在Python中利用CuPy发挥GPU的强大能力
充分发挥GPU强大的能力:Python中的CuPy应用

什么是CuPy?
CuPy 是一个与NumPy和SciPy数组兼容的Python库,专为GPU加速计算而设计。通过用CuPy语法替换NumPy,您可以在NVIDIA CUDA或AMD ROCm平台上运行代码。这使您可以使用GPU加速执行与数组相关的任务,从而加快较大数组的处理速度。
通过仅更改几行代码,您可以利用GPU的大规模并行处理能力来显着加快数组操作,如索引,归一化和矩阵乘法。
CuPy还可以访问低级CUDA功能。它允许使用RawKernels将ndarrays传递给现有的CUDA C / C ++程序,通过流将性能流线型,以及启用对CUDA Runtime API的直接调用。
安装CuPy
您可以使用pip安装CuPy,但在此之前,您必须使用以下命令找到正确的CUDA版本。
!nvcc --版本
nvcc:NVIDIA(R)Cuda编译器驱动程序版权所有(c)2005-2022 NVIDIA Corporation建于Wed_Sep_21_10:33:58_PDT_2022Cudacompilation工具,版本11.8,V11.8.89Build cuda_11.8.r11.8/compiler.31833905_0
当前版本的Google Colab似乎使用的是CUDA版本11.8。因此,我们将继续安装cupy-cuda11x版本。
如果您正在运行较旧的CUDA版本,我提供了下表,以帮助您确定要安装的适当CuPy软件包。
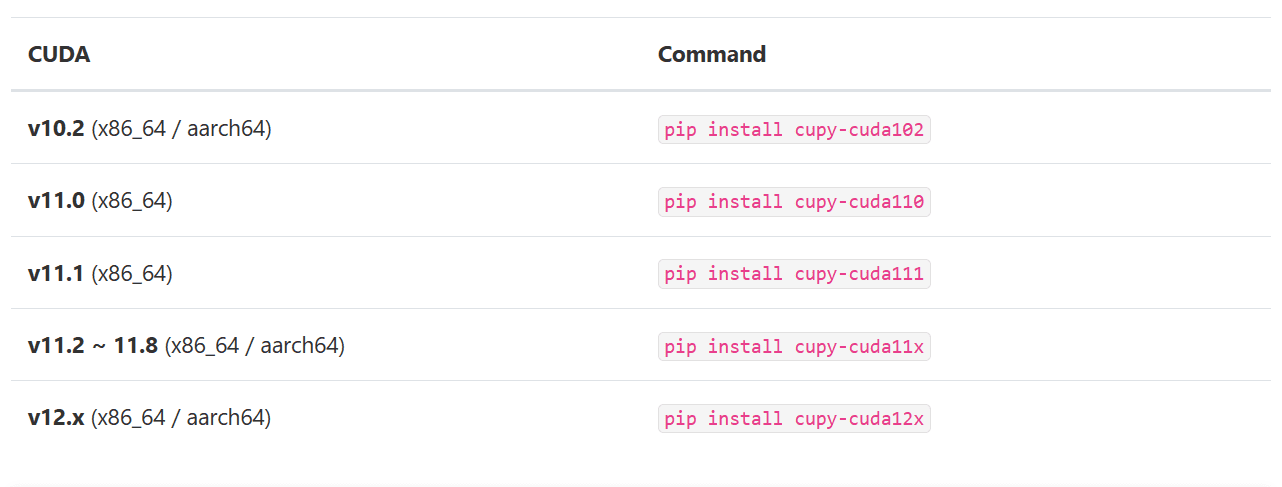
选择正确的版本后,我们将使用pip安装Python软件包。
pip install cupy-cuda11x
如果您安装了Anaconda,您还可以使用conda命令自动检测和安装正确版本的CuPy软件包。
conda install -c conda-forge cupy
CuPy基础
在本节中,我们将比较CuPy的语法与Numpy相似度达到95%。您将使用 cp 而不是 np 。
我们首先将使用Python列表创建一个NumPy和CuPy数组。然后,我们将计算向量的范数。
import cupy与即为np导入 as np
x = [3, 4, 5]
x_np = np.array(x)
x_cp = cp.array(x)
l2_np = np.linalg.norm(x_np)
l2_cp = cp.linalg.norm(x_cp)
print(“ Numpy:”,l2_np)
print(“ CuPY:”,l2_cp)
正如我们所看到的,我们获得了类似的结果。
Numpy:7.0710678118654755
Cupy:7.0710678118654755
要将NumPy转换为CuPy数组,您可以简单地使用 cp.asarray(X)。
x_array = np.array([10, 22, 30])
x_cp_array = cp.asarray(x_array)
type(x_cp_array)
cupy.ndarray
或使用 .get()将CuPy转换为NumPy数组。
x_np_array = x_cp_array.get()
type(x_np_array)
numpy.ndarray
性能比较
在这一部分中,我们将比较NumPy和CuPy的性能。
我们将使用time.time()来计时代码的执行时间。然后,我们将创建一个3D的NumPy数组,并执行一些数学运算。
import time# NumPy和CPU运行时间start_time = time.time()x_cpu = np.ones((1000, 100, 1000))np_result = np.sqrt(np.sum(x_cpu**2, axis=-1))end_time = time.time()np_time = end_time - start_timesprint("NumPy消耗的时间:", np_time)
NumPy消耗的时间:0.5474584102630615
类似地,我们将创建一个3D的CuPy数组,执行数学运算,并计算其性能。
#CuPy和GPU运行时间start_time = time.time()x_gpu = cp.ones((1000, 100, 1000))cp_result = cp.sqrt(cp.sum(x_gpu**2, axis=-1))end_time = time.time()cp_time = end_time - start_timesprint("\nCuPy消耗的时间:", cp_time)
CuPy消耗的时间:0.001028299331665039
为了计算差异,我们将NumPy的时间除以CuPy的时间。看起来使用CuPy时,性能提升了500倍以上。
diff = np_time/cp_timeprint(f'\nCuPy比NumPy快 {diff: .2f} 倍')
CuPy比NumPy快 532.39 倍
注意:为了获得更好的结果,建议进行一些预热运行,以减小计时波动。
除了速度优势外,CuPy还提供了卓越的多GPU支持,可以实现多个GPU的集体计算能力。
此外,如果您想比较结果,可以查看我的Colab笔记本。
结论
总之,CuPy提供了一种简单的方法来加速在NVIDIA GPU上运行的NumPy代码。只需对代码进行少量修改,将NumPy替换为CuPy,您就可以在数组计算中获得数量级的加速。这种性能提升使您能够处理更大的数据集和模型,从而实现更高级的机器学习和科学计算。
资源
- 文档:CuPy – NumPy & SciPy for GPU — CuPy 12.2.0 documentation
- GitHub:cupy/cupy
- 示例:cupy/examples
- API参考:API参考
****[Abid Ali Awan](https://www.polywork.com/kingabzpro)****(@1abidaliawan)是一名认证的数据科学家,热衷于构建机器学习模型。目前,他专注于内容创作,并在机器学习和数据科学技术方面撰写技术博客。Abid拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为患有心理疾病的学生构建AI产品。






