大型语言模型令编译器优化的元AI研究人员感到惊讶!
Large-scale language models surprise compiler optimization researchers!


“我们以为这篇论文会讲述LLM显而易见的缺陷,以激发未来克服这些缺陷的新思路。但是我们完全被惊讶地发现,训练充分的LLM不仅可以预测对输入代码应用的最佳优化方法,而且还可以直接执行这些优化,而不需要编译器的干预!” - Meta AI的研究人员
Meta AI的研究人员试图让大型语言模型(LLMs)进行与常规编译器(如LLVM)相同类型的代码优化。LLVM的优化器非常复杂,有数千条规则和算法,使用C++编程语言编写了超过100万行代码。
他们认为LLMs无法处理这种复杂性,因为它们通常用于翻译语言和生成代码等任务。编译器优化涉及许多不同类型的思考、数学和使用复杂技术,他们认为LLMs在这方面表现不佳。但是在方法论之后,结果却是令人惊讶的。
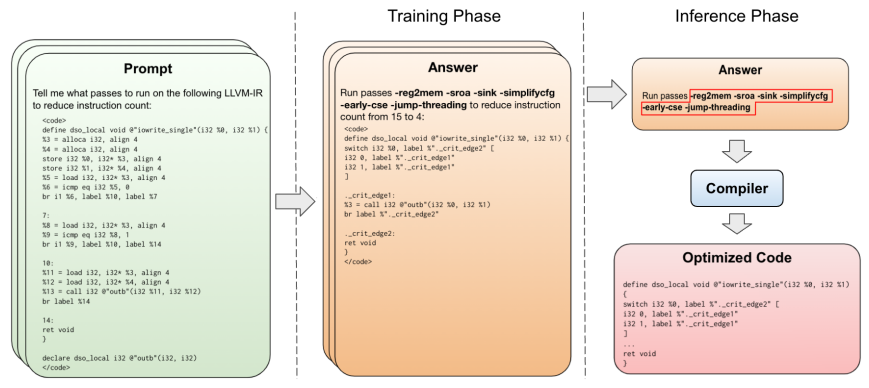
上述图片展示了方法论的概述,显示了模型在训练和推理过程中的输入(提示)和输出(答案)。提示包含未经优化的代码。答案包含优化操作列表、指令计数和经过优化的代码。在推理过程中,只生成优化操作列表,然后将其输入编译器,以确保优化后的代码正确。
- 图像匿名化如何影响计算机视觉性能?探索传统与现实匿名化技术
- Deci AI推出DeciDiffusion 1.0:一个8.2亿参数的文本到图像潜在扩散模型,速度比稳定扩散快3倍
- 大型语言模型在长篇问答中的表现如何?Salesforce研究人员对LLM的鲁棒性和能力进行了深入探究
他们的方法很直接,首先使用来自LLaMa 2 [25]的70亿参数的大型语言模型(LLM)架构,并从头开始进行初始化。然后,该模型在庞大的数据集上进行训练,该数据集包含数百万个LLVM汇编示例,每个示例都与通过搜索过程确定的最佳编译器选项以及应用这些优化后的汇编代码配对。通过仅使用这些示例,模型能够以极高的精度优化代码。
他们的工作的显著贡献在于首次将LLMs应用于代码优化任务。他们创建了专门针对编译器优化的LLMs,证明这些模型在单个编译中相比基于搜索的方法实现了3.0%的代码大小减少。相比之下,目前最先进的机器学习方法导致回归,并且需要数千次编译。研究人员还提供了补充实验和代码示例,以更全面地了解LLMs在代码推理中的潜力和局限性。总体而言,他们发现LLMs在这个领域的功效非常显著,并且相信他们的发现会引起更广泛的兴趣。