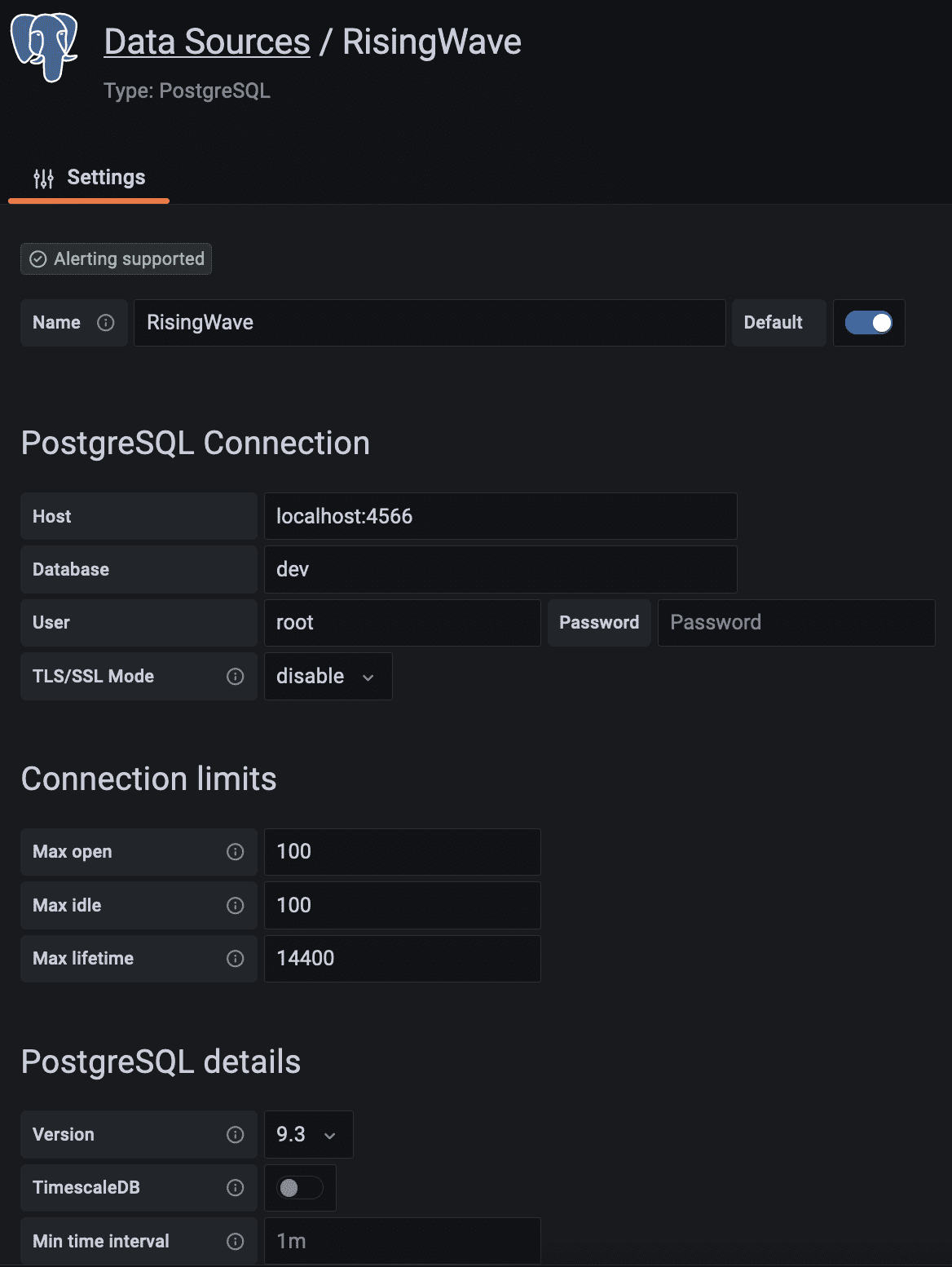
向下滚动并点击保存和测试按钮。数据库连接已建立。
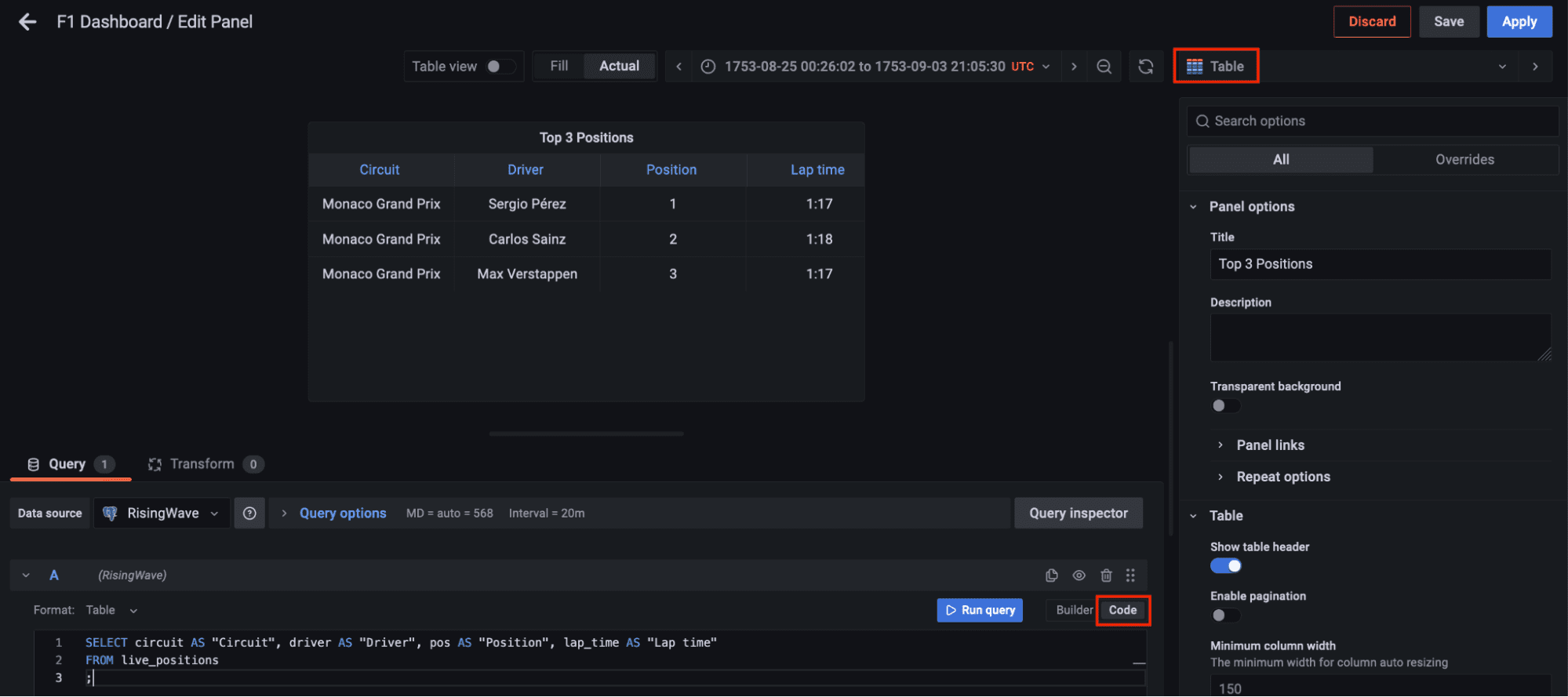
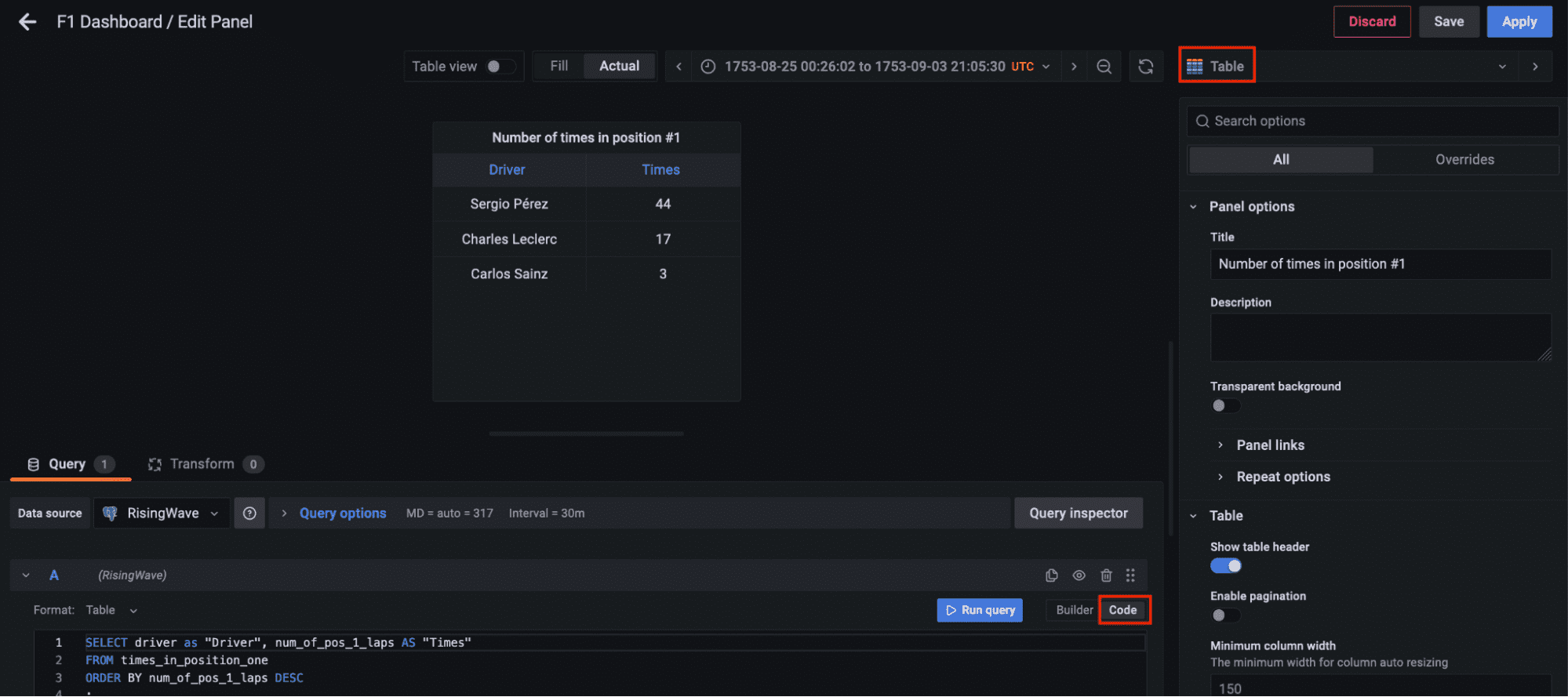
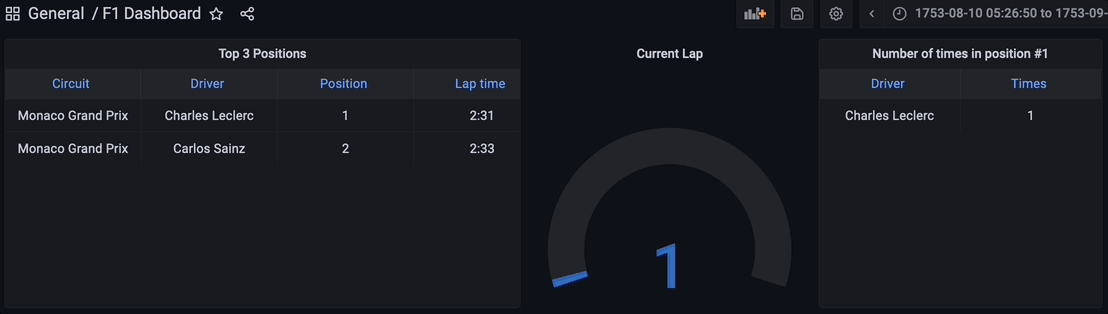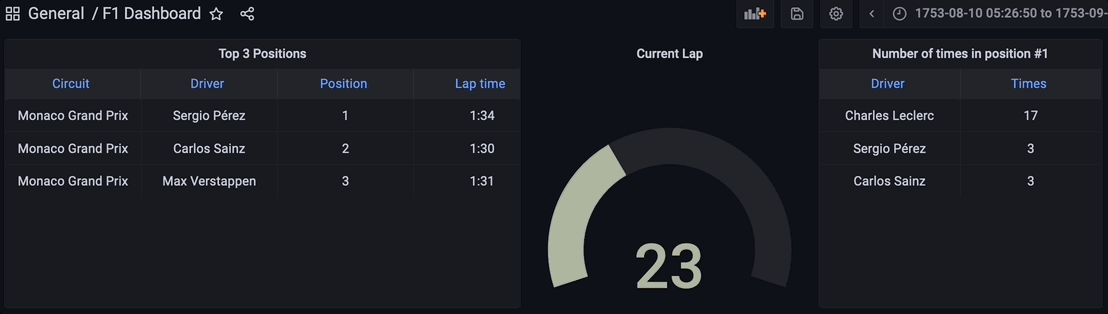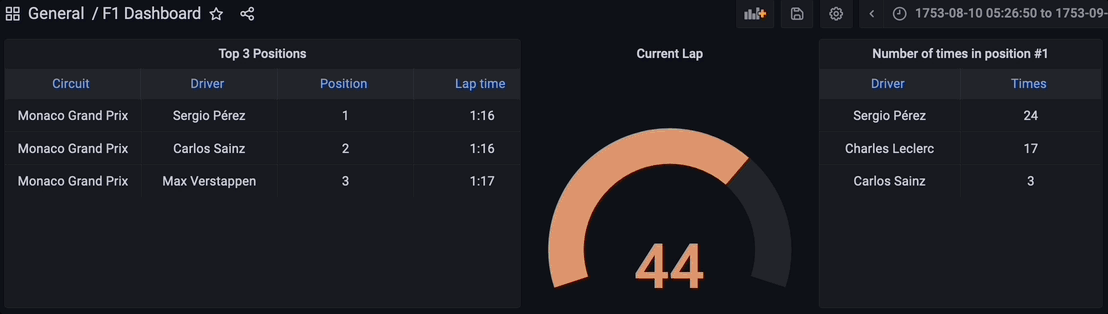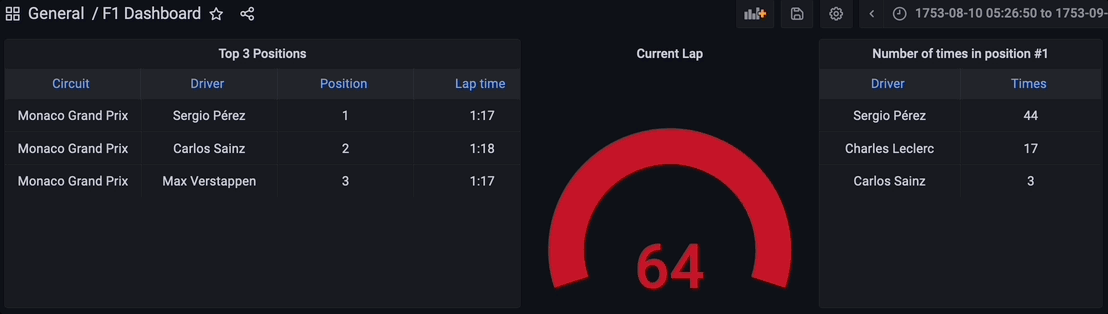
现在在左侧面板中转到仪表盘,点击新建仪表盘选项,并添加一个新面板。选择表可视化,切换到代码选项卡,让我们查询实时位置的物化视图 live_positions,我们可以看到前三个位置的联接数据。
作者提供的代码
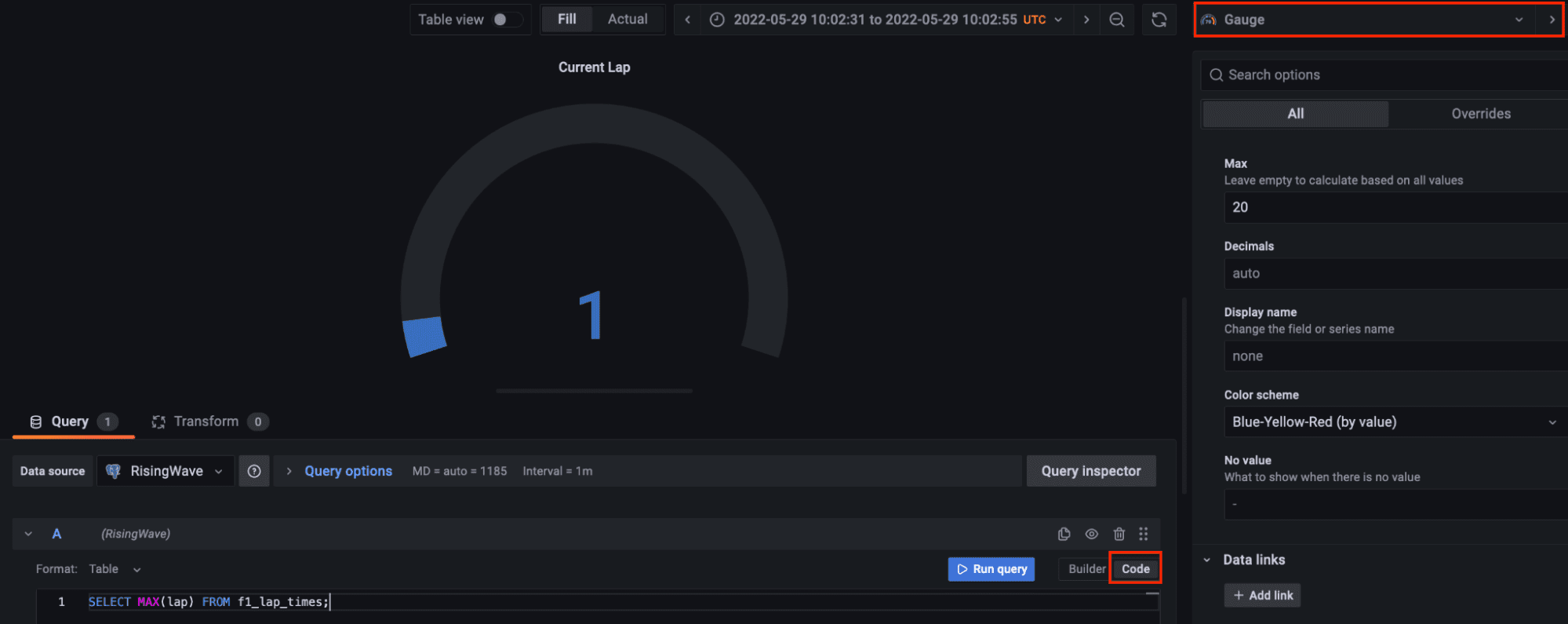
让我们添加另一个面板来可视化当前圈数。选择仪表盘可视化,在代码选项卡中查询流数据中的最大圈数。仪表盘的自定义由您决定。
作者提供的代码
最后,让我们添加另一个面板来查询物化视图 times_in_position_one,并实时查看在整个比赛中有多少次驾驶员获得第一名位置。
作者提供的代码
结果可视化
最终,流数据管道的所有组件都已启动并运行。Python脚本已执行,通过Kafka主题开始流式传输数据,流式数据库RisingWave正在实时读取、处理和联接数据。物化视图 f1_lap_times 从Kafka主题读取数据,Grafana仪表板中的每个面板都是不同的物化视图,通过物化视图联接实时数据,显示详细数据,这得益于物化视图对比赛和驾驶员表的联接。Grafana仪表板查询物化视图,所有处理都得到简化,这要归功于流式数据库RisingWave中的物化视图。
Javier Granados 是一位高级数据工程师,他喜欢阅读和撰写有关数据管道的文章。他专注于云管道,主要在AWS上进行,但他始终在探索新技术和新趋势。您可以在VoAGI的 https://medium.com/@JavierGr 找到他






