揭示AI幻觉:解码AI模型的黑暗面
AI幻觉:解码AI模型的黑暗面
可解释性人工智能简介
本文最初发布在louisbouchard.ai上,2天前我在我的博客上读到了这篇文章!

观看完整视频,带有一个应用示例!
像DALLE或ChatGPT这样功能强大的人工智能模型非常有用且好玩。但是,当它们出错时会发生什么呢?
如果它们在不知情的情况下对您撒谎怎么办?这些问题通常被称为幻觉,尤其是当我们盲目地相信人工智能时,这些问题可能会对我们造成伤害。我们应该能够追溯和解释这些人工智能模型是如何做出决策和生成结果的。
为了说明这一点,让我们看一个非常简单的例子。假设您是一位研究科学家,旨在构建一个能够对图像进行分类的模型,也就是识别图像中的主要对象。您收集了几张不同对象的图片,并训练一个算法来理解什么是猫、什么是狗等等…现在,您期望您的模型能够从任何图片中识别出这些对象,并在您的网站上发布供任何人使用。
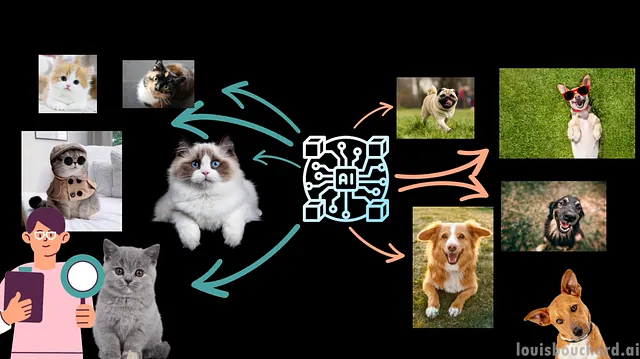
在这样做之前,您要先测试一下确保它的表现良好。在这里,我们可以看到模型的准确性相当高。它实际上发现这些都是动物的图片,而且,更准确地说,它甚至认出了是一只猫、一只狗和一只鲨鱼。太酷了!是时候将其上线了,您的工作完成了!
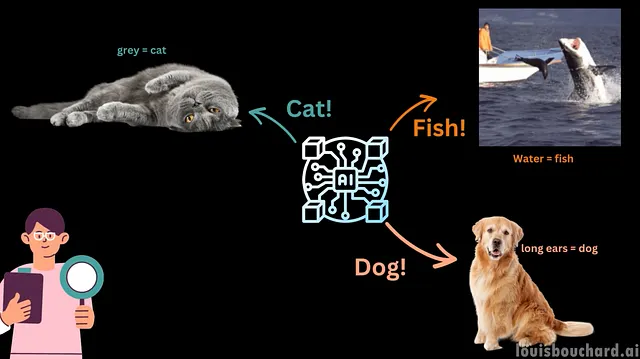
嗯,事实远非如此。如果您的模型实际上只是走运了呢?或者,更糟糕的是,它基于完全无关的图像部分做出决策。这就是一个非常重要的话题:可解释性。例如…




