具有眼睛和耳朵的ChatGPT:BuboGPT是一种AI方法,可以在多模态LLMs中实现视觉定位
ChatGPT with eyes and ears BuboGPT is an AI method for visual localization in multimodal LLMs.


大型语言模型(LLMs)已成为自然语言处理领域的改变者。它们正在成为我们日常生活的重要组成部分。LLM的最著名例子是ChatGPT,可以安全地假设几乎每个人都了解它,并且大多数人每天都在使用它。
LLM的特点是它们的巨大规模和能够从大量文本数据中学习。这使它们能够生成连贯且在语境中相关的人类文本。这些模型基于深度学习架构构建,如GPT(生成预训练变换器)和BERT(双向编码器表示转换),它们使用注意机制来捕捉语言中的长距离依赖关系。
通过利用大规模数据集的预训练和特定任务的微调,LLMs在各种与语言相关的任务中展现出了卓越的性能,包括文本生成、情感分析、机器翻译和问答。随着LLMs的不断改进,它们具有极大的潜力来革新自然语言理解和生成,弥合机器和人类语言处理之间的差距。
另一方面,一些人认为LLMs没有充分发挥其潜力,因为它们仅限于文本输入。他们一直在努力扩展LLMs在语言之外的潜力。其中一些研究已成功将LLMs与各种输入信号(如图像、视频、语音和音频)集成起来,构建功能强大的多模态聊天机器人。
然而,在这方面仍有很长的路要走,因为这些模型大多数缺乏对视觉对象和其他模态之间关系的理解。虽然视觉增强的LLMs可以生成高质量的描述,但它们是以一种黑盒的方式进行,没有明确与视觉背景相关联。
在多模态LLMs中建立明确而信息丰富的文本和其他模态之间的对应关系可以提升用户体验,并为这些模型开启一系列新的应用。让我们来认识一下BuboGPT,它解决了这个限制。
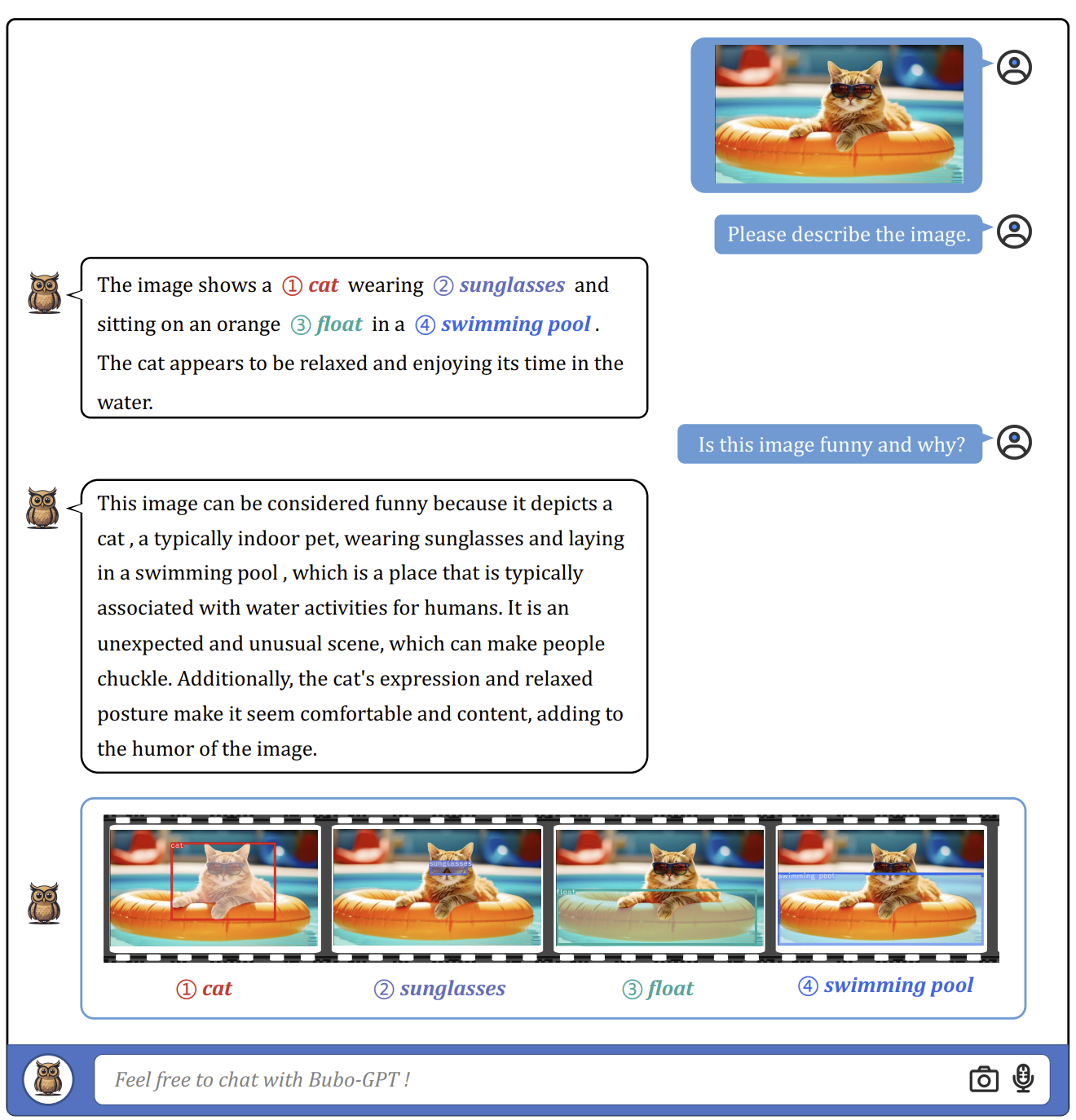
BuboGPT是将视觉定位引入LLMs的第一次尝试,通过将视觉对象与其他模态相连接。BuboGPT通过学习与预训练LLMs相匹配的共享表示空间,实现了文本、视觉和音频的联合多模态理解和对话。
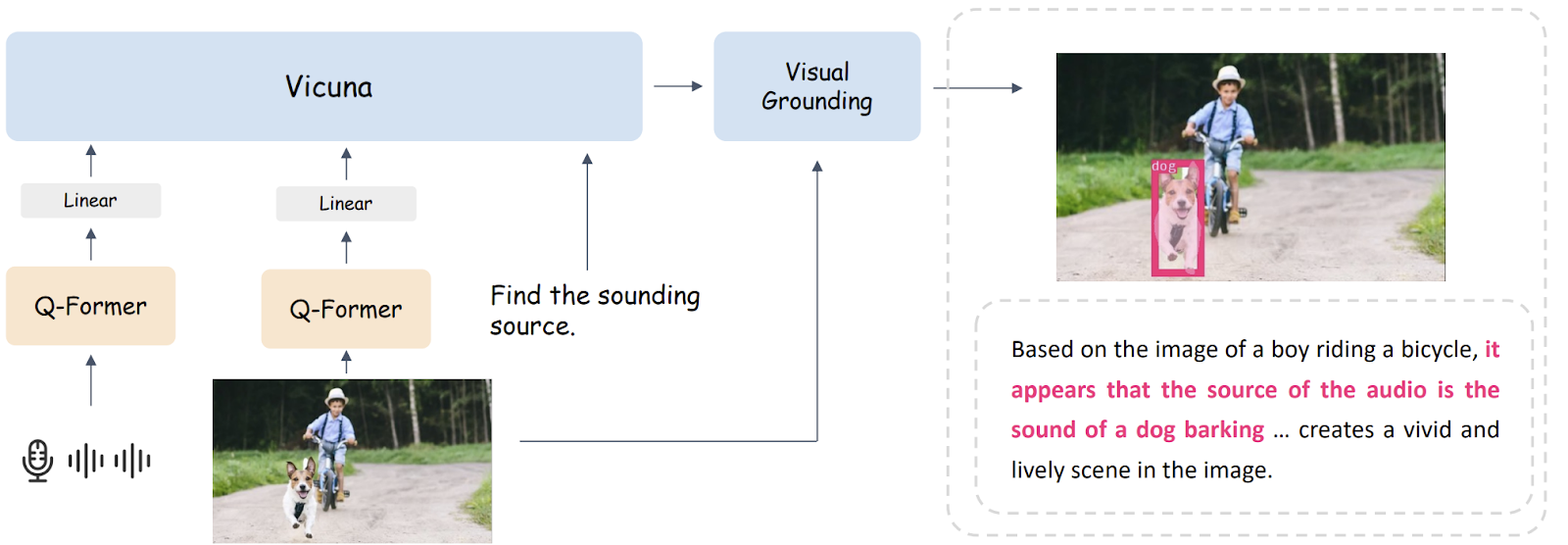
视觉定位并不是一项容易实现的任务,因此它在BuboGPT的流程中起着至关重要的作用。为了实现这一目标,BuboGPT基于自注意机制构建了一个流程。这个机制在视觉对象和模态之间建立了细粒度的关系。
这个流程包括三个模块:标记模块、定位模块和实体匹配模块。标记模块为输入图像生成相关的文本标签,定位模块为每个标签定位语义蒙版或方框,实体匹配模块使用LLM推理从标签和图像描述中检索匹配的实体。通过通过语言连接视觉对象和其他模态,BuboGPT增强了对多模态输入的理解。
为了实现对任意输入组合的多模态理解,BuboGPT采用了类似Mini-GPT4的两阶段训练方案。在第一阶段,它使用ImageBind作为音频编码器,BLIP-2作为视觉编码器,Vicuna作为LLM,学习一个将视觉或音频特征与语言对齐的Q-former。在第二阶段,它在高质量的指令遵循数据集上进行多模态指令调优。
构建这个数据集对于LLM识别提供的模态以及输入是否匹配至关重要。因此,BuboGPT构建了一个新颖的高质量数据集,其中包括用于视觉指令、音频指令、正面图像-音频配对的声音定位以及负面配对的图像-音频字幕,用于语义推理。通过引入负面图像-音频配对,BuboGPT学习到更好的多模态对齐,并展现出更强的联合理解能力。





