遇见Retroformer:一种优雅的AI框架,通过学习插件回顾模型来迭代改进大型语言代理
Retroformer是一种优雅的AI框架,用于改进大型语言代理,通过学习插件回顾模型来迭代


一种强大的新趋势出现了,即将大型语言模型(LLMs)增强为能够独立进行活动并最终为目标提供服务的自主语言代理,而不仅仅是对用户问题的简单回答。React、Toolformer、HuggingGPT、生成代理、WebGPT、AutoGPT、BabyAGI和Langchain等都是一些已知的研究,它们通过利用LLMs有效地展示了开发自主决策代理的实用性。这些方法使用LLMs生成基于文本的输出和动作,然后可以用于访问API并在特定环境中执行活动。
然而,目前大多数语言代理的行为并不是经过优化或与环境奖励函数一致的,这是因为LLMs的参数数量非常庞大。反思这种较新的语言代理架构以及其他类似的工作,包括Self-Refine和生成代理,是一种异常,因为它们采用了语言反馈,特别是自我反思,以帮助代理从过去的失败中学习。这些反思代理将环境的二进制或标量奖励转化为声音输入,作为文本摘要,为语言代理的提示提供更多的上下文。
自我反思反馈为代理提供了一个语义信号,使其专注于改进的特定领域。这使得代理可以从过去的失败中学习并避免重复相同的错误,以便在下一次尝试中做得更好。虽然通过自我反思操作实现了迭代改进,但从预训练的冻结LLM生成有用的反思反馈可能会很困难,如图1所示。这是因为LLM必须能够识别代理在特定环境中出现错误的区域,例如信用分配问题,并产生一份带有改进建议的摘要。
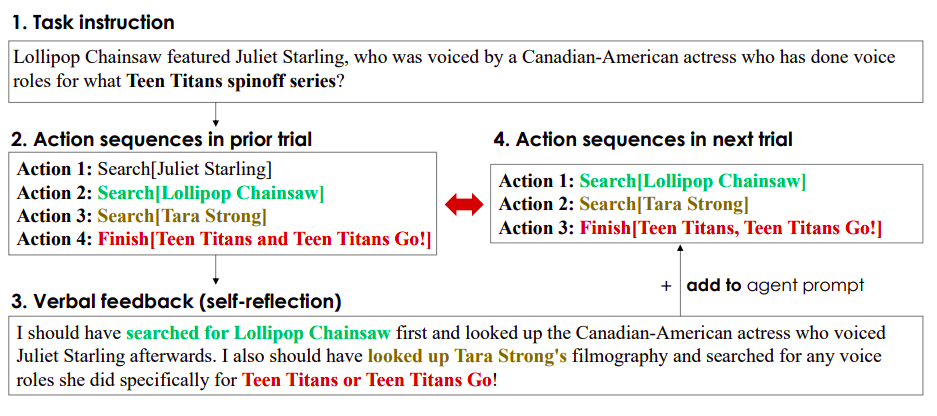
需要对冻结的语言模型进行适当的调整,以便针对特定环境中的任务优化语言强化。此外,目前的语言代理不按照可微分的基于梯度的奖励学习方式进行推理或规划,而是使用了许多当前使用的强化学习方法。Salesforce Research的研究人员介绍了Retroformer,这是一种通过学习插件回顾模型来加强语言代理的道德框架,以解决约束问题。Retroformer通过策略优化,根据环境的输入自动改进语言代理的提示。
具体而言,所提出的代理架构可以通过反思失败的尝试并为代理所采取的行动分配信用来迭代地完善预训练的语言模型。这是通过从多个环境和任务中学习任意奖励信息来实现的。他们在开源模拟和现实世界环境中进行了实验证明,例如HotPotQA,以评估必须反复联系维基百科API以回答问题的网络代理的工具使用技能。HotPotQA包括基于搜索的问答任务。与不使用梯度进行思考和规划的反思相比,Retroformer代理是更快的学习者和更好的决策者。具体而言,在仅四次尝试中,Retroformer代理将基于搜索的问答任务的HotPotQA成功率提高了18%,证明了在具有大量状态-动作空间的环境中,基于梯度的规划和推理对于工具使用的价值。
总结来说,以下是他们所做出的贡献:
• 研究开发了Retroformer,通过根据上下文输入反复改进大型语言代理所提供的提示,提高学习速度和任务完成能力。所提出的方法专注于增强语言代理架构中的回顾模型,而无需访问Actor LLM参数或传播梯度。
• 所提出的方法允许从各种奖励信号中学习不同的任务和环境。由于其通用性,Retroformer是许多云端LLM(如GPT或Bard)的可适应插件模块。






