使用机器学习预测NBA薪水
预测NBA薪水的机器学习
使用Python构建机器学习模型来预测NBA球员薪水并分析最具影响力的变量
NBA作为体育界最具利润和竞争力的联赛之一,薪水在过去几年里一直呈上升趋势,但每一个令人惊叹的扣篮和三分球背后都隐藏着一系列复杂的因素决定了这些薪水。
从球员表现和球队成绩到市场需求和代言交易,有许多变量在起作用。谁没有思考过为什么他们的球队花那么多钱在一个表现不佳的球员身上,或者对一个特别成功的交易背后的策略感到惊叹呢?
在本文中,我们使用Python的机器学习能力来预测NBA球员的薪水,并揭示对球员收入影响最大的关键因素。
所有使用的代码和数据都可以在GitHub上找到。
理解问题
在深入研究问题之前,了解联盟薪水体系的基本原理是至关重要的。当一名球员在市场上可以与任何球队签约时,他被称为自由球员(FA),这个术语在本项目中将经常使用。
NBA遵循一套复杂的规则和法规,旨在维持球队之间的竞争平衡。这个体系的核心有两个关键概念:薪水帽和奢侈税。
薪水帽作为一个支出限制,限制了球队在一个赛季内在球员薪水上的支出。薪水帽由联盟的收入决定,并每年更新,以确保球队在一个合理的财务框架内运作。它还旨在防止大市场球队在支出上远远超过小市场球队,促进球队之间的平衡。
薪水帽的分配可能会有所不同,顶级球员的最高薪水和新秀和老将的最低薪水。
然而,超过薪水帽并不罕见,特别是对于希望建立争夺总冠军阵容的球队来说。当一个球队超过薪水帽时,它进入了奢侈税的领域。奢侈税对超过一定门槛的球队施加罚款,既阻止球队过度支出,又为联盟提供额外收入。
还有许多其他作为例外的规则,比如中级例外(MLE)和交易例外,允许球队进行战略性的阵容变动,但对于本项目来说,了解薪水帽和奢侈税就足够了。

由于薪水帽的持续增长,所选的方法将使用薪水帽的百分比作为目标,而不是薪水金额本身。这个决定旨在纳入薪水帽的不断变化,确保结果不受时间变化的影响,并且在评估历史赛季时仍然适用。然而,需要注意的是,这并不是完美的,只是一个近似值。
数据
对于这个项目,目标是使用仅来自上个赛季的数据来预测下个赛季签订新合同的球员的薪水。
使用的个人统计数据包括:
- 每场比赛的平均统计数据
- 总统计数据
- 高级统计数据
- 个人变量:年龄,位置
- 与薪水相关的变量:上个赛季的薪水,上个赛季和本赛季的最高薪水帽以及该薪水的薪水帽百分比。
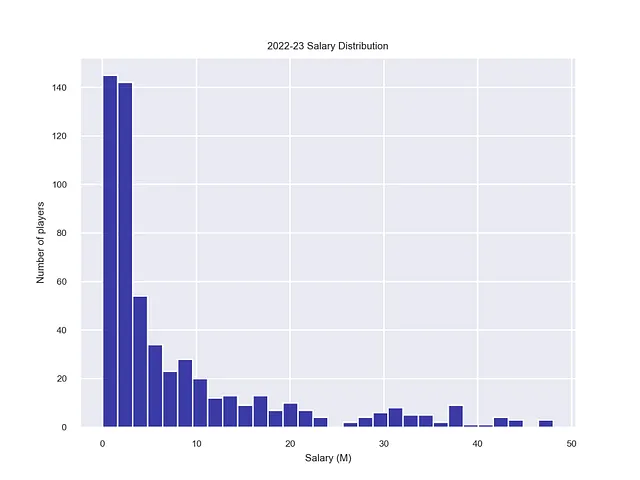
由于我们不知道球员将会签约的队伍,因此只包括了个人特征。
总共,这项研究为每个球员以及目标设定了78个特征。
大部分数据是使用我创建的一个名为BRScraper的最新Python包获得的,该包允许从Basketball Reference获取篮球数据,包括NBA、G联盟和其他国际联赛。遵循了有关对网站造成伤害或阻碍其性能的所有指导方针。
数据处理
一个有趣的方面是考虑用于模型训练的球员选择。最初,我选择了所有可用的球员,但其中大多数球员已经签订了合同,在这种情况下,薪资的价值并不会发生很大变化。
例如,假设一个球员签约4年,总价值为2000万美元。他每年收到的薪资约为500万美元(很少情况下所有年份的薪资完全相同,通常薪资在500万美元左右有一定的递增)。然而,当自由球员签订新合同时,薪资的变化可能会更加剧烈。
这意味着使用所有可用球员训练模型可能会导致整体性能更好(毕竟,大多数球员的薪资与最后一位球员非常接近!),但在评估仅限自由球员时,性能会显著下降。
由于目标是预测签订新合同的球员的薪资,所以只有这类球员应该包含在数据中,这样模型可以更好地了解这些球员之间的模式。
感兴趣的赛季是即将到来的2023–24赛季,但将使用从2020–21赛季开始的数据来增加样本数量,这是由于目标的选择。由于自由球员的数据缺失,不使用较旧的赛季数据。
这样,三个选择的赛季中有426名球员,其中84名是2023–24赛季的自由球员。
建模
训练集和测试集的划分设计为2023–24赛季的所有自由球员仅包含在测试集中,保持了大约70/30的比例。
最初,使用了几种回归模型:
- 支持向量机(SVM)
- 弹性网络
- 随机森林
- AdaBoost
- 梯度提升
- 轻梯度提升机(LGBM)
使用均方根误差(RMSE)和决定系数(R²)评估了每个模型的性能。
你可以在我之前的文章使用机器学习预测NBA MVP中找到每个指标的公式和解释。
使用机器学习预测NBA MVP
构建一个机器学习模型来预测NBA MVP并分析最具影响力的变量。
towardsdatascience.com
结果
查看包含所有赛季的整个数据集,得到了以下结果:

这些模型的性能都很好,随机森林和梯度提升得到了最低的RMSE和最高的R²,而AdaBoost在使用的模型中指标最差。
变量分析
一种有效的方法来可视化影响模型预测的关键变量是通过SHAP值,这是一种提供了每个特征如何影响模型预测的合理解释的技术。
同样,在使用机器学习预测NBA最有价值球员中可以找到关于SHAP及其图表如何解释的更深入的说明。
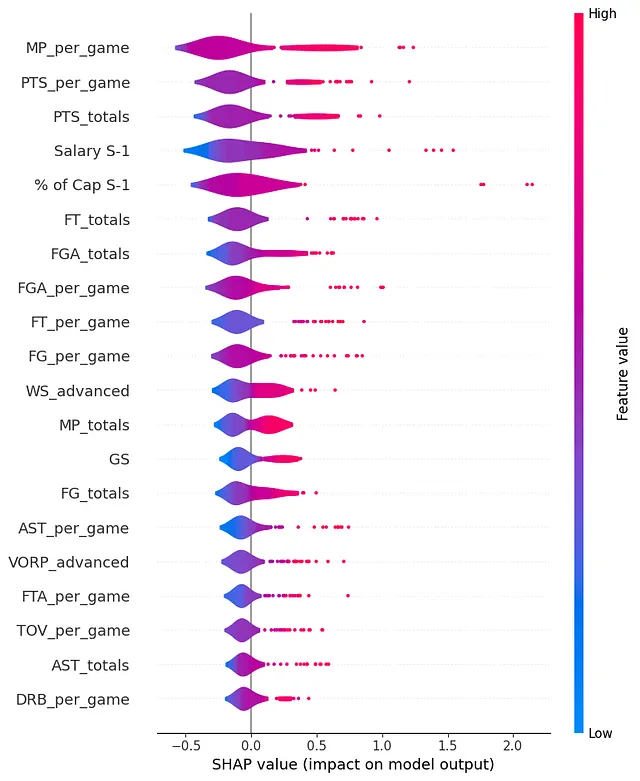
我们可以从这张图表中得出一些重要的结论:
- 场均上场时间(MP)和场均得分(PTS)以及总得分是最具影响力的三个特征。
- 上个赛季的薪水(Salary S-1)和该薪水占工资帽的比例(% Cap S-1)也非常有影响力,分别排在第4和第5位。
- 高级统计数据在最重要的特征中并不占主导地位,只有两个出现在列表中,即胜利贡献值(Win Share)和替补球员价值(Value Over Replacement Player)。
这是一个非常令人惊讶的结果,因为与MVP项目不同,其中高级统计数据主导了SHAP的最终结果,球员的薪水与场上时间、得分和首发比赛之间的关系要明显得多。
这令人惊讶,因为大多数高级统计数据的设计目的正是为了更好地评估球员的表现。在前20名中没有效率值(Player Efficiency Rating)(它在第43位出现)尤其引人注目。
这可能意味着在薪水谈判中,总经理们可能采取了相对简单的方法,有可能忽视了更广泛的绩效评估指标。
也许问题并不是那么复杂!简而言之,打得最多时间和得分最高的球员会赚更多的钱!
额外的结果
关注今年的自由球员,并将他们的预测与实际薪水进行比较:
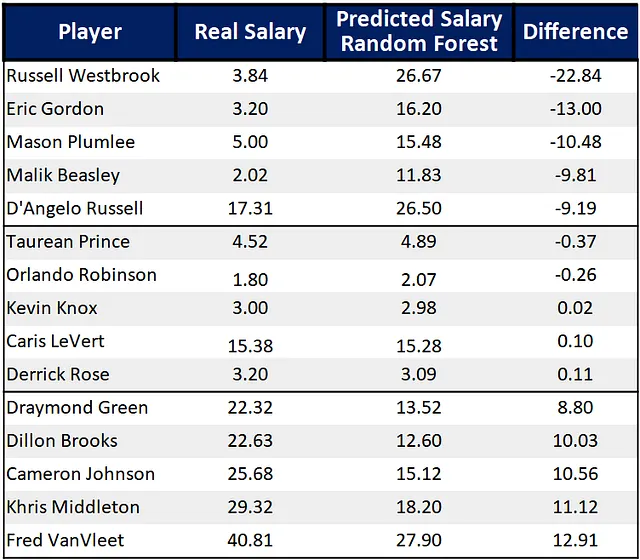
在顶部,我们有五名看起来被低估(收入低于应得收入)的球员,在中间五名球员价值适中,在底部五名球员被高估(收入高于应得收入)。需要注意的是,这些评估仅基于模型的输出。
从顶部开始,前MVP拉塞尔·威斯布鲁克是根据模型的评估被低估的球员,我认为这是事实,他与快船队签下了一份每年大约400万美元的合同。 埃里克·戈登、梅森·普拉姆利和马利克·比斯利也处于类似的情况,他们以出色的表现获得了很小的合同。 达吉洛·罗素尽管每年薪水为1700万美元,但也出现在前五名中,这表明他应该赚更多。
有趣的是,所有这些球员都与有竞争力的球队(快船队、太阳队、雄鹿队和湖人队)签约。这是已知的行为,球员选择赚更少的钱来有机会效力于一个有机会赢得冠军的球队。
在中间,托林·普林斯、奥兰多·罗宾逊、凯文·诺克斯和德里克·罗斯都获得了看起来适当的较小薪水。 卡里斯·莱弗特每年薪水1500万美元,看起来也正好合适。
在底部,《弗雷德·范弗利特》被任命为最被高估的球员。作为一支重建球队,火箭队以他的新签的三年合同价值1.285亿美元做出了一个值得注意的举动。他们还以较高的价格签下了迪隆·布鲁克斯。
克里斯·米德尔顿在今年夏天签下了一份大合同。尽管是一支有竞争力的球队,雄鹿队属于一个非主要市场,无法承受失去他们最好的球员之一。 德雷蒙德·格林和 卡梅隆·约翰逊在各自的球队也有类似的情况。
结论
预测体育比赛的结果一直是一个持续具有挑战性的任务。从目标的选择到球员的选择,这个项目比预期的更加复杂。然而,结果证明非常简单,并且所获得的结果非常令人满意!
当然,有多种方法可以改进这些结果,其中一种是使用特征选择或降维技术来减少特征空间的维度,从而减小方差。
此外,如果能够获得以前赛季的自由球员数据,也可以增加样本数量。然而,目前似乎无法公开获取这些数据。
许多其他外部变量也会对此产生影响。例如,毫无疑问,如果知道球队的情况,像上一年的排名、季后赛结果和已使用的薪金占比等变量可能会非常有信息量。然而,保持模拟实际自由球员情景的方法,其中球队未知,可能会得出更接近球员“真实价值”的结果,而不考虑签约球队的背景。
这个项目的一个主要前提是只使用上一赛季的数据来预测下一个薪水。将历史赛季的统计数据纳入考虑范围可能会提供更好的结果,因为球员的历史表现可以提供宝贵的见解。然而,这类数据的广泛性需要经过深思熟虑的特征选择来管理复杂性和高维度。
再次强调,所有使用的代码和数据都可以在GitHub上找到。
我随时可以通过我的渠道(LinkedIn和GitHub)与您保持联系。
感谢您的关注!👏
Gabriel Speranza Pastorello