使用SQL了解数据科学职业趋势
了解数据科学职业趋势

在一个数据是新石油的世界中,了解数据科学职业的细微差别比以往任何时候都更加重要。无论您是一个寻找数据机会的数据爱好者,还是一个老手正在探索机会,使用 SQL 可以为数据科学工作市场提供洞察。
我希望您渴望知道哪些数据科学职位最具吸引力,或者哪些职位提供最高的薪水。或者,您想知道经验水平如何与数据科学的平均工资相关联?
在本文中,我们将深入探讨数据科学职位市场,回答所有这些问题(以及更多)。让我们开始吧!
数据集工资趋势
本文将使用的数据集旨在揭示从 2021 年到 2023 年的数据科学领域的工资模式。通过重点关注工作经历、职位和公司地点等因素,它为该行业的工资分布提供了重要的洞察。
本文将回答以下问题:
- 不同经验水平的平均工资是什么样的?
- 数据科学中最常见的职位是什么?
- 工资分布如何随公司规模变化?
- 数据科学职位主要位于哪些地理位置?
- 哪些职位提供数据科学的最高工资?
您可以从 Kaggle 上下载这些数据。
1. 不同经验水平的平均工资是什么样的?
在此 SQL 查询中,我们正在查找不同经验水平的平均工资。GROUP BY 子句按经验水平对数据进行分组,AVG 函数计算每个组的平均工资。
这有助于了解领域经验如何影响收入潜力,对于您在规划数据科学职业道路时至关重要。让我们看看代码。
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;现在让我们使用 Python 来可视化这个输出。
这是代码。
# 导入绘图所需的库
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图形的样式
sns.set(style="whitegrid")
# 初始化用于存储图形的列表
graphs = []
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('不同经验水平的平均工资')
plt.xlabel('经验水平')
plt.ylabel('平均工资(美元)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()现在让我们比较入门级和有经验的以及中级和高级的工资。
让我们从入门级和有经验的开始。这是代码。
# 筛选入门级和有经验的数据
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# 筛选中级和高级的数据
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# 绘制入门级和有经验的图形
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('平均工资:入门级 vs 有经验')
plt.xlabel('经验水平')
plt.ylabel('平均工资(美元)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()这是图形。
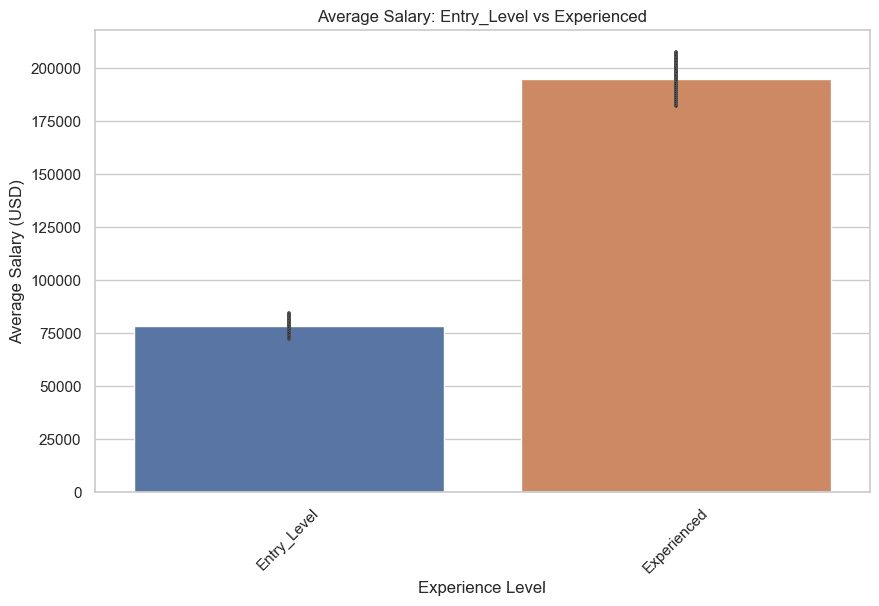
现在让我们绘制中级和高级的图形。这是代码。
# 绘制中级和高级的图形
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('平均工资:中级 vs 高级')
plt.xlabel('经验水平')
plt.ylabel('平均工资(美元)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show() 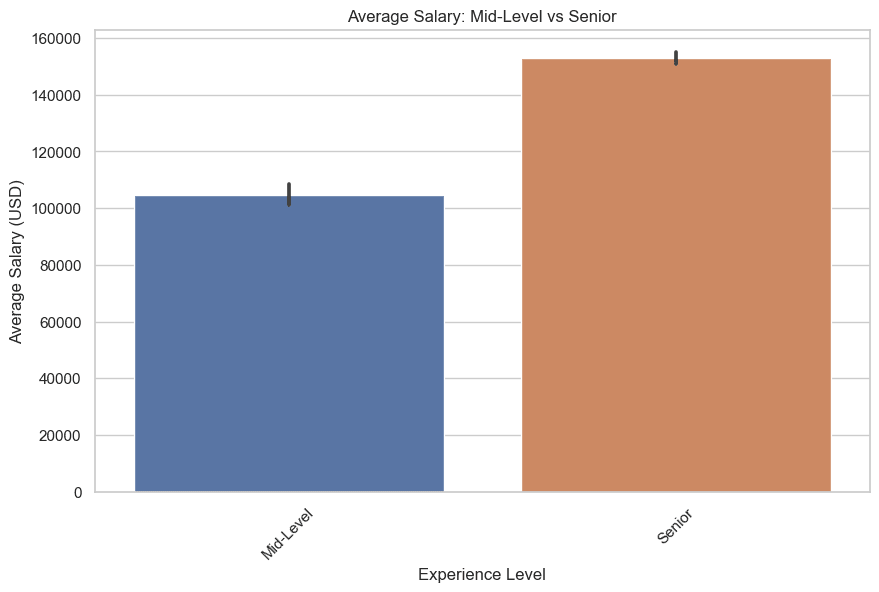
2. 数据科学中最常见的职位是什么?
在这里,我们提取了数据科学中最常见的前10个职位。COUNT函数用于计算每个职位出现的次数,并按照次数降序排序,以获取最常见的职位。
这些信息可以帮助你了解就业市场的需求,指导你确定目标职位。让我们看看代码。
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
好的,现在我们来使用Python对这个查询结果进行可视化。
下面是代码。
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('数据科学中最常见的职位')
plt.xlabel('职位数量')
plt.ylabel('职位名称')
graphs.append(plt.gcf())
plt.show()
让我们来看看图表。
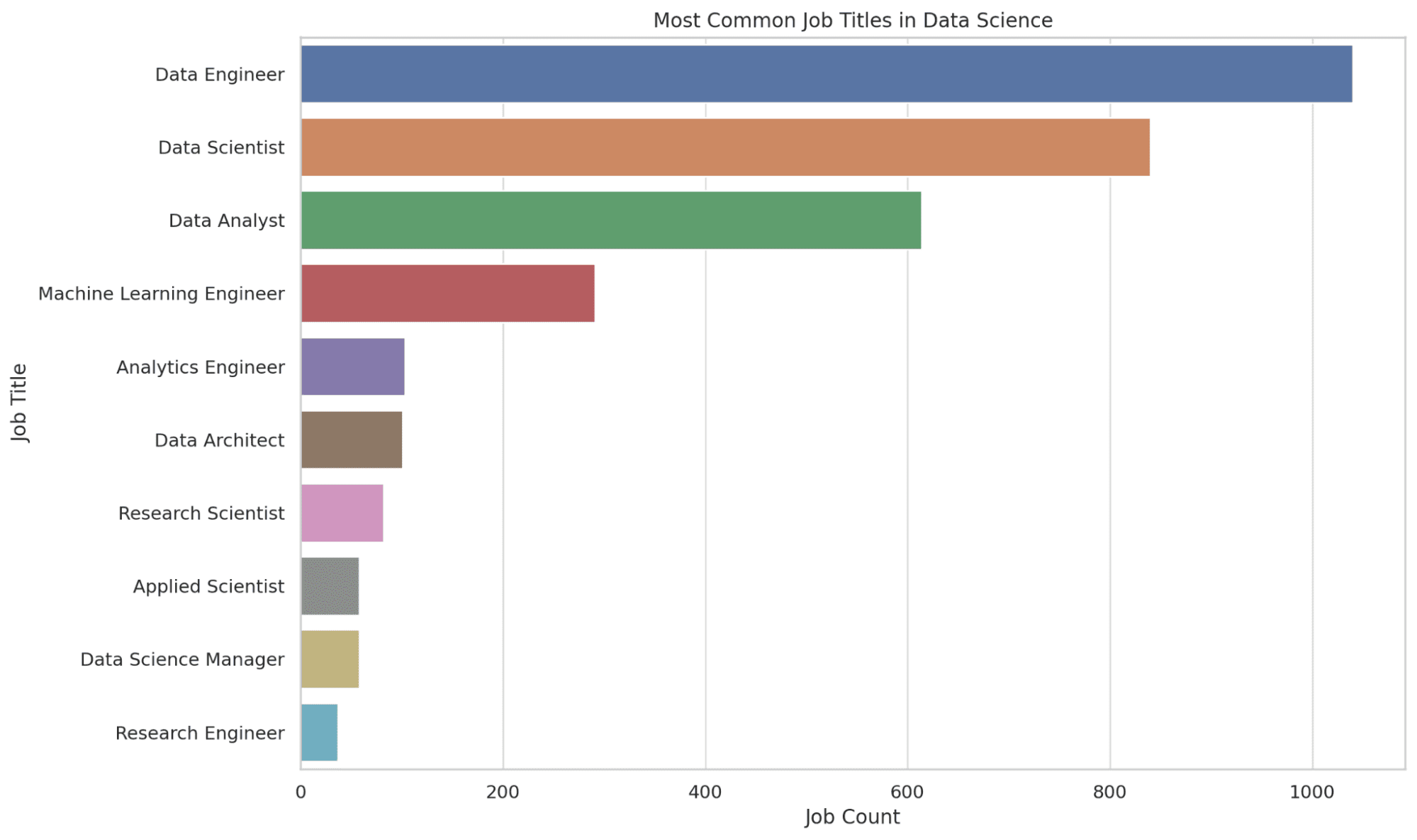
3. 薪资分布如何随公司规模变化?
在这个查询中,我们提取每个公司规模分组的平均工资、最低工资和最高工资。使用AVG、MIN和MAX等聚合函数可以全面了解薪资与公司规模之间的关系。
这些数据对于理解你可以期望的薪资收入与你希望加入的公司规模之间的关系非常重要,让我们看看代码。
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
现在让我们使用Python来可视化这个查询结果。
下面是代码。
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['小型', '中型', '大型'])
plt.title('按公司规模划分的薪资分布')
plt.xlabel('公司规模')
plt.ylabel('平均薪资(美元)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
下面是输出结果。
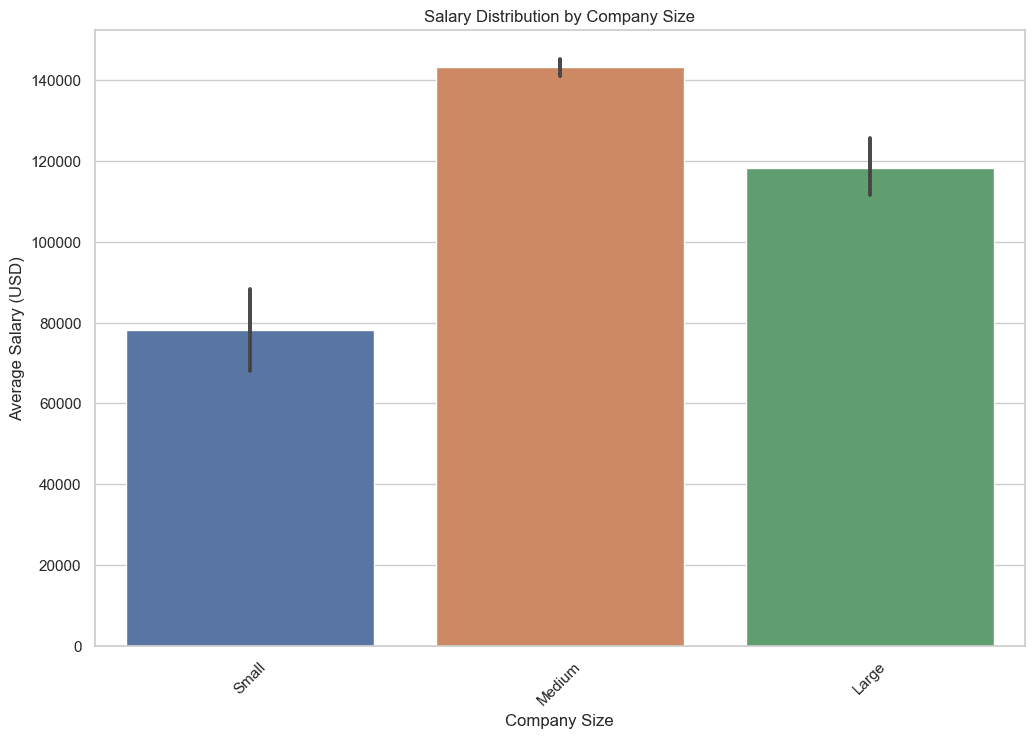
4. 数据科学岗位主要分布在哪些地理位置?
在这里,我们确定了拥有最多数据科学岗位机会的前10个地点。我们使用COUNT函数来确定每个地点的岗位数量,并按照岗位数量降序排列,以突出显示最多机会的地区。
这些信息让读者了解到数据科学岗位的分布重点地区,对于在可能需要搬迁的决策中起到了帮助作用。让我们看看代码。
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
现在让我们使用Python来创建这个查询结果的图表。
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('数据科学岗位的地理分布')
plt.xlabel('岗位数量')
plt.ylabel('公司地点')
graphs.append(plt.gcf())
plt.show()
让我们来看一下下面的图表。
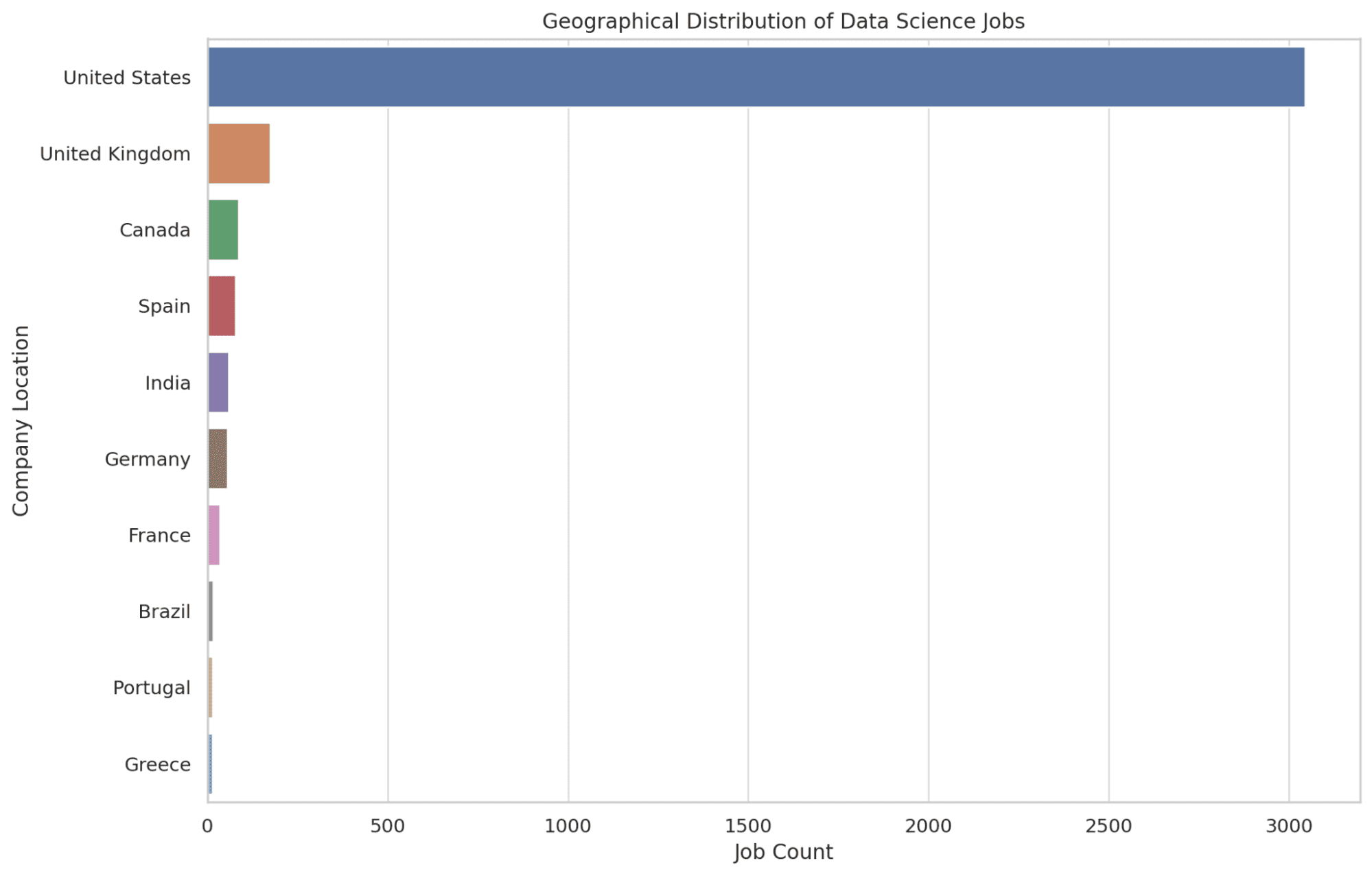
5. 哪些职位提供了数据科学领域最高的薪水?
在这里,我们正在识别数据科学领域中报酬最高的前10个职位。通过使用AVG函数,我们计算每个职位的平均薪水,并按照平均薪水的降序排列,以突出最具吸引力的职位。
您可以通过查看这些数据来激励您的职业发展之旅。让我们继续了解读者如何为这些数据创建Python可视化。
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
以下是输出结果。
(由于我们在上面添加了4张照片,并且还有一张留作缩略图,所以这里无法使用照片,我们有机会使用下面类似的表格来展示输出结果吗?)
| 排名 | 职位名称 | 平均薪水(美元) |
| 1 | 数据科学技术负责人 | 375,000.00 |
| 2 | 云数据架构师 | 250,000.00 |
| 3 | 数据负责人 | 212,500.00 |
| 4 | 数据分析负责人 | 211,254.50 |
| 5 | 首席数据科学家 | 198,171.13 |
| 6 | 数据科学总监 | 195,140.73 |
| 7 | 首席数据工程师 | 192,500.00 |
| 8 | 机器学习软件工程师 | 192,420.00 |
| 9 | 数据科学经理 | 191,278.78 |
| 10 | 应用科学家 | 190,264.48 |
这次,让我们尝试自己创建一个图表。
提示:您可以使用以下提示在ChatGPT中生成此图表的Python代码:
<SQL查询在此>
创建一个Python图表,以可视化数据科学领域中报酬最高的前10个职位,类似于上面给出的SQL查询所得到的见解。
总结
在我们结束对数据科学职业世界多样地域的探索时,希望SQL能成为您可信赖的指南,帮助您挖掘见解的宝藏,支持您的职业决策。
我希望你现在感觉更加有能力了,不仅能够规划你的职业道路,还能够使用SQL将原始数据塑造成有力的故事。因此,让我们迈入一个充满机遇的未来,以数据为指南,以SQL为引领力量!
感谢阅读!Nate Rosidi是一名数据科学家和产品策略师。他还是一名教授分析学的兼职教师,也是StrataScratch的创始人,该平台通过提供来自顶级公司的真实面试问题,帮助数据科学家准备面试。请在Twitter上与他联系:StrataScratch,或者通过LinkedIn连接。






