使用Amazon SageMaker在空中图像上训练自监督视觉变压器
使用Amazon SageMaker训练自监督视觉变压器
这是一篇与Travelers的Ben Veasey、Jeremy Anderson、Jordan Knight和June Li共同撰写的客座博客文章。
卫星和航拍图像可以为各种问题提供洞察,包括精准农业、保险风险评估、城市发展和灾难响应。然而,训练机器学习(ML)模型来解释这些数据受到昂贵且耗时的人工注释工作的限制。通过自监督学习(SSL)可以克服这一挑战。通过在大量未标记的图像数据上进行训练,自监督模型可以学习图像表示,并将其转移到下游任务,如图像分类或分割。这种方法产生的图像表示对未见数据具有很好的泛化能力,并减少了构建高性能下游模型所需的标记数据量。
在本文中,我们演示了如何使用Amazon SageMaker在航拍图像上训练自监督视觉转换器。Travelers与亚马逊机器学习解决方案实验室(现已更名为生成式AI创新中心)合作开发了这个框架,以支持和增强航拍图像模型的使用案例。我们的解决方案基于DINO算法,并使用SageMaker分布式数据并行库(SMDDP)将数据分割到多个GPU实例上。预训练完成后,DINO图像表示可以转移到各种下游任务。这一举措改进了Travelers数据和分析领域内的模型性能。
解决方案概述
预训练视觉转换器并将其转移到监督下游任务的两步骤流程如下图所示。
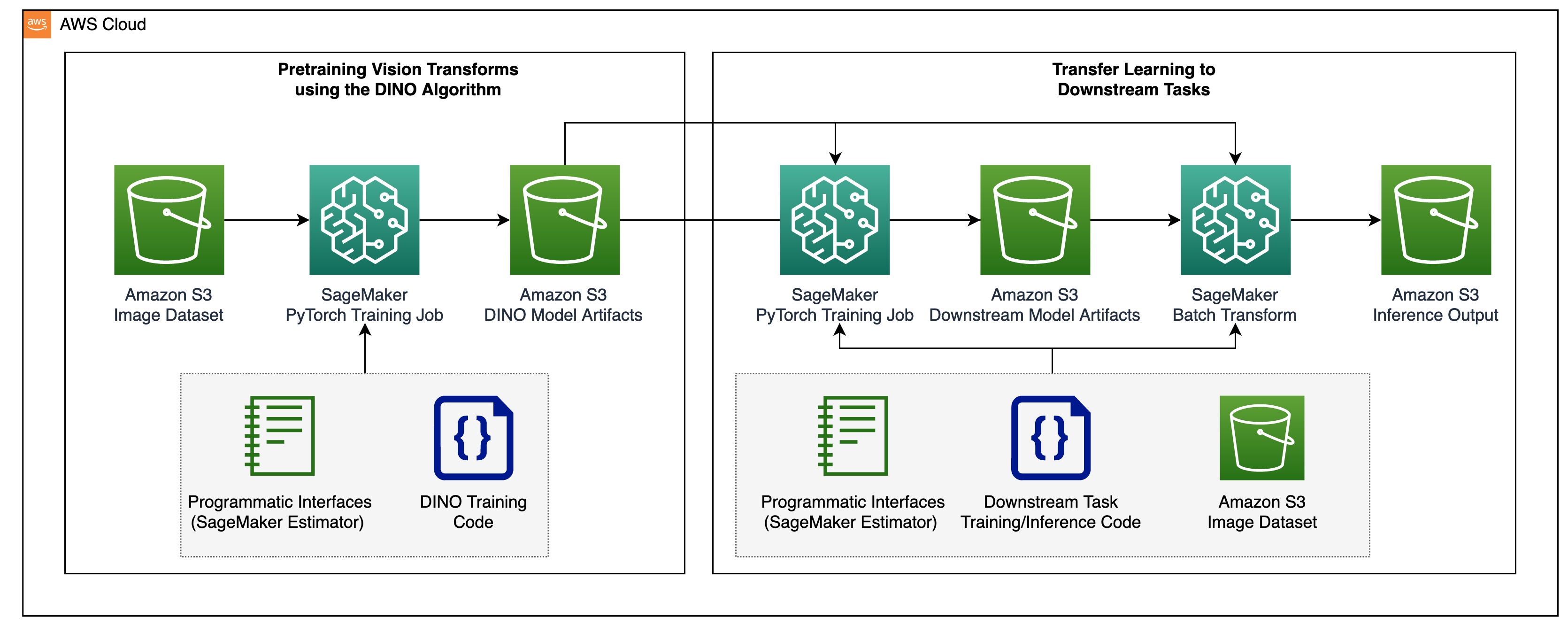
在接下来的几节中,我们将使用BigEarthNet-S2数据集的卫星图像来提供解决方案的详细步骤。我们在DINO存储库中提供的代码基础上进行构建。
先决条件
在开始之前,您需要访问一个SageMaker笔记本实例和一个Amazon Simple Storage Service(Amazon S3)存储桶。
准备BigEarthNet-S2数据集
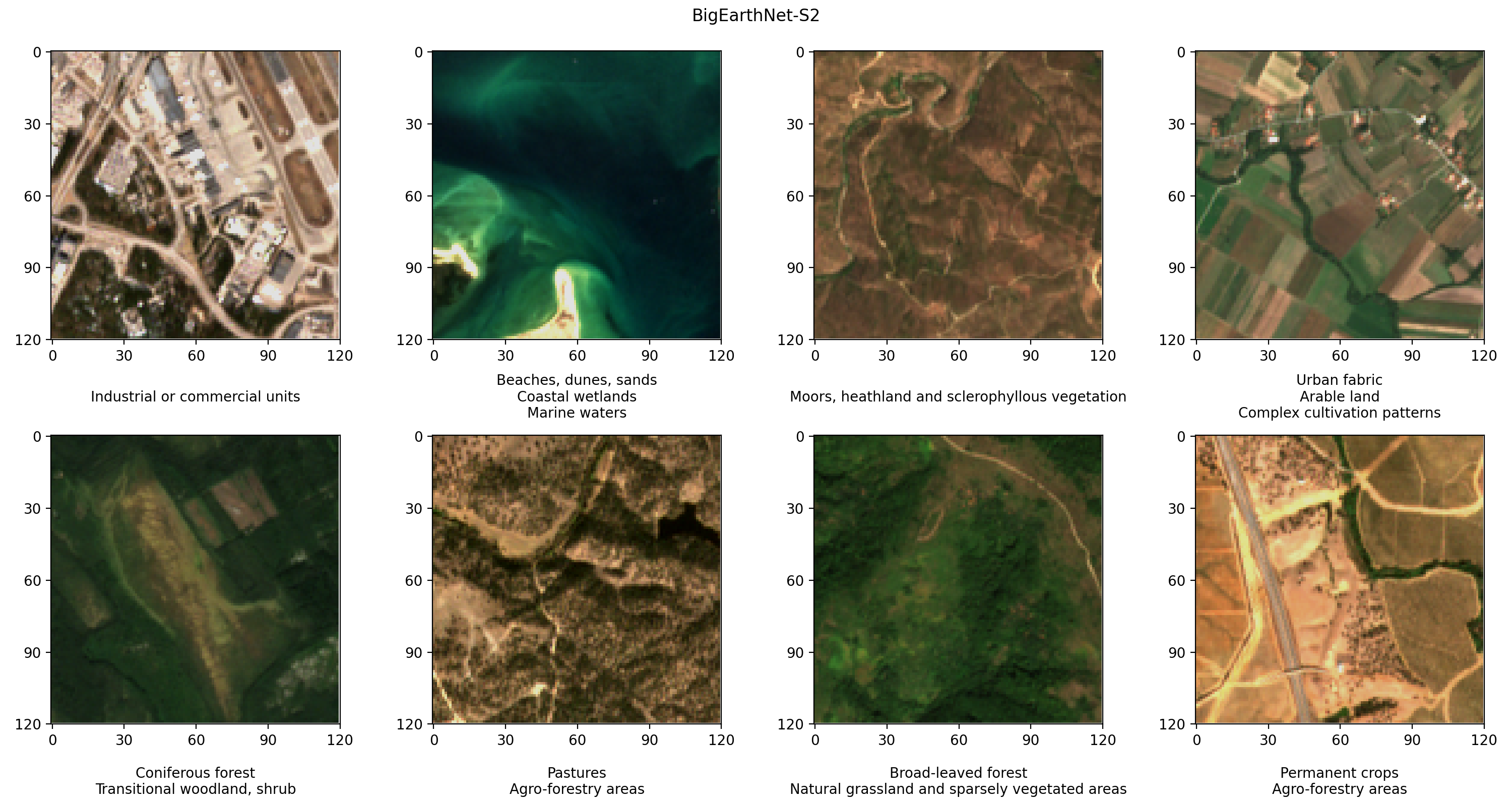
BigEarthNet-S2是一个包含由Sentinel-2卫星收集的590,325个多光谱图像的基准存档。这些图像记录了2017年6月至2018年5月间欧洲十个国家的地表覆盖或物理表面特征。每个图像中的地表覆盖类型,如牧场或森林,都根据19个标签进行了注释。以下是一些示例RGB图像及其标签。
我们工作流程的第一步是为DINO训练和评估准备BigEarthNet-S2数据集。我们从SageMaker笔记本实例的终端下载数据集:
wget https://bigearth.net/downloads/BigEarthNet-S2-v1.0.tar.gz
tar -xvf BigEarthNet-S2-v1.0.tar.gz该数据集的大小约为109 GB。每个图像存储在自己的文件夹中,并包含12个光谱通道。三个带有60m空间分辨率(60米像素高度/宽度)的波段用于识别气溶胶(B01)、水汽(B09)和云(B10)。六个具有20m空间分辨率的波段用于识别植被(B05、B06、B07、B8A)并区分雪、冰和云(B11、B12)。三个具有10m空间分辨率的波段用于捕捉可见光和近红外光(B02、B03、B04、B8/B8A)。此外,每个文件夹还包含一个带有图像元数据的JSON文件。BigEarthNet数据的详细描述请参阅BigEarthNet指南。
为了在DINO训练期间执行数据的统计分析和加载图像,我们将各个元数据文件处理成一个常见的geopandas Parquet文件。可以使用BigEarthNet Common和BigEarthNet GDF Builder辅助包来完成这个任务:
python -m bigearthnet_gdf_builder.builder build-recommended-s2-parquet BigEarthNet-v1.0/生成的元数据文件包含推荐的图像集,其中排除了71,042个完全被季节性雪、云和云阴影覆盖的图像。它还包含每个图像的获取日期、位置、地表覆盖和训练、验证和测试分割的信息。
我们将BigEarthNet-S2图像和元数据文件存储在一个S3存储桶中。因为在DINO训练过程中我们使用真彩色图像,所以我们只上传红色(B04)、绿色(B03)和蓝色(B02)波段:
aws s3 cp final_ben_s2.parquet s3://bigearthnet-s2-dataset/metadata/
aws s3 cp BigEarthNet-v1.0/ s3://bigearthnet-s2-dataset/data_rgb/ \
--recursive \
--exclude "*" \
--include "_B02.tif" \
--include "_B03.tif" \
--include "_B04.tif"该数据集的大小约为48 GB,具有以下结构:
bigearthnet-s2-dataset/ Amazon S3存储桶
├── metadata/
│ └── final_ben_s2.parquet
└── dataset_rgb/
├── S2A_MSIL2A_20170613T101031_0_45/
│ └── S2A_MSIL2A_20170613T101031_0_45_B02.tif 蓝色通道
│ └── S2A_MSIL2A_20170613T101031_0_45_B03.tif 绿色通道
│ └── S2A_MSIL2A_20170613T101031_0_45_B04.tif 红色通道使用SageMaker训练DINO模型
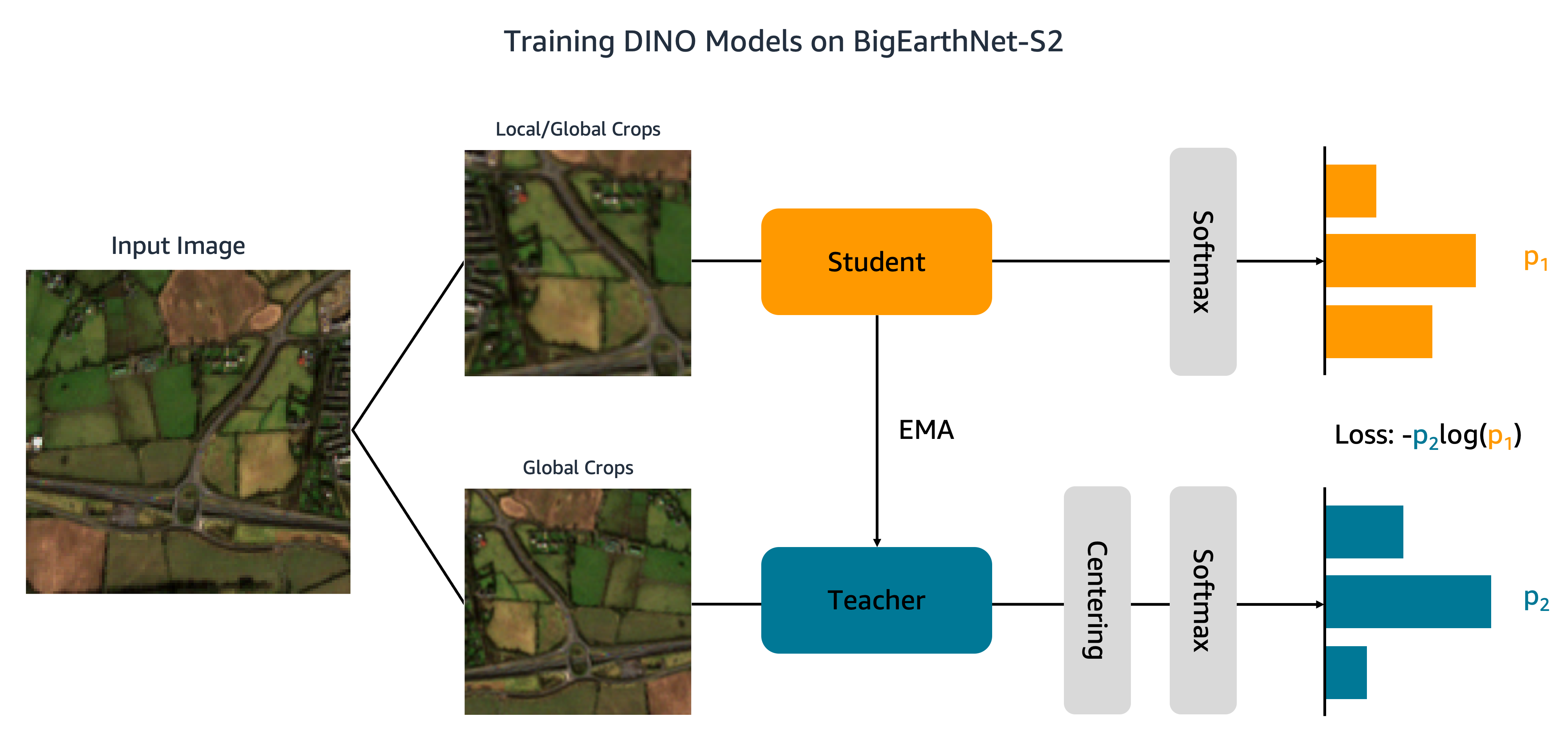
现在我们已经将数据集上传到了Amazon S3,我们开始在BigEarthNet-S2上训练DINO模型。如下图所示,DINO算法将输入图像的不同全局和局部裁剪传递给学生和教师网络。通过最小化交叉熵损失,学生网络被教授去匹配教师网络的输出。学生和教师权重通过指数移动平均(EMA)进行连接。
我们对原始的DINO代码进行了两个修改。首先,我们创建了一个自定义的PyTorch数据集类来加载BigEarthNet-S2图像。代码最初是为处理ImageNet数据而编写的,它期望图像按类别存储。然而,BigEarthNet-S2是一个多标签数据集,每个图像都存储在自己的子文件夹中。我们的数据集类使用元数据中存储的文件路径来加载每个图像:
import pandas as pd
import rasterio
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
OPTICAL_MAX_VALUE = 2000
LAND_COVER_LABELS = [
"城市地面",
"工业或商业单位",
"耕地",
"常年作物",
"牧草地",
"复杂的耕作模式",
"主要由农业占据,具有大片天然植被的土地",
"农林业区域",
"阔叶林",
"针叶林",
"混合林",
"天然草地和稀疏植被区域",
"沼泽、荒地和硬叶植被区域",
"过渡性林地、灌丛",
"沙滩、沙丘、沙地",
"内陆湿地",
"沿海湿地",
"内陆水域",
"海洋水域",
]
class BigEarthNetDataset(Dataset):
"""
PyTorch数据集类,从元数据文件中加载BigEarthNet-S2图像。
Args:
metadata_file: 元数据文件路径
data_dir: BigEarthNet-S2数据所在的目录
split: 训练、验证或测试拆分
transform: 应用于输入图像的变换
"""
def __init__(self, metadata_file, data_dir, split="train", transform=None):
# 从元数据中获取图像文件路径
metadata = pd.read_parquet(metadata_file)
self.metadata_split = metadata[metadata["original_split"] == split]
self.data_dir = data_dir
self.patch_names = self.metadata_split["name"].tolist()
# 对地表覆盖标签进行独热编码
multiclass_labels = self.metadata_split.new_labels.tolist()
self.labels = self.get_multi_onehot_labels(multiclass_labels)
# 变换
self.transform = transform
def __len__(self):
"""返回数据集的长度。"""
return len(self.metadata_split)
def __getitem__(self, index):
"""返回给定索引的图像和标签。"""
patch_name = self.patch_names[index]
file_path = os.path.join(self.data_dir, patch_name)
# 生成RGB图像
r_channel = rasterio.open(os.path.join(file_path, patch_name + "_B04.tif")).read(1)
g_channel = rasterio.open(os.path.join(file_path, patch_name + "_B03.tif")).read(1)
b_channel = rasterio.open(os.path.join(file_path, patch_name + "_B02.tif")).read(1)
image = np.stack([r_channel, g_channel, b_channel], axis=2)
image = image / OPTICAL_MAX_VALUE * 255
image = np.clip(image, 0, 225).astype(np.uint8)
# 应用图像变换
image = Image.fromarray(image, mode="RGB")
if self.transform is not None:
image = self.transform(image)
# 加载标签
label = self.labels[index]
return image, label
def get_multi_onehot_labels(self, multiclass_labels):
"""将BEN-19标签转换为独热编码向量。"""
targets = torch.zeros([len(multiclass_labels), len(LAND_COVER_LABELS)])
for index, img_labels in enumerate(multiclass_labels):
for label in img_labels:
index_hot = LAND_COVER_LABELS.index(label)
targets[index, index_hot] = 1.
return targets这个数据集类在训练过程中在main_dino.py中被调用。虽然代码包括一个函数来对地表覆盖标签进行独热编码,但是这些标签并没有被DINO算法使用。
我们对DINO代码进行的第二个更改是添加对SMDDP的支持。我们将以下代码添加到util.py文件中的init_distributed_mode函数中:
util.py文件中的init_distributed_mode函数:
def init_distributed_mode(args):
if json.loads(
os.environ.get('SM_FRAMEWORK_PARAMS', '{}'))
.get('sagemaker_distributed_dataparallel_enabled', False)
):
# 使用SMDDP启动训练
dist.init_process_group(backend='smddp')
args.word_size = dist.get_world_size()
args.gpu = int(os.environ['LOCAL_RANK'])通过这些调整,我们可以使用SageMaker在BigEarthNet-S2上训练DINO模型。要在多个GPU或实例上进行训练,我们创建一个SageMaker PyTorch Estimator,该Estimator接收DINO训练脚本、图像和元数据文件路径以及训练超参数:
import time
from sagemaker.pytorch import PyTorch
# 最终模型工件上传的输出存储桶
DINO_OUTPUT_BUCKET = 'dino-models'
# 训练实例上的路径
sm_metadata_path = '/opt/ml/input/data/metadata'
sm_data_path = '/opt/ml/input/data/train'
sm_output_path = '/opt/ml/output/data'
sm_checkpoint_path = '/opt/ml/checkpoints'
# 训练作业名称
dino_base_job_name = f'dino-model-{int(time.time())}'
# 创建SageMaker Estimator
estimator = PyTorch(
base_job_name=dino_base_job_name,
source_dir='path/to/aerial_featurizer',
entry_point='main_dino.py',
role=role,
framework_version="1.12",
py_version="py38",
instance_count=1,
instance_type="ml.p3.16xlarge",
distribution = {'smdistributed':{'dataparallel':{'enabled': True}}},
volume_size=100,
sagemaker_session=sagemaker_session,
hyperparameters = {
# 传递给入口点脚本的超参数
'arch': 'vit_small',
'patch_size': 16,
'metadata_dir': sm_metadata_path,
'data_dir': sm_data_path,
'output_dir': sm_output_path,
'checkpoint_dir': sm_checkpoint_path,
'epochs': 100,
'saveckp_freq': 20,
},
max_run=24*60*60,
checkpoint_local_path = sm_checkpoint_path,
checkpoint_s3_uri =f's3://{DINO_OUTPUT_BUCKET}/checkpoints/{base_job_name}',
debugger_hook_config=False,
)这段代码指定我们将使用一个小的视觉Transformer模型(2100万个参数)和一个大小为16的patch进行100个epochs的训练。为了减少初始数据下载时间,最好为每个训练作业创建一个新的checkpoint_s3_uri。由于我们使用了SMDDP,所以我们必须在ml.p3.16xlarge、ml.p3dn.24xlarge或ml.p4d.24xlarge实例上进行训练。这是因为SMDDP仅对最大的多GPU实例启用。如果要在较小的实例类型上进行训练而不使用SMDDP,则需要从Estimator中删除distribution和debugger_hook_config参数。
创建了SageMaker PyTorch Estimator之后,我们通过调用fit方法来启动训练作业。我们使用Amazon S3的URI指定输入训练数据,包括BigEarthNet-S2的元数据和图像:
# 调用fit开始训练
estimator.fit(
inputs={
'metadata': 's3://bigearthnet-s2-dataset/metadata/',
'train': 's3://bigearthnet-s2-dataset/data_rgb/',
},
wait=False
)SageMaker会启动实例,复制训练脚本和依赖项,并开始DINO训练。我们可以使用以下命令从Jupyter笔记本监视训练作业的进度:
# 监视训练
training_job_name = estimator.latest_training_job.name
attached_estimator = PyTorch.attach(training_job_name)
attached_estimator.logs()我们还可以在SageMaker控制台的训练作业下监控实例指标并查看日志文件。在下面的图中,我们绘制了在ml.p3.16xlarge实例上使用批量大小为128训练的DINO模型的GPU利用率和损失函数。
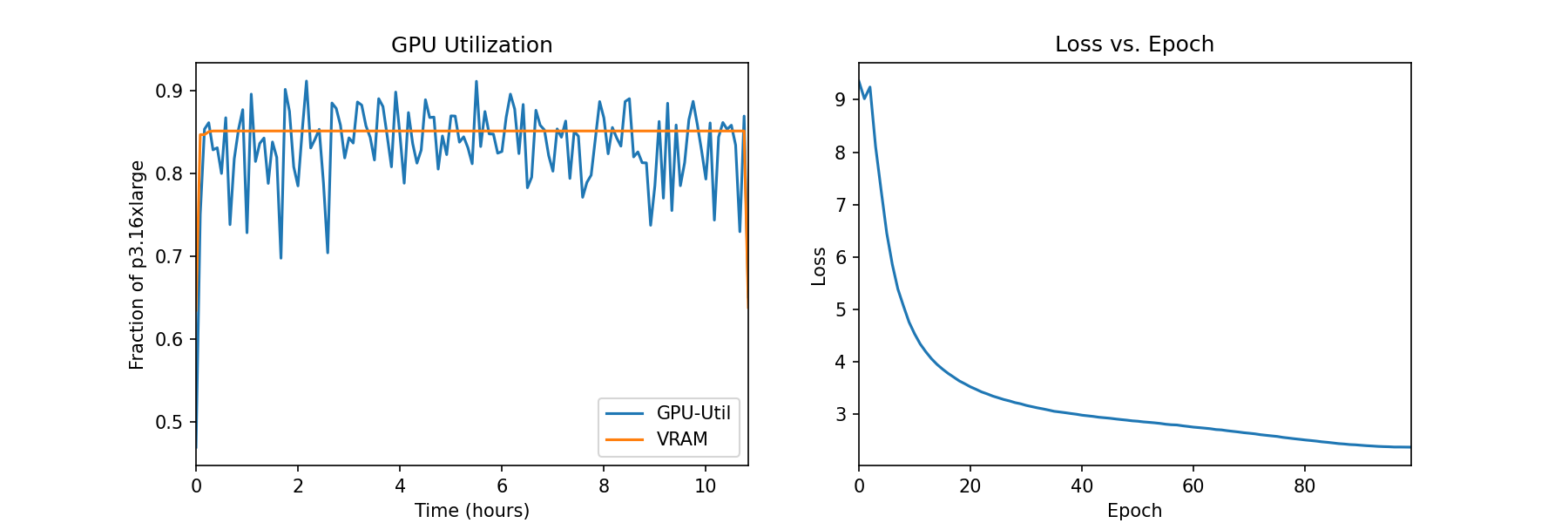
在训练过程中,GPU利用率占ml.p3.16xlarge容量的83%(8个NVIDIA Tesla V100 GPU),VRAM使用率为85%。损失函数随每个时期稳步减小,表明学生网络和教师网络的输出越来越相似。总体而言,训练需要约11小时。
将迁移学习应用于下游任务
我们训练的DINO模型可以应用于图像分类或分割等下游任务。在本节中,我们使用预训练的DINO特征来预测BigEarthNet-S2数据集中图像的土地覆盖类别。如下图所示,我们在冻结的DINO特征之上训练了一个多标签线性分类器。在本示例中,输入图像与可耕地和牧草地覆盖相关联。
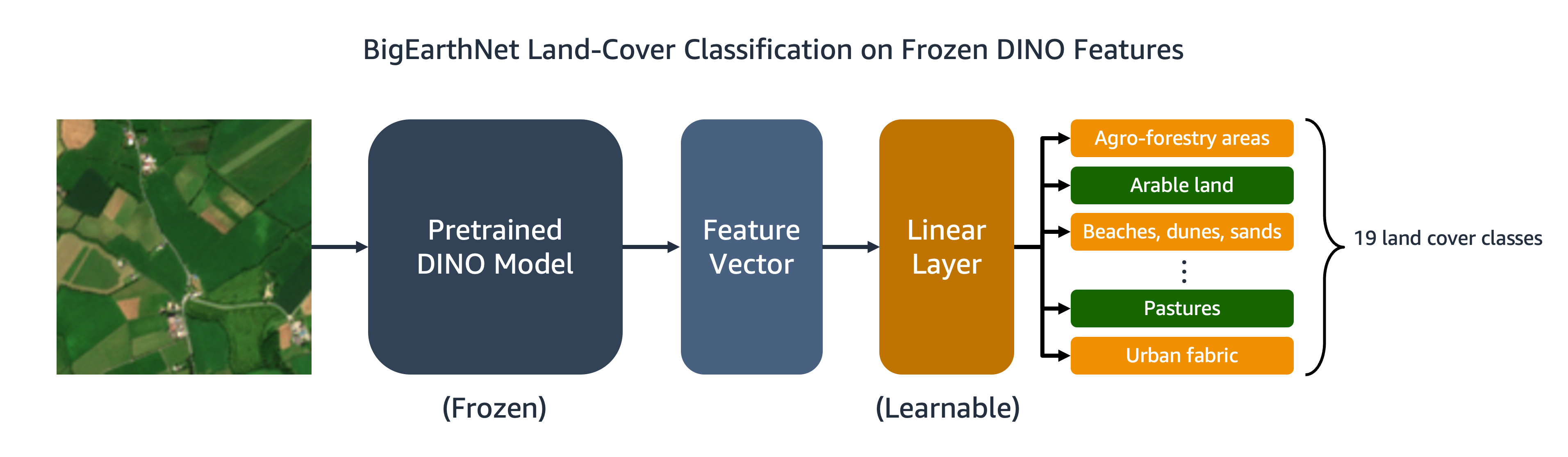
大部分线性分类器的代码已经在原始的DINO存储库中准备好了。我们对特定任务进行了一些调整。与之前一样,我们使用自定义的BigEarthNet数据集在训练和评估过程中加载图像。图像的标签被独热编码为19维二进制向量。我们使用二元交叉熵作为损失函数,并计算平均精度来评估模型的性能。
为了训练分类器,我们创建了一个SageMaker PyTorch Estimator,运行训练脚本eval_linear.py。训练超参数包括DINO模型架构的详细信息和模型检查点的文件路径:
# 上传最终模型工件的输出存储桶
CLASSIFIER_OUTPUT_BUCKET = 'land-cover-classification'
# DINO检查点名称
checkpoint = 'checkpoint.pth'
# 训练实例上的路径
sm_dino_path = f'/opt/ml/input/data/dino_checkpoint'
sm_dino_checkpoint = f'{sm_dino_path}/{checkpoint}'
# 训练作业名称
classifier_base_job_name = f'linear-classifier-{int(time.time())}'
# 创建Estimator
estimator = PyTorch(
base_job_name=classifier_base_job_name,
source_dir='path/to/aerial_featurizer',
entry_point = 'eval_linear.py',
role=role,
framework_version='1.12',
py_version='py38',
instance_count=1,
instance_type='ml.p3.2xlarge',
sagemaker_session=sagemaker_session,
hyperparameters = {
# 传递给入口点脚本的超参数
'arch': 'vit_small',
'pretrained_weights': sm_dino_checkpoint,
'epochs': 50,
'data_dir': sm_data_path,
'metadata_dir': sm_metadata_path,
'output_dir': sm_checkpoint_path,
'num_labels': 19,
},
max_run=1*60*60,
checkpoint_local_path = sm_checkpoint_path,
checkpoint_s3_uri =f's3://{CLASSIFIER_OUTPUT_BUCKET}/checkpoints/{base_job_name}',
)我们使用fit方法开始训练作业,提供BigEarthNet-S2元数据和训练图像以及DINO模型检查点的Amazon S3位置:
# 调用fit开始训练
estimator.fit(
inputs={
'metadata': 's3://bigearthnet-s2-dataset/metadata/',
'dataset': 's3://bigearthnet-s2-dataset/data_rgb/',
'dino_checkpoint': f's3://bigearthnet-s2-dataset/dino-models/checkpoints/{dino_base_job_name}',
},
wait=False
)训练完成后,我们可以使用SageMaker批量转换或SageMaker处理在BigEarthNet-S2测试集上进行推理。在下表中,我们比较了线性模型在测试集图像上使用两种不同的DINO图像表示的平均精度。第一个模型,ViT-S/16(ImageNet),是DINO存储库中包含的小型视觉变换器检查点,它是使用ImageNet数据集中的前向图像进行预训练的。第二个模型,ViT-S/16(BigEarthNet-S2),是我们通过在航拍图像上进行预训练而生成的模型。
| 模型 | 平均精度 |
| ViT-S/16 (ImageNet) | 0.685 |
| ViT-S/16 (BigEarthNet-S2) | 0.732 |
我们发现,与在ImageNet上预训练的DINO模型相比,预训练在BigEarthNet-S2上的DINO模型在土地覆盖分类任务中具有更好的迁移效果,平均精度提高了6.7%。
清理
在完成DINO训练和迁移学习后,我们可以清理资源以避免产生费用。我们停止或删除笔记本实例,并从Amazon S3中删除任何不需要的数据或模型文件。
结论
本文演示了如何使用SageMaker在航空影像上训练DINO模型。我们使用了SageMaker PyTorch Estimators和SMDDP来生成BigEarthNet-S2图像的表示,而无需显式标签。然后,我们将DINO特征转移到下游图像分类任务中,该任务涉及预测BigEarthNet-S2图像的土地覆盖类别。对于这个任务,与在ImageNet上预训练相比,对卫星图像进行预训练可以提高6.7%的平均精度。
您可以将此解决方案用作在大规模无标签航空和卫星图像数据集上训练DINO模型的模板。要了解有关DINO和在SageMaker上构建模型的更多信息,请查看以下资源:
- Emerging Properties in Self-Supervised Vision Transformers
- 使用PyTorch和Amazon SageMaker
- SageMaker的数据并行性库






