利用XGBoost进行时间序列预测
XGBoost时间序列预测
XGBoost(eXtreme Gradient Boosting)是一个开源算法,它实现了梯度提升树,并通过额外的改进来提高性能和速度。该算法快速准确地进行预测的能力使其成为许多比赛的首选模型,例如 Kaggle 比赛。
XGBoost 应用的常见情况是用于分类预测,例如欺诈检测,或回归预测,例如房价预测。然而,将 XGBoost 算法扩展到预测时间序列数据也是可能的。它是如何工作的呢?让我们进一步探讨一下。
时间序列预测
- 2023年视频创作和编辑的40多个AI工具
- LlaMA 2 入门 | Meta 的新一代生成式人工智能
- Together AI发布了Llama-2-7B-32K-Instruct:扩展上下文语言处理的突破
数据科学和机器学习中的预测是一种基于随时间收集的历史数据来预测未来数值的技术,无论是在定期间隔还是不规则间隔内。
与普通的机器学习训练数据不同,时间序列预测的数据必须按照连续的顺序并与每个数据点相关。例如,时间序列数据可以包括每月的股票、每周的天气、每日的销售等。
让我们来看一下 Kaggle 上的例子时间序列数据,Daily Climate 数据。
import pandas as pd
train = pd.read_csv('DailyDelhiClimateTrain.csv')
test = pd.read_csv('DailyDelhiClimateTest.csv')
train.head()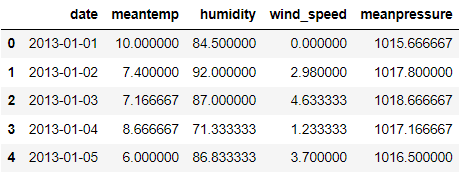
如果我们看一下上面的数据框,每个特征都是每天记录的。日期列表示观察到数据的日期,每个观察值都是相关的。
时间序列预测通常会从数据中提取趋势、季节性和其他模式,以进行预测。一种简单的查看模式的方法是通过可视化它们。例如,我会将我们示例数据集中的平均温度数据可视化。
train["date"] = pd.to_datetime(train["date"])
test["date"] = pd.to_datetime(test["date"])
train = train.set_index("date")
test = test.set_index("date")
train["meantemp"].plot(style="k", figsize=(10, 5), label="train")
test["meantemp"].plot(style="b", figsize=(10, 5), label="test")
plt.title("Mean Temperature Dehli Data")
plt.legend()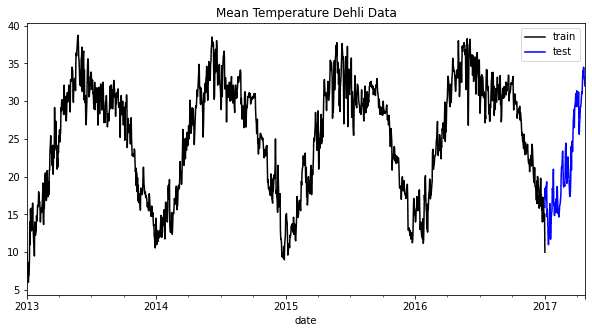
从上图中,我们很容易看出每年都有一个常见的季节性模式。通过融入这些信息,我们可以了解我们的数据如何运作,并决定哪个模型可能适合我们的预测模型。
典型的预测模型包括 ARIMA、向量自回归、指数平滑和 Prophet。然而,我们也可以利用 XGBoost 进行预测。
XGBoost 预测
在准备使用 XGBoost 进行预测之前,我们必须先安装该包。
pip install xgboost安装完成后,我们将准备用于模型训练的数据。理论上,XGBoost 预测将基于单个或多个特征实现回归模型,以预测未来的数值。因此,数据训练也必须是数值型的。此外,为了在我们的 XGBoost 模型中融入时间的变化,我们将把时间数据转化为多个数值特征。
让我们首先创建一个从日期中创建数值特征的函数。
def create_time_feature(df):
df['dayofmonth'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['weekofyear'] = df['date'].dt.weekofyear
return df接下来,我们将应用此函数到训练和测试数据。
train = create_time_feature(train)
test = create_time_feature(test)
train.head()
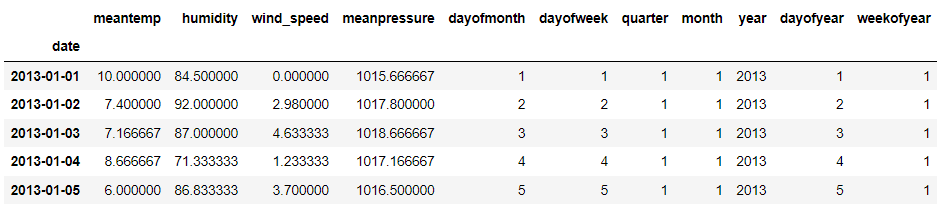
现在所有所需信息都已经准备好了。接下来,我们需要定义我们要预测的内容。在这个例子中,我们将要预测平均温度,并根据上述数据创建训练数据。
X_train = train.drop('meantemp', axis =1)
y_train = train['meantemp']
X_test = test.drop('meantemp', axis =1)
y_test = test['meantemp']
我还将使用其他信息,例如湿度,以展示XGBoost也可以使用多变量方法进行预测。然而,在实践中,我们只会在尝试进行预测时纳入我们已知存在的数据。
让我们通过将数据拟合到模型中来开始训练过程。在当前示例中,除了树的数量之外,我们不会进行太多的超参数优化。
import xgboost as xgb
reg = xgb.XGBRegressor(n_estimators=1000)
reg.fit(X_train, y_train, verbose = False)
在训练过程之后,让我们看一下模型的特征重要性。
xgb.plot_importance(reg)
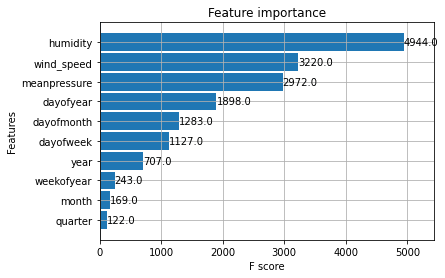
最初的三个特征对于预测来说并不奇怪地帮助不大,但时间特征对于预测也有一定的贡献。让我们尝试在测试数据上进行预测并将其可视化。
test['meantemp_Prediction'] = reg.predict(X_test)
train['meantemp'].plot(style='k', figsize=(10,5), label = 'train')
test['meantemp'].plot(style='b', figsize=(10,5), label = 'test')
test['meantemp_Prediction'].plot(style='r', figsize=(10,5), label = 'prediction')
plt.title('Mean Temperature Dehli Data')
plt.legend()
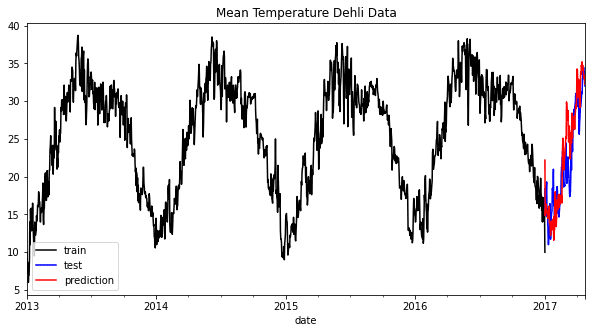
从上图可以看出,预测结果可能略微偏离但仍然遵循总体趋势。让我们根据误差度量指标来评估模型。
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
print('RMSE: ', round(mean_squared_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAE: ', round(mean_absolute_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAPE: ', round(mean_absolute_percentage_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
RMSE: 11.514
MAE: 2.655
MAPE: 0.133
结果显示我们的预测可能有大约13%的误差,而RMSE也显示出了预测的轻微误差。通过超参数优化,模型可以得到改进,但我们已经学会了如何使用XGBoost进行预测。
结论
XGBoost是一个开源算法,通常用于许多数据科学案例和Kaggle竞赛中。通常使用的用例是常见的分类案例,如欺诈检测,或回归案例,如房价预测,但XGBoost也可以扩展到时间序列预测。通过使用XGBoost回归器,我们可以创建一个可以预测未来数值的模型。Cornellius Yudha Wijaya是一位数据科学助理经理和数据作者。在全职工作于Allianz Indonesia的同时,他喜欢通过社交媒体和写作媒体分享Python和数据技巧。






