汤森路透(Thomson Reuters)在不到6周的时间内开发了Open Arena,一个企业级大型语言模型平台的游乐场
Thomson Reuters developed Open Arena, an enterprise-level language model platform playground, in less than 6 weeks.
这篇文章由Thomson Reuters的Shirsha Ray Chaudhuri、Harpreet Singh Baath、Rashmi B Pawar和Palvika Bansal共同撰写。
Thomson Reuters(TR)是一家全球内容和技术驱动型公司,几十年来一直在其专业信息产品中使用人工智能(AI)和机器学习(ML)。Thomson Reuters Labs是该公司专门的创新团队,在AI和自然语言处理(NLP)方面发挥了重要作用。1992年,Westlaw Is Natural(WIN)的推出是一个重要的里程碑。这项技术是其类别中最早采用NLP进行更高效自然的法律研究的技术之一。快进到2023年,Thomson Reuters通过快速创新、创造性解决方案和强大的技术继续定义专业人士的未来。
生成AI的引入为Thomson Reuters提供了与客户合作,并再次推动他们工作方式的机会,帮助专业人士提取见解并自动化工作流程,使他们能够将时间集中在最重要的事情上。尽管Thomson Reuters正在推动生成AI和其他技术为现代专业人士所能做的事情的界限,但它如何利用这项技术的力量来为自己的团队提供帮助呢?
Thomson Reuters非常注重在每个团队和业务领域的同事中提高对AI的认识和理解。从什么是AI以及ML的工作原理的基本原则开始,它提供了一系列面向全公司的AI意识课程,包括网络研讨会、培训资料和小组讨论。在这些课程中,同事们开始涌现出如何使用AI的想法,他们考虑如何使用工具帮助他们在日常任务中使用AI,并为客户提供服务。
在本文中,我们将讨论Thomson Reuters Labs如何与AWS合作创建了Open Arena,Thomson Reuters的企业级大型语言模型(LLM)平台。最初的概念来自AI/ML Hackathon,得到了Simone Zucchet(AWS解决方案架构师)和Tim Precious(AWS客户经理)的支持,并在不到6周的时间内使用AWS服务开发成为产品,并得到AWS的支持。AWS Lambda、Amazon DynamoDB、Amazon SageMaker以及预构建的Hugging Face深度学习容器(DLC)等AWS托管服务有助于推动创新的速度。Open Arena在一个安全可控的环境中帮助解锁了全公司范围内对生成AI的实验。
深入了解Open Arena,它是一个基于Web的游乐场,允许用户使用LLM的一系列工具进行实验。这为那些没有编码背景但想要探索TR生成AI的可能性的Thomson Reuters员工提供了非编程的访问方式。Open Arena的开发旨在从多个语料库中快速获取答案,例如用于客户支持代理商的快速答案,从网站获取快速答案的解决方案,摘要和验证文档中的要点的解决方案等等。随着Thomson Reuters员工的经验不断涌现新想法以及生成AI领域的新趋势出现,Open Arena的功能不断增强。这一切都得益于作为解决方案基础的模块化无服务器AWS架构。
构思Open Arena
Thomson Reuters的目标很明确:构建一个安全、可靠、用户友好的企业级游乐场——“开放竞技场”。在这里,内部团队不仅可以探索和测试公司内部开发的各种LLM,还可以利用与AWS和Hugging Face合作的开源社区的LLM,通过将LLM的能力与Thomson Reuters的大量公司数据相结合,发现独特的用例。这种平台将增强团队生成创新解决方案的能力,提高Thomson Reuters向客户提供的产品和服务的质量。
设想中的Open Arena平台将为Thomson Reuters全球内部团队提供服务,为他们提供与LLM自由互动的游乐场。在受控环境中进行这种互动的能力将使团队能够发现在与这些复杂模型进行较少直接接触时可能不明显的新应用和方法。
构建Open Arena
构建Open Arena是一个多方面的过程。我们旨在利用AWS的无服务器和ML服务的能力来打造一个方案,使Thomson Reuters员工能够无缝地尝试最新的LLM。我们看到这些服务的潜力不仅在于提供可扩展性和可管理性,而且在于确保成本效益。
解决方案概述
从创建稳健的模型部署和微调环境,到确保细致的数据管理和提供无缝的用户体验,TR需要每个方面都与多个AWS服务集成。Open Arena的架构旨在全面而直观,平衡复杂性和易用性。以下图示了这个架构。

SageMaker作为支撑,将模型部署为SageMaker终端节点,为微调模型提供了强大的环境。我们利用了AWS提供的SageMaker DLC上的Hugging Face来增强我们的部署流程。此外,我们使用了SageMaker Hugging Face推理工具包和Accelerate库来加速推理过程,有效处理运行复杂且资源密集的模型的需求。这些全面的工具对于确保我们的LLMs快速且无缝地部署起到了至关重要的作用。由Amazon API Gateway触发的Lambda函数管理API,确保对数据的细致预处理和后处理。
为了提供无缝的用户体验,我们采用了安全的API Gateway将托管在Amazon Simple Storage Service(Amazon S3)上的前端与Lambda后端连接起来。我们将前端部署为S3存储桶上的静态站点,借助Amazon CloudFront和我们公司的单一登录机制来确保用户认证。
Open Arena经过设计,可以通过REST API与多个LLMs无缝集成。这确保了平台足够灵活,可以快速响应和集成新的最先进模型,以适应快节奏的生成式AI领域的发展和发布。从一开始,Open Arena的架构就被设计为提供一个安全可靠的企业级AI/ML平台,以便汤森路透的员工可以快速尝试任何最新推出的最先进的LLM。使用SageMaker上的Hugging Face模型可以让团队在安全环境中进行模型微调,因为所有数据都经过加密,不离开虚拟私有云(VPC),确保数据保持私密和机密。
我们选择的NoSQL数据库服务是DynamoDB,它高效地存储和管理各种数据,包括用户查询、响应、响应时间和用户数据。为了简化开发和部署流程,我们采用了AWS CodeBuild和AWS CodePipeline进行持续集成和持续交付(CI/CD)。通过Amazon CloudWatch监控基础设施并确保其正常运行,提供了自定义仪表板和全面的日志记录功能。
模型开发和集成
Open Arena的核心是其多样化的LLMs,包括开源模型和内部开发的模型。这些模型经过微调,可以根据特定的用户提示提供响应。
在Open Arena中,我们尝试了不同的LLMs来应对不同的用例,包括Flan-T5-XL、Open Assistant、MPT、Falcon以及使用参数高效微调技术在可用的开源数据集上微调的Flan-T5-XL。我们使用Hugging Face的bitsandbytes集成来尝试各种量化技术。这使我们可以优化LLMs的性能和效率,为更大的创新铺平道路。在选择用作这些用例背后的模型时,我们考虑了不同的方面,例如:
- 在构建应用程序时与LLMs一起增加效率 – 使用熟悉的控件和与AWS深度和广度集成,快速集成和部署最先进的LLMs到我们在AWS上运行的应用程序和工作负载中
- 安全定制 – 确保用于微调LLMs的所有数据都保持加密状态,不离开VPC
- 灵活性 – 能够从广泛选择的AWS原生和开源LLMs中选择合适的模型以满足我们各种用例的需求
我们一直在思考这样的问题,更大型的模型的更高成本是否能够带来显著的性能提升?这些模型能处理长文档吗?
下图展示了我们的模型架构。

我们一直在使用开源法律数据集和汤森路透内部数据集评估这些模型在上述方面的表现,以便针对特定的用例进行评估。
对于基于内容的用例(需要从特定语料库中获取答案的体验),我们已经建立了一个检索增强生成(RAG)流程,该流程将根据查询获取最相关的内容。在这种流程中,将文档分割成块,然后创建嵌入并存储在OpenSearch中。为了获取最佳匹配的文档或块,我们使用基于双编码器和交叉编码器模型的检索/重新排序器方法。检索到的最佳匹配结果与查询一起作为输入传递给LLM,生成最佳响应。
汤森路透(Thomson Reuters)内部内容与LLM体验的整合对于用户从这些模型中提取更相关和有洞察力的结果起到了重要作用。更重要的是,它引发了每个团队对于在业务工作流程中采用AI解决方案可能性的想法。
开放竞技场瓷砖:促进用户互动
开放竞技场采用了用户友好的界面,为每个体验设计了预设的启用瓷砖,如下图所示。这些瓷砖作为预设的交互,满足用户的特定需求。
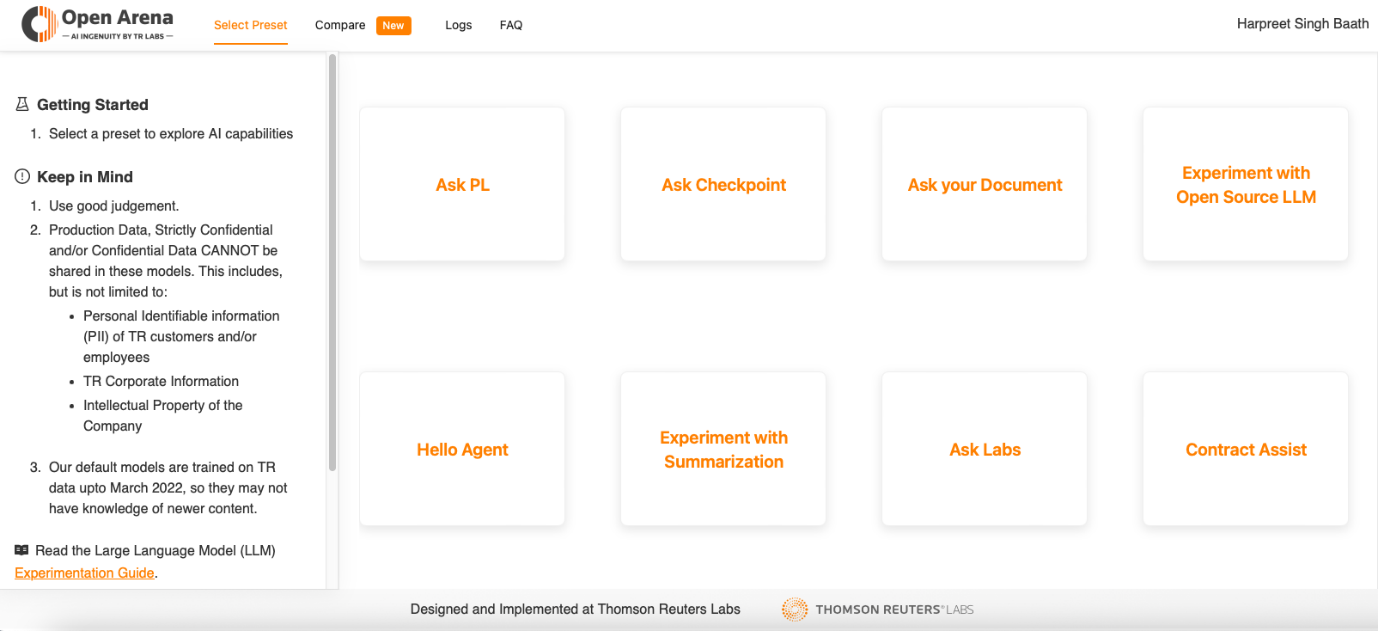
例如,与开源LLM实验瓷砖一起,打开了与开源LLM的类似聊天的交互渠道。

“询问您的文档”瓷砖允许用户上传文档并提出与LLM内容相关的具体问题。”摘要实验”瓷砖使用户能够将大量文本提炼成简洁的摘要,如下图所示。

这些瓷砖简化了用户对于AI工作解决方案的使用和平台内的导航过程,激发创造力并促进创新用例的发现。
开放竞技场的影响
开放竞技场的推出标志着汤森路透在促进创新和协作文化方面迈出的重要一步。该平台的成功是不可否认的,其好处在公司内部迅速显现。
开放竞技场直观的基于聊天的设计不需要重要的技术知识,使其适用于全球不同团队和不同职位角色。这种易用性提高了参与水平,鼓励更多用户探索平台并揭示创新用例。
在不到一个月的时间里,开放竞技场为汤森路透全球范围内的超过1,000名月度内部用户提供服务,平均每个用户的互动时间为5分钟。开放竞技场的目标是促进内部TR LLM实验和众包LLM用例的创建,其推出导致了新的用例涌现,有效利用了LLM与汤森路透庞大的数据资源的力量。
以下是我们的一些用户对于开放竞技场的评价:
“开放竞技场为公司各个部门的员工提供了一个实践、动手的机会,以实验LLM。阅读AI工具和自己使用它们是两回事。这个平台加速了汤森路透在AI学习方面的努力。”
– Abby Pinto,人力资源部人才发展解决方案负责人
“OA(开放竞技场)使我能够在汤森路透德语服务的困难新闻翻译问题上进行实验,而传统的翻译软件无法处理,并且可以在一个安全的环境中使用我们的实际报道,而不用担心数据泄漏。OA团队对于新功能的建议非常积极响应,这是你只能在其他软件中梦寐以求的服务。”
– Scot W. Stevenson,柏林德语服务高级突发新闻记者
“当我使用开放竞技场时,我想到为我们的客户支持团队构建一个类似的界面的想法。这个平台帮助我们重新想象了与GenAI的可能性。”
– Marcel Batista,运营客户服务与支持经理
“由AWS无服务器服务、Amazon SageMaker和Hugging Face提供支持的开放竞技场帮助我们快速向同事们展示了尖端的LLM和生成式AI工具,推动了全企业的创新。”
– Shirsha Ray Chaudhuri,汤森路透实验室研究工程总监
从更广泛的角度来看,开放竞技场的引入对公司产生了深远的影响。它不仅增加了员工对人工智能的认识,还激发了创新和协作的精神。该平台使团队能够共同探索、实验和生成想法,营造了一个能够将创新概念变成现实的环境。
此外,开放竞技场对汤森路透的人工智能服务和产品产生了积极影响。该平台作为人工智能的沙盒,使团队能够在将其纳入我们的产品之前,识别和完善人工智能应用。因此,这加速了汤森路透人工智能服务的发展和提升,为客户提供不断演进且处于技术前沿的解决方案。
结论
在快节奏的人工智能世界中,继续推进是至关重要的,而汤森路透致力于做到这一点。开放竞技场的团队不断努力添加更多功能并增强平台的能力,利用亚马逊底层设施和亚马逊SageMaker Jumpstart等AWS服务,确保其仍然是我们团队的宝贵资源。随着我们的前进,我们的目标是与不断演化的生成式人工智能和LLMs领域保持步调一致。AWS提供了TR所需的服务,以跟上不断演化的生成式人工智能领域。
除了持续开发开放竞技场平台外,我们还积极致力于推广该平台所产生的众多应用案例。这将使我们能够为客户提供更先进、更高效的人工智能解决方案,以满足他们的特定需求。此外,我们将继续培养创新和协作的文化,使我们的团队能够探索人工智能技术的新思路和应用。
在这个令人兴奋的旅程中,我们相信开放竞技场将在推动汤森路透的创新和协作方面发挥关键作用。通过保持在人工智能进展的前沿,我们将确保我们的产品和服务不断演进,满足客户不断变化的需求。






