Platypus:更好的大型语言模型的数据集整理和适配器
Platypus Dataset curation and adapter for better large-scale language models.
在您的目标任务上实现低成本的最先进技术
Meta的Llama 2于一个月前发布,许多人正在对其进行微调以适应特定任务。在同一趋势下,波士顿大学提出了Platypus(Lee等人,2023年),即使用适配器和策划数据集对Llama 2进行微调。
截至8月16日,Platypus在OpenLLM排行榜上排名第一。
本研究提出的方法并不是真正的新方法。它依赖于LoRa适配器和精心策划的数据集。然而,该方法仍然令人印象深刻,因为它展示了通过使用经过策划的领域内数据集,可以实现给定任务的新的最先进性能,而几乎是免费的,这要归功于专门的适配器。
在本文中,我将回顾并解释Platypus。我还将展示如何使用消费者硬件实现类似的结果。
- Artisse创始人兼首席执行官吴威廉 – 访谈系列
- 使用LangChain和GPT-4进行多语言FEMA灾害机器人研究
- 简化Transformer 使用你理解的词语进行最先进的自然语言处理——第1部分——简介
注意:当他们在这个项目上工作时,QLoRa尚未发布(正如作者在论文中提到的)。他们论文中报告的计算成本可以通过QLoRa显著降低。我将在本文的最后向您展示如何做到这一点。
策划您的数据集以进行更好的LLM微调
这项工作的主要目标是为特定领域/任务创建准确的LLM。
作者的首要任务是策划现有数据集以适应其目标领域,即STEM。他们假设通过过滤数据集以删除与目标领域不相关的训练样例以及几乎重复的样例,可以提高模型的准确性。这也会显著减小用于微调的训练数据的大小,从而使微调更加高效。
Platypus发布为一系列聊天模型。作者还收集和筛选了一系列开源指令数据集。
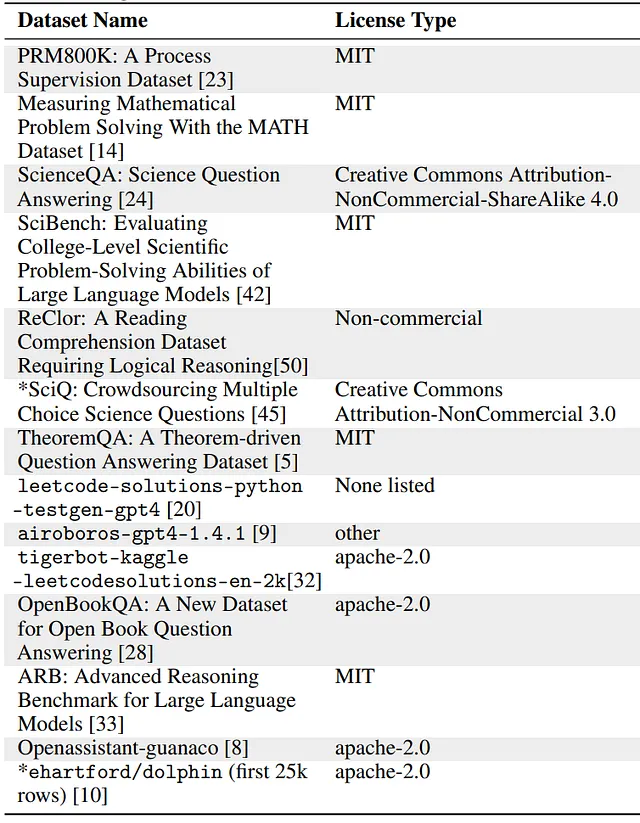
为了去重和促进训练样例的多样性,他们进行了以下步骤:






