LLMOps:使用Hamilton进行生产推导工程模式
LLMOps Production inference engineering mode using Hamilton
使用 Hamilton 迭代提示的生产级方法概述

您发送给大型语言模型(LLM)的内容非常重要。微小的变化和更改可能会对输出产生重大影响,因此随着产品的发展,需要改进提示的需求也会增加。LLM也在不断发展和发布,因此随着LLM的变化,您的提示也需要改变。因此,建立一个迭代模式来操作化您的提示是很重要的,以便您和您的团队可以高效地移动,但也要确保尽可能减少生产问题,甚至避免它们。在本文中,我们将通过 Hamilton(一个开源的微服务编排框架)指导您如何管理提示的最佳实践,类比于 MLOps 模式,并讨论其中的权衡。本文的高层次结论即使您不使用 Hamilton,仍然适用。
开始之前的几件事:
- 我是 Hamilton 的共同创造者之一。
- 对 Hamilton 不熟悉吗?请滚动到底部查看更多链接。
- 如果您正在寻找讨论“上下文管理”的文章,本文不是那篇文章。但它是一篇将帮助您进行迭代和创建那个生产级“提示上下文管理”迭代故事的文章。
- 我们将互换使用提示和提示模板。
- 我们将假设这些提示是在“在线”网络服务环境中使用的。
- 我们将使用 Hamilton 的 PDF 摘要示例来展示我们的模式。
- 我们的可信度如何?我们一直在自助数据/MLOps工具领域工作,最著名的是为 Stitch Fix 的100多位数据科学家提供的工具。因此,我们见证了很多故障和方法随着时间的推移而发展。
提示对于 LLMs 的作用类似于超参数对于 ML 模型的作用
要点:提示 + LLM API 类似于超参数 + 机器学习模型。
就“Ops”实践而言,LLMOps 还处于起步阶段。MLOps 稍微老一些,但与 DevOps 实践的普及程度相比,它们都没有得到广泛采用。
DevOps 实践主要关注如何将代码部署到生产环境中,而 MLOps 实践则关注如何将代码和数据工件(例如统计模型)部署到生产环境中。那么 LLMOps 呢?个人认为它更接近 MLOps,因为您有:
- 您的 LLM 工作流仅仅是代码。
- LLM API 是一个数据工件,可以使用提示进行“调整”,类似于机器学习(ML)模型和其超参数。
因此,您很可能关心将 LLM API + 提示紧密地进行版本控制,以便进行良好的生产实践。例如,在 MLOps 实践中,您需要确保在更改超参数时,验证您的 ML 模型仍然正确运行。
如何思考操作化提示?
明确一点,需要控制的是 LLM 和提示两部分。与 MLOps 类似,当代码或模型工件发生变化时,您希望能够确定是哪个发生了变化。对于 LLMOps,我们也希望进行同样的区分,将 LLM 工作流与 LLM API + 提示分开。重要的是,我们应该将 LLM(自托管或 API)视为基本静态的,因为我们较少更新(甚至控制)其内部。因此,改变 LLM API + 提示部分实际上就像创建一个新的模型工件。
处理提示的两种主要方式:
- 将提示作为动态运行时变量。使用的模板不是部署时静态的。
- 将提示作为代码。提示模板是静态/给定部署时确定的。
主要区别在于您需要管理的移动部件的数量以确保出色的生产过程。下面,我们将详细介绍如何在这两种方法的背景下使用Hamilton。
将提示作为动态运行时变量
动态传递/加载提示
提示只是字符串。由于在大多数语言中,字符串是一种原始类型,这意味着它们非常容易传递。思路是将您的代码抽象化,以便在运行时传递所需的提示。更具体地说,每当有“更新”的提示时,您会“加载/重新加载”提示模板。
在这里,MLOps的类比是当有新模型可用时自动重新加载ML模型工件(例如pkl文件)。

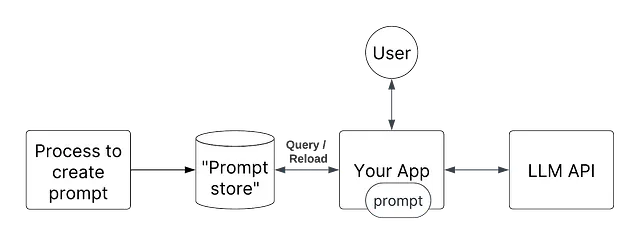
这样做的好处是,您可以非常快速地推出新的提示,因为您不需要重新部署应用程序!
这种迭代速度的缺点是增加的操作负担:
- 对于监视您的应用程序的人来说,更改发生的时间以及它是否在系统中传播都不清楚。例如,您刚刚推送了一个新的提示,LLM现在返回更多的令牌请求,导致延迟急剧上升;除非您有一个很好的更改日志文化,否则监视人员可能会感到困惑。
- 回滚语义涉及要了解另一个系统。您不能只回滚以前的部署来修复问题。
- 您将需要良好的监控来了解运行了什么以及何时运行;例如,当客户服务给您提供一个要调查的票证时,您如何知道使用了什么提示?
- 您需要管理和监控用于管理和存储提示的任何系统。这将是您需要在提供代码之外维护的额外系统。
- 您需要管理两个流程,一个用于更新和推送服务,另一个用于更新和推送提示。同步这些更改将由您负责。例如,您需要对服务进行代码更改以处理新的提示。您需要协调更改两个系统以使其正常工作,这是额外的操作负担。
在Hamilton中的工作方式
如果删除summarize_text_from_summaries_prompt和summarize_chunk_of_text_prompt函数定义,我们的PDF摘要器流程将如下所示:
要操作事物,您将希望在请求时注入提示:
from hamilton import base, driver
import summarization_shortend
# 创建驱动
dr = (
driver.Builder()
.with_modules(summarization_sortened)
.build())
# 从某处获取提示
summarize_chunk_of_text_prompt = """某个文本块的提示"""
summarize_text_from_summaries_prompt = """某个提示 {summarized_chunks} ... {user_query}"""
# 执行,并传入提示
result = dr.execute(
["summarized_text"],
inputs={
"summarize_chunk_of_text_prompt": summarize_chunk_of_text_prompt,
...
})
或者您可以更改代码以动态加载提示,即在Hamilton数据流的一部分中添加从外部系统检索提示的函数。在每次调用时,它们将查询要使用的提示(当然,您可以为了性能而将其缓存):
# prompt_template_loaders.py
def summarize_chunk_of_text_prompt(db_client: Client, other_args: str) -> str:
# 这里是伪代码,但你可以理解的:
_prompt = db_client.query("从数据库中获取最新提示X", other_args)
return _prompt
def summarize_text_from_summaries_prompt(db_client: Client, another_arg: str) -> str:
# 这里是伪代码,但你可以理解的:
_prompt = db_client.query("从数据库中获取最新提示Y", another_arg)
return _prompt
驱动代码:
from hamilton import base, driver
import prompt_template_loaders # <-- 加载此模块以提供提示输入
import summarization_shortend
# 创建驱动
dr = (
driver.Builder()
.with_modules(
prompt_template_loaders, # <-- Hamilton将调用上述函数
summarization_sortened,
)
.build())
# 执行,并传入提示
result = dr.execute(
["summarized_text"],
inputs={
# 在这个版本中不需要传递提示
})
如何记录使用的提示并监控流程?
这里我们概述了几种监控操作的方法。
- 记录执行结果。运行Hamilton,然后将信息发送到您想要的地方。
result = dr.execute(
["summarized_text",
"summarize_chunk_of_text_prompt",
... # 还有其他要提取的内容
"summarize_text_from_summaries_prompt"],
inputs={
# 在这个版本中不需要传递提示
})
my_log_system(result) # 将所需的内容发送到您自己拥有的系统以供安全保存
注意。在上面的代码中,Hamilton允许您通过名称请求任何中间输出,只需请求“函数”(即图中的节点)。如果我们真的想获取整个数据流的所有中间输出,我们可以做到并将其记录在想要的任何位置!
- 在Hamilton函数内部使用日志记录器(要了解此方法的威力,请参阅我关于结构化日志的旧演讲):
import logging
logger = logging.getLogger(__name__)
def summarize_text_from_summaries_prompt(db_client: Client, another_arg: str) -> str:
# 这里是伪代码,但你可以理解的:
_prompt = db_client.query("从数据库中获取最新提示Y", another_arg)
logger.info(f"所使用的提示是 [{_prompt}]")
return _prompt
- 扩展Hamilton以发出此信息。您可以使用Hamilton从执行的函数(即节点)中捕获信息,而无需在函数体中插入日志语句。这样可以提高可重用性,因为您可以在驱动程序级别上在开发和生产环境设置之间切换日志记录。请参阅GraphAdapters,或编写自己的Python装饰器来包装函数以进行监控。
在上述任何代码中,您都可以轻松添加第三方工具以帮助跟踪和监视代码以及外部API调用。
将提示作为代码
将提示作为静态字符串
由于提示只是字符串,因此它们非常适合与源代码一起存储。这个想法是在您的代码中存储尽可能多的提示版本,以便在运行时,可用的提示集是固定和确定的。
这里的MLOps类比是,不再动态重新加载模型,而是将ML模型嵌入到容器中/硬编码引用。一旦部署,您的应用程序就拥有了一切所需的内容。部署是不可变的;一旦启动,就不会发生任何变化。这使得调试和确定发生了什么变得更加简单。

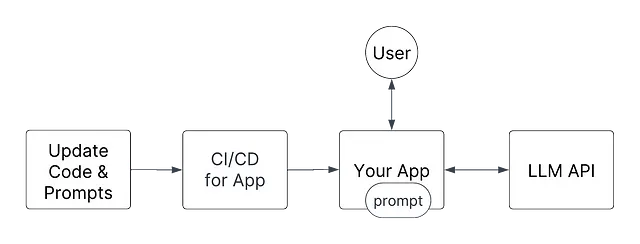
这种方法有许多操作上的好处:
- 每当推送新提示时,它会强制进行新的部署。如果新提示存在问题,回滚语义会很清晰。
- 您可以同时为源代码和提示提交拉取请求(PR)。这样更容易审查更改以及这些提示将触及/与之交互的下游依赖项。
- 您可以向CI/CD系统添加检查,以确保错误的提示不会进入生产环境。
- 调试问题更简单。您只需拉取已创建的(Docker)容器,就能快速而轻松地完全复制任何客户问题。
- 无需维护或管理其他“提示系统”。简化操作。
- 不排除添加额外的监控和可见性。
与Hamilton一起使用的工作原理
提示将被编码为数据流/有向无环图(DAG)中的函数:
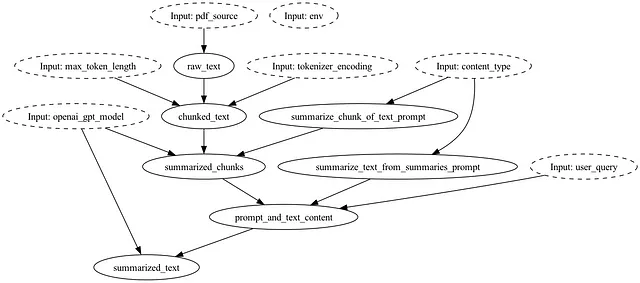
将此代码与git配对,您就拥有了整个数据流(即“链”的轻量级版本控制系统),因此您始终可以确定给定git提交SHA时的世界状态。如果您希望管理和随时访问多个提示,并且在任何给定时间点上,Hamilton都有两个强大的抽象来使您能够这样做:@config.when和Python模块。这允许您存储并保留所有旧的提示版本,并通过代码指定要使用的版本。
@config.when(文档)
Hamilton具有修饰符的概念,它们只是函数上的注释。 @config.when修饰符允许为数据流中的函数(即“节点”)指定替代实现。在这种情况下,我们指定了替代提示。
from hamilton.function_modifiers import [email protected](version="v1")def summarize_chunk_of_text_prompt__v1() -> str: """用于摘要文本块的V1提示。""" return f"Summarize this text. Extract any key points with reasoning.\n\nContent:"@config.when(version="v2")def summarize_chunk_of_text_prompt__v2(content_type: str = "an academic paper") -> str: """用于摘要文本块的V2提示。""" return f"Summarize this text from {content_type}. Extract the key points with reasoning. \n\nContent:"您可以继续添加使用@config.when注释的函数,允许您使用传递给Hamilton的配置在它们之间进行切换。在实例化Driver时,它将使用与配置值关联的提示实现构建数据流。
从hamilton导入基本,驱动程序import summarization# 创建驱动程序dr = ( driver.Builder() .with_modules(summarization) .with_config({"version": "v1"}) # 选择V1。 使用“v2”来使用V2. .build())模块切换
除了使用@config.when,您还可以将不同的提示实现放入不同的Python模块中。然后,在Driver构建时,传递正确的模块用于您想要使用的上下文。
所以这里我们有一个模块存放着我们的V1提示:
# prompts_v1.pydef summarize_chunk_of_text_prompt() -> str: """用于总结文本块的V1提示。""" return f"总结这段文本。提取任何带理由的关键点。\n\n内容:"这里我们有一个模块存放着V2(看看它们有什么不同):
# prompts_v2.pydef summarize_chunk_of_text_prompt(content_type: str = "an academic paper") -> str: """用于总结文本块的V2提示。""" return f"从{content_type}总结这段文本。提取带理由的关键点。\n\n内容:"在下面的驱动程序代码中,我们基于某些上下文选择使用正确的模块。
# run.pyfrom hamilton import driverimport summarizationimport prompts_v1import prompts_v2# 创建驱动程序 - 传入我们想要的正确模块dr = ( driver.Builder() .with_modules( prompts_v1, # 或 prompts_v2 summarization, ) .build())使用模块的方法使我们能够封装和版本化一整套提示。如果您想要回溯(通过git),或查看受保护的提示版本,您只需要导航到正确的提交,然后查看正确的模块。
如何记录使用的提示和监控流程?
假设您正在使用git跟踪您的代码,您就不需要记录使用了哪些提示。相反,您只需要知道已部署的git提交SHA,就可以同时跟踪代码和提示的版本。
要监视流程,就像上面的方法一样,您可以利用可用的相同监控钩子,并且我不会在此重复,但它们是:
- 请求任何中间输出并在Hamilton之外自己记录。
- 从函数内部记录它们,或者构建一个Python装饰器/GraphAdapter来在框架级别执行记录。
- 集成第三方工具以监视您的代码和LLM API调用。
- 或者以上所有!
如何进行提示的A/B测试?
对于任何机器学习项目,衡量变化的业务影响非常重要。同样,对于LLM + 提示,测试和衡量变化对重要业务指标的影响也很重要。在MLOps世界中,您会对ML模型进行A/B测试,通过在它们之间划分流量来评估它们的业务价值。为了确保A/B测试所需的随机性,您在运行时不会知道要使用哪个模型,直到抛硬币为止。然而,为了使这些模型可用,它们都必须遵循一个合格的过程。因此,对于提示,我们应该以类似的方式思考。
上述两种提示工程模式并不妨碍您进行提示的A/B测试,但这意味着您需要管理一个过程,以同时启用您正在并行测试的任意数量的提示模板。如果您还要调整代码路径,将它们放在代码中将更容易辨别和调试正在进行的操作,您可以利用@config.when装饰器/Python模块切换来实现这个目的。与动态加载/传递它们然后必须进行精确映射的情况不同,您不需要完全依赖于日志/监控/可观察性堆栈来告诉您使用了哪个提示。
请注意,如果您需要更改多个提示进行A/B测试,这将变得更加困难,因为您的流程中有多个提示。例如,您的工作流程中有两个提示,并且您正在更改LLMs,您将希望对整体更改进行A/B测试,而不是单独对每个提示进行测试。我们的建议是将提示放入代码中,您的运营生活将更简单,因为您将知道两个提示属于哪些代码路径,而无需进行任何精确映射。
概要
在本篇文章中,我们介绍了使用Hamilton在生产环境中管理提示的两种模式。第一种方法将提示作为动态运行时变量处理,而第二种方法将提示作为代码处理以适用于生产环境。如果您重视减少运营负担,我们建议将提示编码为代码,因为这样操作起来更简单,除非您真的很在意更改它们的速度。
回顾一下:
- 将提示作为动态运行时变量。使用外部系统将提示传递给您的Hamilton数据流,或使用Hamilton从数据库中提取它们。对于调试和监控,能够确定给定调用使用了哪个提示非常重要。您可以集成开源工具,或使用类似DAGWorks平台的工具,以确保您知道任何代码调用使用了哪个提示。
- 将提示作为代码。将提示编码为代码可以与git轻松进行版本控制。可以通过拉取请求和CI/CD检查进行更改管理。它与Hamilton的功能(如
@config.when和驱动程序级别的模块切换)很好地配合使用,因为它清楚地确定了使用的提示版本。这种方法增强了您可能用于监视或跟踪的任何工具的使用,例如DAGWorks平台,因为部署的提示是不可变的。
我们希望听到您的声音!
如果您对此感到兴奋,或者有强烈的意见,请留下评论,或者来我们的Slack频道交流!以下是一些链接,您可以表扬/抱怨/聊天:
- 📣加入我们在Slack上的社区-我们非常乐意帮助您解答您可能遇到的问题或帮助您入门。
- ⭐️给我们在GitHub上点赞。
- 📝如果发现问题,请给我们留下一个问题。
- 📚阅读我们的文档。
- ⌨️在浏览器中交互式地了解Hamilton。
您可能感兴趣的其他Hamilton链接/文章:
- tryhamilton.dev-在浏览器中进行交互式教程!
- Hamilton + Lineage in 10 minutes
- 如何在5分钟内使用Hamilton和Pandas
- 如何在5分钟内使用Hamilton和Ray
- 如何在Notebook环境中使用Hamilton
- 有关Hamilton的背景故事和介绍
- 使用Hamilton创建数据流的好处(Hamilton的用户在Hamilton上发布的帖子!)






