为什么OpenAI的API对非英语语言来说更昂贵
OpenAI API cost higher for non-English languages.
超越文字:字节对编码和Unicode编码如何影响定价差异

在我最近发表的关于如何估计OpenAI API的成本的文章中,我收到了一个有趣的评论,有人注意到OpenAI API在其他语言中(如使用中文、日文或韩文)比在英语中更昂贵。
我之前没有意识到这个问题,但很快意识到这是一个活跃的研究领域:今年年初,Petrov等人的一篇名为“语言模型分词器引入语言之间的不公平性”的论文[2]表明,“相同的文本翻译成不同的语言可能在标记长度上有明显不同,有时差异高达15倍。”
回顾一下,标记化是将文本分割成一系列标记的过程,这些标记是文本中常见的字符序列。
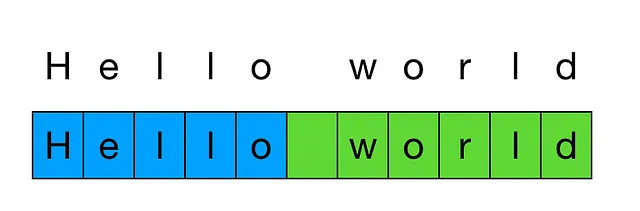
标记化长度的差异是一个问题,因为OpenAI API的计费单位是1000个标记。因此,如果在可比较的文本中有多达15倍的标记,这将导致15倍的API费用。
实验:不同语言中的标记数量
让我们将短语“Hello world”翻译成日语(こんにちは世界)并转录为印地语(हैलो वर्ल्ड)。当我们使用OpenAI GPT模型中使用的cl100k_base分词器对新短语进行标记化时,我们得到以下结果(您可以在本文末尾找到我用于这些实验的代码):
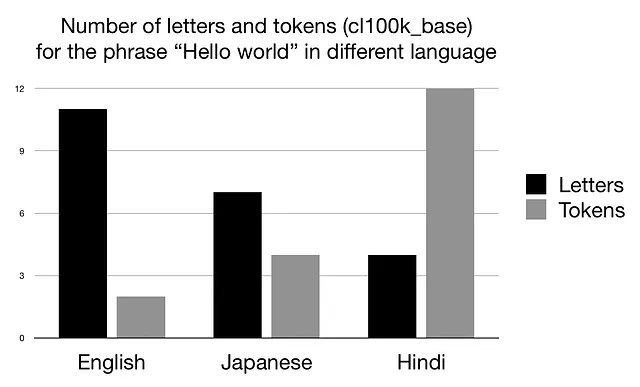
从上面的图表中,我们可以得出两个有趣的观察结果:
- 字母数…





