一个学习ChatGPT底层基础知识的优秀资源
An excellent resource for learning the fundamentals of ChatGPT.

OpenAI,ChatGPT,GPT系列以及大型语言模型(LLMs)——如果您与AI专业或技术人员有一定的关联,那么您在商业交流中几乎肯定会听到这些词语。
而且这种炒作是真实的。我们不能再将其称为泡沫了。毕竟,这次炒作不辜负其承诺。
谁会想到机器能够理解并以类似人类智能的方式回复,并且几乎能够完成以前被认为是人类专长的所有任务,包括对音乐的创造性应用、写诗甚至编写应用程序?
LLMs在我们生活中的无处不在的普及使我们都对这种强大技术的底层原理产生了好奇。
因此,如果您因算法的复杂性和人工智能领域的复杂性而退缩,我强烈推荐您学习关于“ChatGPT正在做什么……以及为什么它有效”的这一资源。
是的,这是Wolfram的一篇文章的标题。
为什么我推荐这个?因为在学习Transformer、LLMs甚至生成式人工智能之前,了解机器学习的绝对基础知识以及深度神经网络与人脑的关系非常重要。
这看起来像一本迷你书,它本身就是一种文学作品,但您可以慢慢阅读这篇资源的长度。
在本文中,我将分享如何开始阅读以便更容易地理解其中的概念。
理解“模型”至关重要
它的重点是关注“大型语言模型”中的“模型”部分,通过每层楼球到达地面所需的时间的示例进行说明。
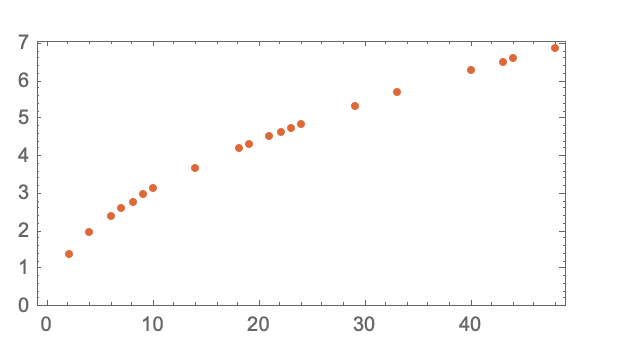
有两种方法可以实现这一点——从每层楼重复此练习或构建一个可以计算它的模型。
在这个例子中,存在一种使计算更容易的数学公式,但是如何使用“模型”来估计这种现象呢?
最好的方法是为估计所需的变量(在这种情况下是时间)拟合一条直线。
对这一部分进行更深入的阅读将解释“从不缺少模型”的概念,这将无缝地引导您进入各种深度学习概念。
深度学习的核心
您将了解到模型是一个复杂的函数,它以某些变量作为输入,并产生一个输出,例如在数字识别任务中的数字。
文章从数字识别到典型的猫狗分类器,透彻地解释了每一层选择的特征,从猫的轮廓开始。值得注意的是,神经网络的前几层选择出图像的某些方面,例如物体的边缘。

关键术语
除了解释多层的作用外,还解释了深度学习算法的多个方面,例如:
神经网络的架构
文章称它是艺术和科学的结合——“但主要是通过反复试验发现的,不断增加的想法和技巧逐渐积累了关于如何使用神经网络的丰富知识”。
Epochs
Epochs是一种有效的方法,可以提醒模型记住特定的示例,从而使其“记住该示例”
由于重复相同的示例多次并不足够,因此向神经网络展示不同的示例变体非常重要。
权重(参数)
你一定听说过其中一个语言模型具有惊人的1750亿个参数。这表明模型的结构如何根据调整旋钮的方式而变化。
实际上,参数就是用来拟合数据的“可以调整的旋钮”。本文强调了神经网络的实际学习过程就是找到合适的权重——“最终,这一切都是关于确定哪些权重能够最好地捕捉到已给出的训练示例”。
泛化能力
神经网络可以“以合理的方式在展示的示例之间进行插值学习”。
这种泛化能力通过从多个输入-输出示例中进行学习来帮助预测未见过的记录。
损失函数
但是我们如何知道什么是合理的呢?这是通过输出值与期望值之间的距离来定义的,而这些值被封装在损失函数中。
它给出了“我们得到的值与真实值之间的距离”。为了减小这个距离,权重会被迭代调整,但必须有一种方式以最短的路径系统地减小权重。
梯度下降
在权重空间中找到下降的最陡路径被称为梯度下降。
它的核心在于通过在权重空间中导航来找到最佳代表真实情况的正确权重。
反向传播
继续阅读关于反向传播的概念,它通过将损失函数向后传播来逐渐找到最小化相关损失的权重。
超参数
除了权重(即参数)之外,还有超参数,包括不同选择的损失函数、损失最小化,甚至是选择“批次”示例的大小。
用于复杂问题的神经网络
广泛讨论了使用神经网络解决复杂问题的方法。然而,直到这篇文章,人们才能清楚地解释这种假设背后的逻辑,即在高维空间中的多个权重变量使得能够采取各种可能的方向来达到最小值。
现在,将此与较少的变量进行比较,这意味着可能会陷入局部最小值而无法脱身。
结论
通过阅读本文,我们已经涵盖了很多内容,从理解模型和人脑的工作原理到将其应用于神经网络、它们的设计和相关术语。
请继续关注接下来关于如何利用这些知识来理解chatgpt工作原理的后续文章。 Vidhi Chugh是一位AI战略家和数字化转型领导者,致力于在产品、科学和工程的交叉领域构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作家和国际演讲者。她的使命是使机器学习民主化,并为每个人打破术语壁垒,参与到这个变革中来。






