构建数据管道,使用大型语言模型创建应用程序
打造数据管道:利用大型语言模型开发应用程序

企业目前追求两种LLM动力应用的方法-微调和检索增强生成(RAG)。从非常高的层面上看,RAG输入并检索一组相关/支持文档,给定一个来源(例如,公司Wiki)。文档与原始输入提示串联为上下文,并馈送给LLM模型产生最终的响应。在实时处理场景中,RAG似乎是将LLM推向市场的最受欢迎的方法,特别是在实时处理情况下。要支持RAG的LLM架构大部分时间包括构建一个有效的数据管道。
在本文中,我们将探索LLM数据管道中不同的阶段,以帮助开发人员实现与其数据配合工作的生产级系统。跟随本文了解如何处理、准备、丰富和提供数据以支持GenAI应用。
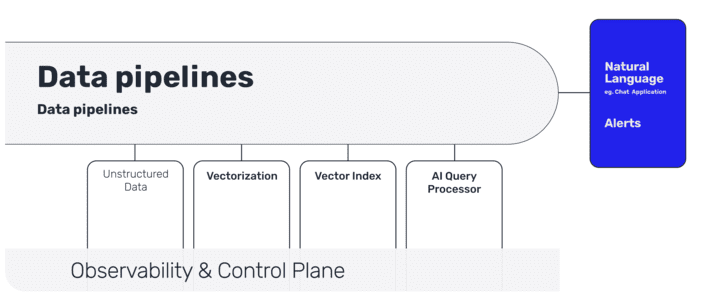
LLM管道的不同阶段是什么?
LLM管道的不同阶段包括:
非结构化数据的数据摄入
丰富的矢量化(enrichment)(带有元数据)
矢量索引(实时同步)
AI查询处理器
自然语言用户交互(使用聊天或API)
非结构化数据的数据摄入
第一步是收集合适的数据来帮助实现商业目标。如果您正在构建一个面向消费者的聊天机器人,那么您必须特别关注将使用哪些数据。数据源可以从公司门户网站(e.g. Sharepoint, Confluent, 文档存储)到内部APIs。理想情况下,您希望从这些源推送数据到索引中,以便您的LLM应用程序能够实时更新。
组织应在提取用于LLM上下文训练的文本数据时实施数据治理政策和协议。组织可以开始通过审核文档数据源来分类敏感级别、许可条款和来源。确定需要遮蔽或从数据集中排除的受限数据。
这些数据源还应评估其质量-多样性、规模、噪音水平、冗余。较低质量的数据集将稀释LLM应用的响应。您甚至可能需要一个早期的文档分类机制,以帮助在后续的管道中选择合适的存储方式。
即使在快节奏的LLM开发中,遵守数据治理的规则也可以降低风险。在前期建立治理措施可以减轻事后出现的许多问题,并使文本数据的上下文学习可扩展、稳健。
通过Slack、Telegram或Discord APIs拉取消息可实时获取数据,这有助于RAG,但原始对话数据包含噪音-拼写错误、编码问题、奇怪字符。实时过滤具有冒犯性内容或包含敏感个人细节(可能是PII)的消息是数据清洗的重要环节。
带有元数据的矢量化
作者、日期和对话上下文等元数据进一步丰富了数据。将外部知识嵌入向量有助于更智能、有针对性的检索。
有关文档的一些元数据可能位于门户网站或文档本身的元数据中,但如果文档附加到一个业务对象(例如案例、客户、员工信息),则必须从关系数据库中获取该信息。如果存在关于数据访问的安全问题,您可以在此处添加安全元数据,这也有助于后续的检索阶段。
在这里的一个关键步骤是将文本和图像转换为矢量表示,使用LLM的嵌入模型。对于文档,您需要首先进行文本分块,然后使用本地的零-shot嵌入模型进行编码。
矢量索引
向量表示必须存储在某个地方。这就是向量数据库或向量索引的用途,可以高效地存储和索引此类信息作为嵌入。
这将成为您的“LLM事实来源”,必须与您的数据源和文档保持同步。如果您的LLM应用程序为客户提供服务或生成相关业务信息,则实时索引变得很重要。您希望避免LLM应用程序与数据源不同步。
通过查询处理器实现快速检索
当您拥有数百万个企业文档时,基于用户查询获取正确的内容变得具有挑战性。
这就是管道的初级阶段开始增加价值的地方:通过元数据添加进行清理和数据丰富,并且最重要的是数据索引。该上下文添加有助于加强即时工程。
用户交互
在传统的流水线环境中,您将数据推送到数据仓库,分析工具将从仓库中获取报告。在LLM管道中,最常见的终端用户界面是一个聊天界面,最简单的层次是接收用户查询并对查询作出响应。
总结
这种新型管道的挑战不仅是获得一个原型,还要使其在生产环境中运行。此时,对您的管道和向量存储进行企业级监控的解决方案至关重要。从结构化和非结构化数据源获取业务数据成为重要的架构决策。LLMs代表自然语言处理的最新技术,并且构建面向LLM应用的企业级数据管道将使您处于领先地位。
在此处可访问一个可用的实时流处理框架。
[Anup Surendran](https://www.linkedin.com/in/anupsurendran/)是产品和产品营销副总裁,专注于推出AI产品。他曾与两家成功退出的初创公司(分别为SAP和Kroll)合作,并喜欢教授其他人如何使用AI产品提高组织的生产力。






