演化数据管道测试计划
'Evolutionary Data Pipeline Test Plan'
穷尽多源多目标测试驱动开发的危险
第一次接触测试驱动开发的想法会让许多初学者的数据工程师感到震惊,因为TDD承诺了更快的开发速度、更清晰的代码、职业晋升和世界统治,等等。然而,现实却大不相同。将TDD应用于数据工程的初次尝试会让许多数据工程师感到沮丧。获得TDD的价值需要付出很多努力。它需要对初学者DE工具包中不存在的测试技术有深入的了解。学习“什么”需要测试是困难的,学习将TDD应用于数据流程中固有的权衡更加困难。
在本文中,我们将介绍如何演变数据流程测试计划,以避免过度规定测试带来的痛苦。
问题
测试驱动开发有什么危险?对于新的数据工程师来说,TDD可能是一件危险的事情。对所有东西进行测试的初衷是很强烈的,但这可能导致不太理想的设计选择。就像他们所说的,好东西太多也不好。
对数据流程的每个部分进行测试是对于工程思维的人来说是一个诱人的方向。但为了保持理智,必然需要一些克制。否则,你最终会陷入一片红色的测试丛林中。而泥球也总是离你不远。
- 将深度学习论文中的数学实现转化为高效的PyTorch代码:SimCLR对比损失
- 如何将常规关系型数据库转换为向量数据库以存储嵌入向量
- 加州大学洛杉矶分校的研究员开发了一个名为ClimateLearn的Python库,用于以标准化和简单的方式访问最先进的气候数据和机器学习模型
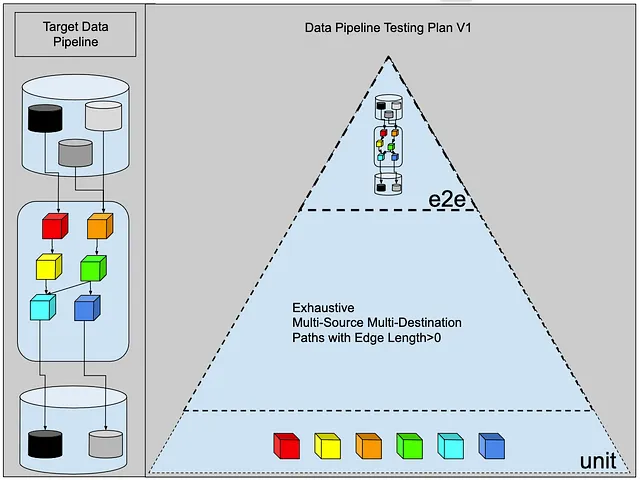
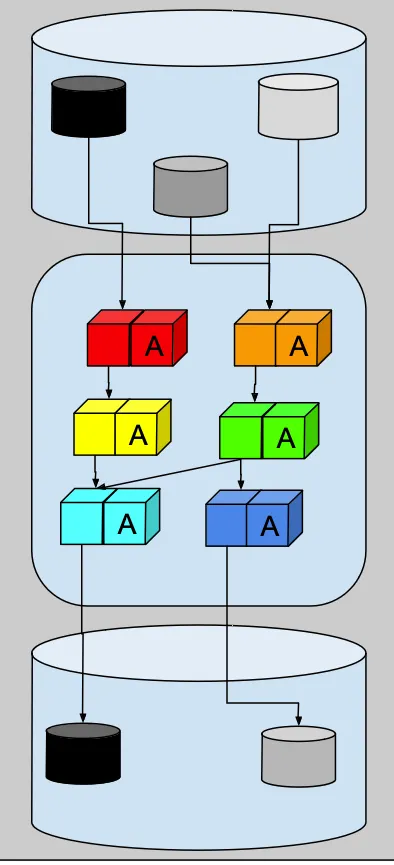
例如,假设我们有以下数据流程:

我们有三个数据源,六个转换和两个数据目标。
一位经验不足的数据工程师会制定什么样的测试计划呢?我们都曾经历过这个阶段。
解决方案一:穷尽多源多目标路径,边长>0
使用经典的三部分测试框架,我们可以安全地假设我们的数据工程师会从这里开始:
- 单元测试 ✅:确保为每个转换步骤进行单元测试,为每个转换步骤生成一些样本输入数据,将样本数据通过流程的每个步骤运行,捕获结果,并使用输出来验证转换逻辑。
- E2E测试 ✅:无论如何,我们都需要在完整的生产数据上运行流程,所以让我们在生产数据的样本上运行整个流程,捕获结果,并使用该输出来验证端到端流程。
- 集成测试 ❓❓❓:但在这里该怎么做呢?最初的倾向是为每个转换阶段构建一个测试。
在做了一些粗略计算后,我们的数据工程师开始了解到,6个转换步骤的组合会迅速增长。肯定有更好的方法。
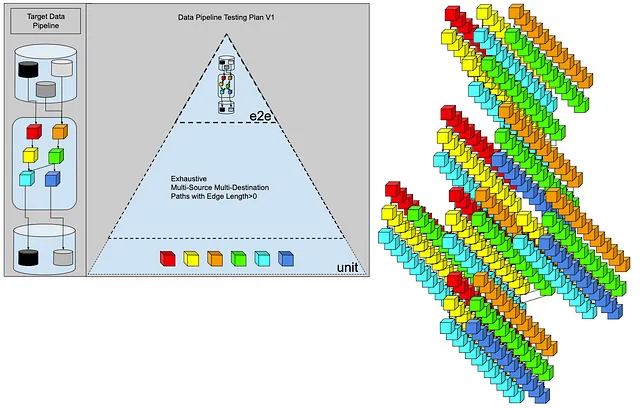
测试每个组合的可变长度边缘是无法在我们承诺给客户的截止日期之前完成的。我们应该为更多的时间预算。
解决方案二:
“好吧好吧,但情况应该不会那么糟糕。”
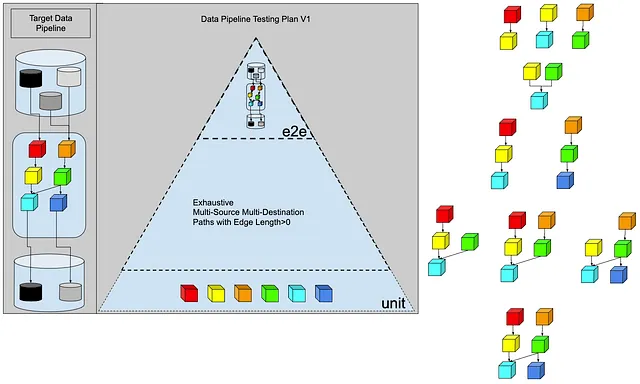
是的,考虑到集成测试不会触及真实的源和目标,那么就这样吧,让我们将这6个转换连接在一起。我们得到了下面的图形组合。我们大约有10个集成测试。
但请记住,这是数据工程,这意味着输入数据是我们无法控制的,并且会随时间变化。因此,我们需要在其中添加以数据为中心的测试。(您肯定更了解,但让我们遵循这个论点)。

解决方案#3:
“没错,但我们不能以某种方式总结这个问题吗?肯定有一组核心的数据验证场景我们需要绝对支持的吧?像一个数据验证事项的优先级列表?”
当然可以,但即使我们延迟数据验证检查,我们仍然会得到这样的情况:

“我们真的需要这么多的测试吗?验收测试不是测试用户看到的吗?我们不能为了按时交付一个解决客户问题的好产品而牺牲开发者体验吗?”
当然可以,下一个逻辑步骤是只运行端到端测试并继续我们的生活。但是,还有一个中间步骤可以解决“太多的集成测试”和“可靠的数据验证测试”两个问题。你可能以前用过它,但没有给它起个名字:“内联断言”。这是防御性编程传统中非常有用的技巧。
解决方案#4:
这些“内联断言”的核心思想是,尽可能将整个流水线作为一个包含代码接口和数据接口之间断言的单体构建。
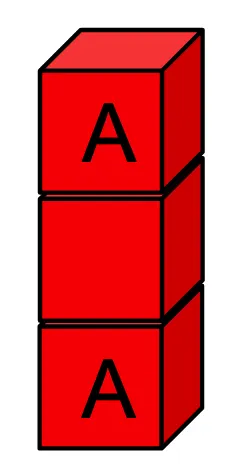
就是这样,将其放入红色、绿色、重构的开发循环中,并随机事务的发生而不断扩展该断言列表。
我们有点着急,但请注意我们正在使用生产数据源和生产接收器。如果你紧迫,就这样做。如果你有些时间,至少创建专用的测试接收器,并记住对从输入数据源获取的行数设置限制。
这对你可能很明显,但我们都在学习如何构建解决客户问题的数据流水线 🙂
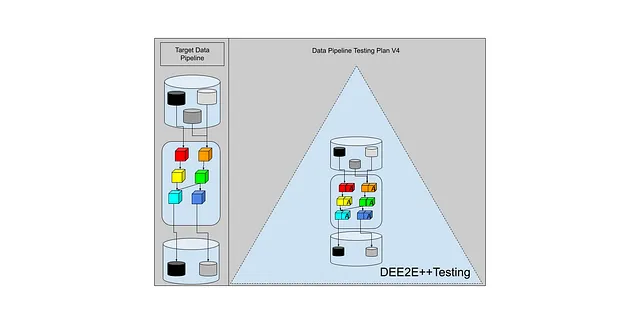
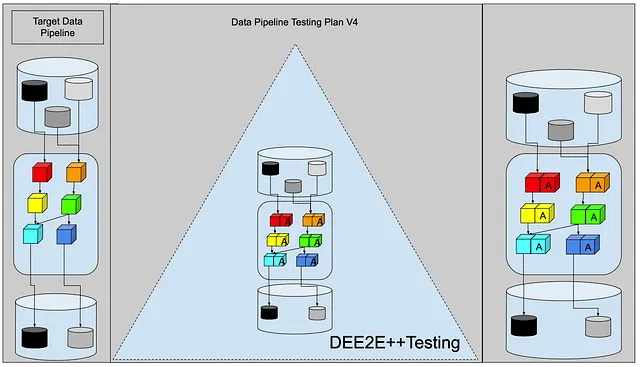
在受尊敬的测试金字塔中会是什么样子呢?
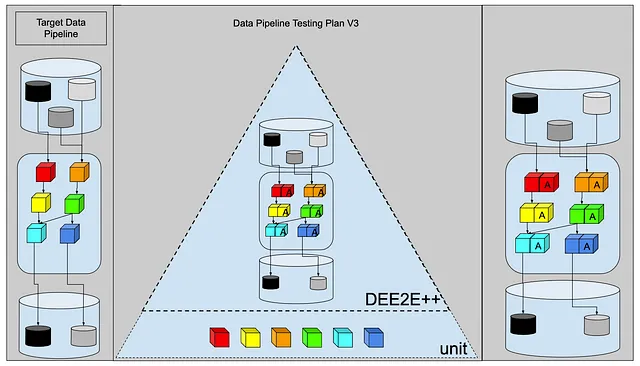
让我们称之为DEE2E++测试。数据工程端到端++测试。
看起来似乎有两种DEE2E++测试的形式:
- 普遍的反腐层(U-ACL)
- 主要是警告的反腐层(MW-ACL)
在普遍的一面,它看起来像这样:
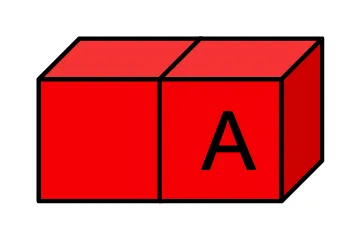
每个转换都有一个输入的反腐层,用于保护它免受上游更改的影响,并且有一个输出的反腐层,用于保护下游使用者免受当前转换的内部更改的影响。如果上游数据模式或内容发生变化,则输入ACL将停止处理并向用户报告错误。然后,如果我们更改当前转换的数据模式或内容,输出ACL也会捕获错误并停止处理。
对于一个初级的数据工程师来说,这是相当多的工作。在每个转换上添加强制验证规则将使数据工程师将数据处理变成“批处理工作”。他们会说:“如果我必须为每个转换都添加这些ACL,那将是转换数量的两倍。我还不如只添加两个。一个在流水线的顶部,一个在底部。至于转换的内部,我自己来处理。”这是一个有效的初始方法,重点在于1)顶级摄入逻辑和2)客户可见的数据输出。这种策略的问题在于我们失去了测试在本地化错误方面的好处。如果第4个转换中存在错误,ACL测试只会显示最终输出无效,而不会指示第4个转换是罪魁祸首。
此外,随着数据源的演变,我们所说的是90%的警告和10%的阻塞错误。仅仅因为输入数据中出现了一个新的列,并不意味着整个流水线应该失败。仅仅因为某列的分布均值稍微偏移,也并不意味着所有的数据都是无效的。客户可能仍然对最新的可用数据感兴趣,以便在需要时进行调整。
为此,您需要“大部分是警告的防腐层”。
它会通知开发人员出现了问题,但不会停止处理。它实现了与输入和输出ACL相同的作用,但对变化更加容忍。这种类型的ACL会发出警告和度量,并且开发人员可以稍后优先处理警告。如果情况完全失控,开发人员可以在修复数据转换后回填数据。
显然,实际情况可能有所不同。如果当前数据流水线的输出只有少数已建立的人工用户,则与消费者进行沟通将帮助新的开发人员了解领域知识。另一方面,如果此流水线有多个已建立的自动化数据流水线使用其输出,则DEE2E++测试可能不足够。然而,刚开始的新数据开发人员可能不会被指派到对数百个数据消费者产生影响的业务关键数据流水线上。因此,与其让新的数据开发人员被外部测试技术和业务关键领域同时压垮,不如从DEE2E++方法作为新的数据开发人员的良好起点。
这里是DEE2E++图表。
“等等,你是说每个组件只会得到一个仅警告的防腐层吗?”
不是“仅警告”,而是“大部分是警告”。某些断言肯定会停止处理并使作业失败。但是是的,这就是这个想法。如果您使用“普遍的防腐层”策略,那么您将需要更多的时间。随着领域越来越清晰,您可以在数据流水线的关键部分周围添加更严格的ACL。这种领域理解将有助于根据复杂性对转换进行排序。当您确定需要额外关注的复杂转换时,您可以从“MW-ACL”转移到“U-ACL”,以保护高度关键的业务逻辑。
“我的意思是,是的,但是那么为什么还要费心进行单元测试?它们不是在内联测试中已经覆盖了吗?”
当然,好吧,我们可以将它们移除。
好了?我想我们现在可以都回去工作了。
结论
简而言之,测试驱动开发的共同原则对于新的数据工程师来说可能是相当强大的。重要的是记住TDD是一种设计工具,而不是法律。明智地使用它,它将为您提供帮助。但是如果使用过度,您将发现自己处于困境之中。
在本文中,我们研究了过度规范化测试可能会发生的情况。首先,我们以一个看似简单的数据流水线为例,看看当我们陷入“穷尽多源多目的地路径”陷阱时会发生什么。然后,我们观察到与数据为中心的测试相比,集成测试只是冰山一角。最后,我们发现对于初学者数据工程师来说,一个好的起点是专注于具有“大部分警告防腐层”的端到端测试。这种DEE2E++测试策略有两个好处。首先,新手数据工程师不会在第一天就放弃测试。其次,它为开发人员提供了学习领域知识和迭代数据流水线设计的空间,利用他们已有的基本数据工程知识。他们不必立即陷入测试驱动开发的微观层面,而是可以向利益相关者交付可工作的软件,然后依靠DEE2E++测试提供的保护来添加更多细粒度的测试,以适应需求的演变。
所以这就是测试驱动开发的危害。愿你们都能避免这些问题,愿你们的数据流水线永远绿意盎然。
想了解更多关于现代数据流水线测试技术的内容吗?
请查看我关于这个主题的最新书籍。这本书以视觉指南的形式介绍了最流行的现代数据流水线测试技术。
2023年书籍链接:
书籍链接:现代数据流水线测试技术(leanpub上)
再见!
免责声明:本文所述观点为个人观点,不一定代表我目前或过去的雇主的观点。






