探索大型语言模型-第一部分
Exploring Large Language Models - Part 1
机器学习的圣杯 — 无监督学习,理解的出现,理解LLM训练
本文主要用于自学。因此,它广泛而深入。根据您的兴趣,可以随意跳过某些部分或寻找您感兴趣的领域。
以下是在尝试调整LLM时令我感到好奇或遇到的一些问题。本文试图回答这些问题,并与其他好奇者分享这些信息。
由于LLM基于具有损失函数的神经网络,难道LLM的所有训练不都是监督训练吗?为什么通常称之为无监督训练?您可以用一句话训练一个LLM,以说明LLM训练的实际工作原理是如何的吗?什么是屏蔽语言模型和因果语言模型?您能用一张图片解释Transformer架构背后的直觉吗?在LLM中,无监督训练到底是什么意思?ChatGPT的主要架构师Ilya Suverskar为什么认为无监督训练是机器学习的圣杯?什么是LLM的出现/理解?
LLM的用例有哪些?为什么LLM最适合作为生产力助手?信息检索的向量数据库/嵌入模式是什么?LLM除了文本任务以外还能用于其他事情吗?什么是因果推理?LLM存在什么问题?像Yan LeCun这样的大脑为什么认为当前的LLM是无望的?LLM能解释吗?如果不能,它们该如何有效地使用?
为什么需要微调/重新训练LLM?为什么训练LLM很困难?量化和LoRA如何帮助训练大型LLM?量化和LoRA如何工作?微调预训练LLM的有效方法是什么?什么是指导微调?什么是自我指导?如何为指导微调生成高质量的训练数据集?
尚未回答的问题:您能展示一下如何层次化地构建具有因果推理的复杂自动化系统,其中包含具有不同能力的LLM吗?为什么我们要从LLM或神经网络中创造类似于人类智能的能力?为什么这似乎与在固定翼飞机发明之前创造类似鸟类飞行的情况如此相似?
由于本文内容较长,我将其分为三个部分,以提高可读性。
第一部分将讨论LLM训练的演变。意图是为我们理解模型尺寸超过阈值并使用大量数据训练时开始发生的魔法,或更准确地说是出现,奠定背景。深入探讨部分将更详细和深入地介绍这些概念,不过大多数程序员也能轻松理解。
第二部分将简要讨论LLM的常见用例,个人助手和通过信息检索模式(LLM增强的向量空间搜索)使用自定义数据的聊天机器人。我们还将探讨心理模型和模型的自然语言理解能力最终如何成为其更强大用例的种子。在这个背景下,我们将通过对比监督训练的优势和LLM模型的弱点 —— 解释能力或确定事实与妄想之间的困难——来探讨LLM模型的一个主要局限。我们将探讨这些系统如何通过一系列控制实现在计算机系统中的非常有效的使用,例如我们日常使用ChatGPT,并如何将其扩展到其他用例。
第三部分将讨论与在自定义领域训练LLM相关的一些概念。我们在这里关注领域理解的部分,以及它比简单的向量空间信息检索模式更强大的地方。这在玩具示例中很容易,但在实际数据中并不容易。我们将探讨量化技术如何将非常大的LLM开放给世界,以及如何与减少训练参数的概念相结合,使LLM微调民主化。我们将探讨有效微调的主要技术——指导微调,以及如何解决指导微调的最大实际问题 —— 缺乏具备我们到目前为止所学概念的高质量指导训练数据集的问题。
后续章节将讨论利用LLM的理解部分以及利用这些强大系统的控制层次结构来增强人工智能/机器学习系统的概念。
介绍
大型语言模型(LLMs)给我们带来了两个明显的能力 – 一种与模型进行自然语言交互的界面,以及在模型中非常高效地存储的大量知识-整个互联网的文本数据。模型越大,它们在这两个能力方面表现得越好。
还有另一个能力并不那么明显,但可能是最强大的。它在第一种能力中是隐含的,被技术上称为NLU,即自然语言理解。要理解某个事物,你需要一个模型。对于人类来说,是一种心智模型。要理解语言,你需要一个语言句法和语义的模型。要理解用户的问题并能够有效回答,模型需要一个内部世界模型。在这个领域的思想领袖之间存在争议,关于这些LLMs是否学习了一些内部世界模型,或者我们是否认为它存在。
然而,它们的自然语言理解能力非常好,并且它们的内部世界模型具有足够的信息,使得它们通过了图灵测试,正如我们所设想的(https://www.nature.com/articles/d41586-023-02361-7),并且还通过了现代人工智能最著名的批评家Judea Pearl提出的基于因果推理的迷你图灵测试。我们稍后会回到这个话题。
从某种角度看,每个人都知道智能是什么;从另一种角度看,没有人知道。Robert J. Sternberg,来源
然而,这并不意味着它们在真正意义上是智能的,但我们可以更安全地说,它们在理解自然语言方面是智能的。这是区分这些模型的关键属性。
LLMs最初是愚蠢的自动机,但在训练的某个地方,它们变得足够聪明,可以将它们的训练推广到它们没有明确训练过的任务上。这就是我们可以更自由地称之为“理解”的东西。正如我之前提到的,这是一个备受争议的话题,我们的目标不是深入讨论这个争议,而是尝试学习。
LLM训练和理解的出现
我们可以通过追踪一些著名的AI/ML系统的历史来以更有趣的方式理解这个话题。
规则引擎/树搜索
我们可以从IBM DeepBlue国际象棋超级计算机开始。通过利用超级计算机的强大性能和定制芯片,它在1997年击败了国际象棋大师Gary Kasparov。然而,当时并没有涉及到人工智能或神经网络,而是树搜索。你可以抽象一下,说它是一个基于规则的引擎。训练数据是手工编码的领域专业知识,蒸馏成一组规则。算法根据其世界的当前状态,从庞大但可计算的结果集中优化选择下一步的动作。然而,很明显,无法为更广泛的领域进行这种基于规则的编程。
监督训练
十年后的2011年,IBM Watson –专为问题回答而设计,专门针对Trivial QA进行训练,并在Jeopardy比赛中获胜。围绕这个系统曾经有过很大的炒作,认为它是下一个能够革命一切的知识系统。该系统的主要训练方式似乎是监督训练。也就是说,训练数据具有标签,系统在这些数据上进行训练以选择正确的答案,或者在这种情况下,选择正确的问题。
监督学习效果很好。这是当今几乎所有生产中使用的机器学习的基石。只要有足够的标记数据,AI/ML系统就能够学习逼近任何复杂的多变量函数。它们是优秀的通用函数逼近器。
“所有深度学习的令人印象深刻的成就都只是曲线拟合…”。图灵奖得主Judea Pearl对AI/ML系统的著名批评
监督学习的问题在于,为训练大型模型标记大量的数据集需要大量昂贵且耗时的人力努力。
最好的例子是最大的标记数据集之一以及它的影响,即Imagnet。作为ImageNet项目的一部分,收集了大量带标签的图像数据,这帮助AlexNet在2012年(Ilya Sutskever, Alex Krizhevsky和Geoffrey Hinton)引入并革新了计算机视觉,尽管早在1998年,Yann LeCun和其他人已经引入了基于LeNet的卷积神经网络用于手写识别。
请注意,伊利亚·萨茨克弗(Ilya Sutskever)也是OpenAI的创始人之一,并在后来的GPT模型训练中发挥了重要作用。
回到故事本身。多年来,围绕IBM沃森的炒作逐渐平息,因为系统的局限性变得显而易见。《纽约时报》的一篇文章揭示了一些挑战的内幕,解释了为什么它无法像IBM所希望的那样很好地推广到其他领域,其中主要原因是缺乏正确标记的数据。
强化学习
2016年,Google DeepMind AlphaGo通过击败冠军围棋选手而广受欢迎。这个游戏比国际象棋的领域/策略要广泛得多(不可能使用规则引擎/树搜索类型的算法)。关键在于强化学习(RL)。
在这里,训练可以抽象为进行随机移动,如果移动使你更接近胜利(通过一些损失计算),则进行更多此类移动,反之亦然。然后,他们创建了代理并使代理彼此对抗,从而玩了可能相当于数千年的游戏,并且在游戏中越来越出色。
比围棋更复杂的游戏是Dota,在2019年,一个当时规模较小的公司叫做OpenAI击败了当前的Dota 2冠军
以下是与此事件相关的有趣片段。最后一个词“规模”是可能暗示了他们如何将这个概念用于他们将来在GPT模型中的工作的有趣部分。
我们启动了OpenAI Five,以解决现有深度强化学习无法解决的问题…我们原本期望需要诸如分层强化学习之类的复杂算法思想,但我们对我们发现的东西感到惊讶:我们需要解决这个问题的根本改进是规模。
DeepDive – 对于像游戏这样有非常有限或受控状态空间的领域,要实现非常困难。例如,在自动驾驶汽车中,先前步骤中的任何小的状态变化都可能对后来产生积极或消极的影响。这归结为实施能够存储和临时工作的损失函数。(https://stanford.edu/~ashlearn/RLForFinanceBook/book.pdf,为什么强化学习需要反向传播的近似值https://stats.stackexchange.com/a/340657/191675)
因此,我们介绍了监督学习(到目前为止,人工智能/机器学习算法的基础)和强化学习-主要是在视频游戏和类似的领域中。
无监督学习-所有学习的圣杯?
在OpenAI…希望是,如果你有一个可以预测下一个词的神经网络,它将解决无监督学习。因此,在GPT之前,无监督学习被认为是机器学习的圣杯….
但是我们的神经网络无法完成这个任务。我们正在使用递归神经网络。当Transformer出现时,就在论文发表的第二天,对我来说,对我们来说,它很明显,Transformer解决了递归神经网络的局限性,解决了学习长期依赖性的问题….
这就是最终导致GPT-3和今天我们所处的地方的原因。-伊利亚·萨茨克弗采访
在我们进一步探讨他所说的“圣杯”之前,让我们回到过去,澄清背景并探索工程师在提到无监督学习时通常指的是什么,以及这里所指的是什么。他在这里的意思简而言之,是一种更高层次的学习抽象,而不是实际的实现。目前尚不清楚如何训练一个网络来预测下一个令牌,使其能够像LLMs一样具有广泛的泛化能力;也就是说,它们以无监督的方式进行泛化学习,尽管训练本身是有监督的下一个令牌预测。
无监督学习的常见观点
当我们通常在机器学习中提到无监督学习时,涉及到一些与聚类相关的算法,例如k-means聚类,降维,主成分分析或时间序列拟合。这些都是基于数学或矩阵特性的。它们都相当复杂,但如果你擅长数学,或者你付出足够的努力,你可以清楚地理解它们。
在深度学习的情况下,较低层次的例子是自动编码器。自动编码器在LLMs的背景下更有趣,因为它们学习内部压缩表示的结构。在自动编码器中,目标与输入相同。也就是说,给定复杂数据(例如高度详细的图像),训练一个浅层网络以产生类似的输出。为此,网络需要学习数据中的一些模式,以便足够压缩数据。更多信息请参见http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
在本文中,我们将重点放在无监督学习的LLMs上,而不是上述经典的机器学习或深度学习用例。
DeepDive:所有当前基于深度神经网络的机器学习都需要一些损失函数来优化和反向传播;对于损失函数,应该有一些目标来计算。在LLM的背景下,目标是一组令牌中的下一个令牌(令牌近似于单词)。这样,我们可以将整个互联网文本(经过清洁处理)作为一个巨大的标记训练数据集。
让我们看看如何微调或重新训练预训练模型以预测不同的东西,例如在句子“我爱纽约”之前使用“动物园”而不是“城市”。这样,我们可以对LLM的训练和损失有一个直观的理解。
示例训练句子将是“我爱纽约动物园”。模型被输入第一个单词“我”,并输出一些内容。但是目标是给定的
love,并且通过训练计算交叉熵损失并将其最小化。最后,在York之后,目标是Zoo。标签或目标基本上是下一个令牌。这是纯粹的监督训练。由于模型很小,数据集也很小,所以这里没有进行无监督学习。
无论是对于小型玩具模型NanoGPT还是LLAMA2模型,使用的损失基本上都是交叉熵损失。
Softmax函数被用作神经网络的最后一层,以生成类别上的概率分布。在我们的情况下,类别是词汇表中的所有单词。
因此,需要损失函数来计算生成的概率分布与预期概率分布之间的差异。然后,将交叉熵损失应用于这个概率分布,以测量预测概率和真实类别标签之间的误差。
为了更好地理解,我们需要稍微深入Transformer架构。LLM模型通常被设计为因果语言模型或掩码语言模型(MLM),其中通过掩盖句子中的某些单词引入了一定的噪声(但模型能够看到句子中的所有标记)。这些也被称为单向模型和双向模型。
第三个选项是一种称为前缀因果或掩码语言建模的组合,其中训练数据中存在一个任务前缀字符串(例如“Translate to French:”)。最后一个选项是由T5型模型(FlanT5 ——用于文本到文本转换的模型的微调语言模型)所著名。(还有其他变体)
在训练这些模型时存在差异。对于因果语言模型,目标与输入相同,右移一个位置。对于掩码语言模型,我们需要创建一个去噪训练,其中目标是掩码的真实值。
因果语言模型被称为这样的模型,因为它以因果方式运作,基于先前的标记进行预测,推测基于这些标记之间的因果关系。如何找到这种关系是Transformer模型和“注意力”的角色的整个故事,《注意力就是你所需要的》论文介绍了Transformer网络。
很难用简单的方式解释这个概念。我强烈建议你观看这个解释视频,可能需要多次观看——YouTube上的Transformer网络中自注意机制背后的直觉解释视频。
我们可以说,在学习正确的“下一个”令牌进行预测的过程中,通过反向传播损失学习了每个令牌的三组权重——关键字权重、查询权重和值权重。这些形成了“注意力”机制的基础。上面的视频在这个位置非常漂亮地解释了这一点。
使用向量点积的概念来计算值向量,这是查询向量和关键字向量的点积的贡献的总和。
直觉是在向量嵌入空间中,“相似的向量”将具有较大的点积值和更高的贡献。这是捕捉句子中令牌/单词之间因果关联的技巧。
然后,通过反向传播调整权重,这意味着学习到的权重代表了一个新的、更好的句子上下文向量嵌入空间。(关键字和查询权重是多维的,有多个注意力头,因此不是一个向量空间,而是多个)
在Transformer中,存在多个注意力头,因此,哪个注意力头权重更大也可以通过权重进行调整。Transformer网络就是这种架构,其中因果关系的直觉被编码为线性神经网络层中的可学习权重。
我尝试在下面的简化图像中解释这个概念
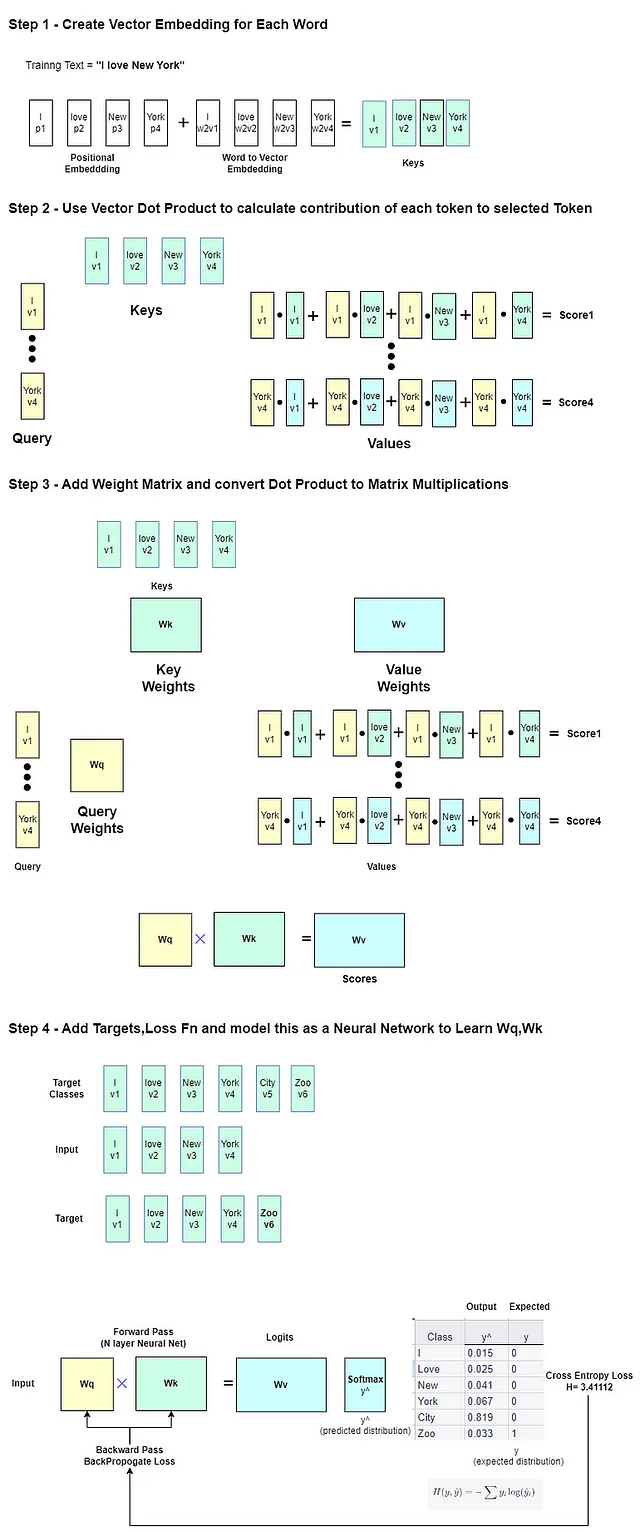
您可以在此处更详细地了解一个小型预训练模型的工作方式,该模型在“我爱纽约”之后最有可能生成“Ciy”,可以进行微调以减少损失以生成“Zoo”https://github.com/alexcpn/tranformer_learn/blob/main/LLM_Loss_Understanding.ipynb
因此,这里没有什么特别的。我们已经看到了通常所说的无监督学习(在LLM的背景下)通过监督训练,损失函数,训练(基于通常的梯度下降和反向传播)
然而,当网络变得庞大且训练数据变得庞大(十亿到万亿个标记),除了“曲线拟合”之外,还发生了一些其他现象,它可以将训练推广到“理解”训练数据的固有结构(人类语言,编程语言等),而无需明确为此进行训练。这是无监督学习的至高无上之法。
Ilya Sutskever在此视频中描述了这一现象https://youtu.be/AKMuA_TVz3A?t=490
因此,从谦虚的监督训练中,神秘的无监督学习演变而来
理解的出现
论文语言模型是无监督多任务学习者基于Transformer架构介绍了GPT-2。它做了一些非常特别的事情。
它经验性地证明了当一个足够大的LLM在一个足够大的数据集(CommomCrawl / WebText-清理后的互联网数据)上进行训练时,它开始“理解”语言结构。我刻意没有使用“泛化”这个不太具争议的术语,而是使用“理解”来更好地传达意思。
这是一篇易于阅读的Google / DeepMind研究论文,涉及该主题https://arxiv.org/pdf/2206.07682.pdf。
他们展示了八个模型,这些模型的新颖行为,根据随机选择的准确性进行衡量,在几项少样本提示任务中大幅提高。
同样的作者用更好的可视化工具讨论了这个问题(如下图所示)
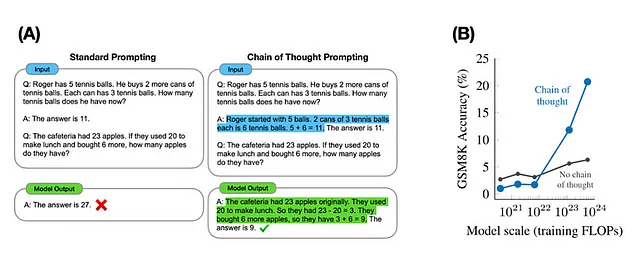
还有其他研究对此进行了反驳,这场辩论才刚刚开始。该论文提到了LLM在数学上的无能,这当然不是它的长项。
要真正理解一样东西,而不仅仅是一个概率分布生成器,就需要一个学习到的内部世界模型,根据Ilya Sutskever的说法。这使它与其他形式的机器学习和人工智能完全不同。
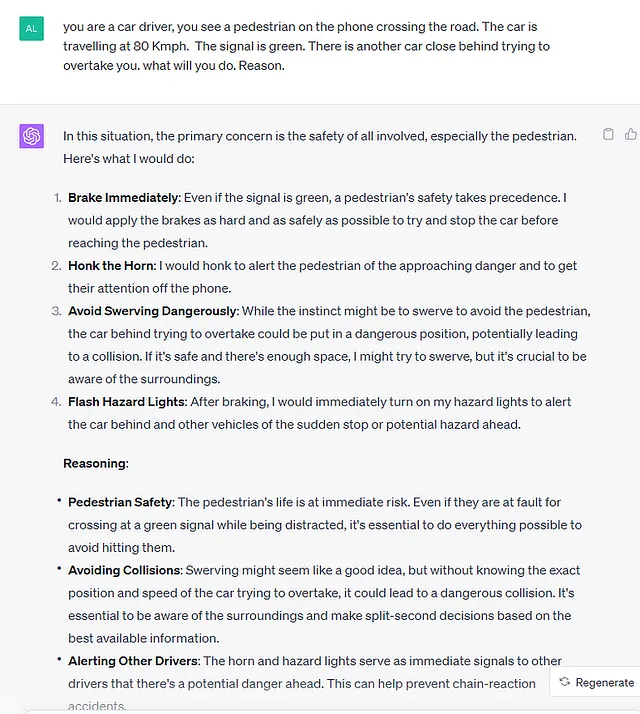
为了让这一点更清楚,这是ChatGpt4模型的一个示例输入和输出。该模型并没有明确接受汽车驾驶的训练。但是你可以看到它从训练数据中形成了一个世界观或世界模型,并可以全面地回答问题。
当训练和模型参数规模增加时,理解的出现方式尚不清楚,因为我们将其简化为概率分布函数生成器或忽视为随机鹦鹉可能在未来的研究中有更多的启示。随机性或其研究/测量-概率,在复杂的接口系统中的作用,例如《盲目的制表人》,与进化和量子物理学相关,有时让人反思是否有其他方式可以描述它们,而不仅仅是概率分布函数。这需要更多的研究和更多的结构来更清楚地解释。
例如,我搜索了熵和LLM,找到了这篇论文《研究LLM中相变的可能性》,还有Wolfarm的创始人和科学家Stephen Wolfarm的相关演讲。因此,在这些方向上思考并不牵强。
请注意,遵循这种语言属性的其他信号也可以成为LLM训练的有效候选项,其中信号可以被标记化,而不是词。一个例子是音乐,详见https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html。同样,不遵循这种模式的结构,比如DNA,可能对这些类型的模型来说更难适应。
回到重点——如何在各个领域中利用LLM的潜力正在展开竞争。我们将从简单的领域开始,然后逐渐扩展到更复杂的形式,其中模型的推理能力可以应用于实际应用中。这将在系列的第二部分中介绍。






