贝叶斯深度学习简介
贝叶斯深度学习简介
欢迎来到令人兴奋的概率编程世界!本文是对该领域的简要介绍,您只需要对深度学习和贝叶斯统计有基本的了解。
通过阅读本文,您将对该领域及其应用有基本的了解,并了解它与传统深度学习方法的区别。
如果您像我一样,听说过贝叶斯深度学习,并猜测它涉及贝叶斯统计,但不知道具体如何使用,那您来对地方了。
传统深度学习的局限性
传统深度学习的主要局限性之一是,即使它们是非常强大的工具,它们也无法提供不确定性的度量。
Chat GPT可能会以极大的自信度说出错误的信息。分类器输出的概率通常不具备校准性。
- “忘记ChatGPT吧,这个新的AI助手完全领先,并将永久改变你的工作方式”
- 我在3天内创建了一个AI应用程序
- 使用Salesforce Data Cloud,通过Amazon SageMaker自带AI的能力
不确定性估计是决策过程中的关键因素,特别是在医疗保健、自动驾驶等领域。我们希望模型能够在对大脑癌症进行分类时能够估计自身的不确定性,并在这种情况下需要医疗专家进行进一步诊断。同样,我们希望自动驾驶汽车能够在识别到新环境时能够减速。
为了说明神经网络在风险估计方面有多糟糕,让我们来看一个非常简单的分类器神经网络,最后有一个softmax层。
softmax的名称很容易理解,它是一个Soft Max函数,意味着它是一个“平滑”的max函数版本。之所以这样命名,是因为如果我们选择了一个“硬”max函数,只选择具有最高概率的类别,那么其他类别的梯度将为零。
softmax函数也存在一个问题。它输出的概率校准性很差。在应用softmax函数之前,值的微小变化被指数压缩,导致输出概率的变化很小。
这经常导致过度自信,即使在面对不确定性时,模型也会为某些类别给出很高的概率,这是softmax函数的“max”特性固有的特点。
将传统神经网络(NN)与贝叶斯神经网络(BNN)进行比较,可以凸显出不确定性估计的重要性。当遇到训练数据中的熟悉分布时,BNN的确定性很高,但当我们远离已知分布时,不确定性增加,提供了更现实的估计。
下面是不确定性估计的一个示例:
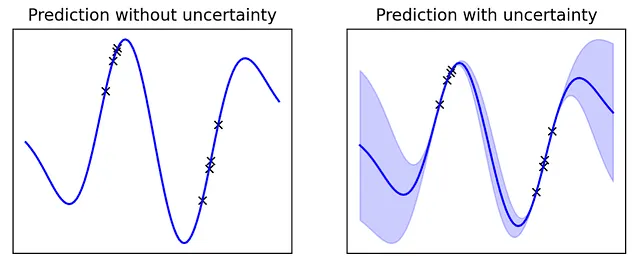
您可以看到,当我们接近训练过程中观察到的分布时,模型非常确定,但当我们远离已知分布时,不确定性增加。
贝叶斯统计简要回顾
贝叶斯统计中有一个核心定理需要了解:贝叶斯定理。

- 先验概率是在任何观察之前我们认为最有可能的theta分布。例如,对于抛硬币的情况,我们可以假设正面的概率是围绕p=0.5的高斯分布。
- 如果我们希望尽可能少地进行归纳偏见,我们还可以说p在[0,1]之间是均匀分布的。
- 似然概率是在给定参数theta的情况下,我们得到观测X、Y的可能性有多大
- 边缘似然概率是将似然概率在所有可能的theta上进行积分。它被称为“边缘”,是因为我们通过对所有概率进行平均,将theta边缘化。
贝叶斯统计学中的关键思想是,你从先验开始,它是你对参数可能的最佳猜测(它是一个分布)。然后根据你所观察到的情况,调整你的猜测,得到一个后验分布。
请注意,先验和后验不是关于θ的一个点估计,而是一个概率分布。
为了说明这点:
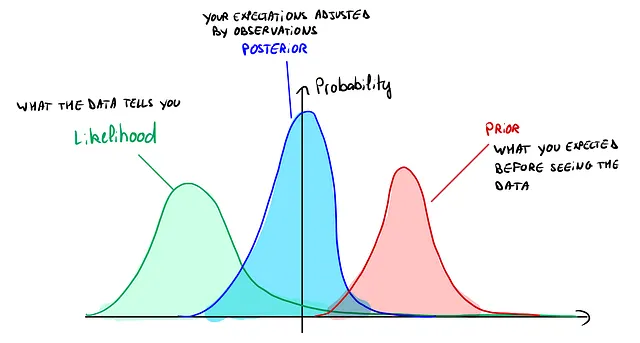
从这张图片中可以看出,先验向右侧偏移,但似然将我们的先验向左侧重新平衡,而后验则介于两者之间。
贝叶斯深度学习简介
贝叶斯深度学习是将两个强大的数学理论相结合的方法:贝叶斯统计学和深度学习。
与传统深度学习的基本区别在于对模型权重的处理:
在传统深度学习中,我们从头开始训练一个模型,随机初始化一组权重,并训练模型直到收敛为一组新的参数。我们学习到一组单一的权重。
相反,贝叶斯深度学习采用了一种更加动态的方法。我们从权重的先验信念开始,通常假设它们遵循正态分布。当我们将模型暴露给数据时,我们调整这种信念,从而更新权重的后验分布。实质上,我们学习到的是权重的概率分布,而不是一组单一的权重。
在推断过程中,我们根据后验分布对所有模型的预测进行加权平均。这意味着,如果一组权重非常可信,其对应的预测将被赋予更高的权重。
让我们将所有这些形式化:

贝叶斯深度学习中的推断通过使用后验分布对所有可能的θ(权重)的值进行积分。
我们还可以看到,在贝叶斯统计学中,积分无处不在。这实际上是贝叶斯框架的主要限制。这些积分通常是不可计算的(我们并不总是知道后验的原函数)。因此,我们必须进行计算非常昂贵的近似。
贝叶斯深度学习的优势
优势1:不确定性估计
- 贝叶斯深度学习最显著的优点之一是其对不确定性的估计能力。在许多领域,包括医疗保健、自动驾驶、语言模型、计算机视觉和量化金融等领域,量化不确定性对于做出明智决策和管理风险至关重要。
优势2:改进的训练效率
- 与不确定性估计的概念密切相关的是改进的训练效率。由于贝叶斯模型能够意识到自身的不确定性,它们可以优先学习不确定性(因此,学习潜力)最高的数据点。这种被称为主动学习的方法,导致了令人印象深刻的有效和高效的训练。
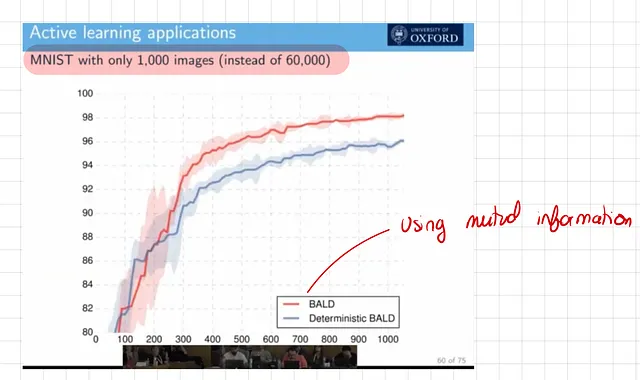
如下图所示,使用主动学习的贝叶斯神经网络在只有1,000个训练图像的情况下达到98%的准确率。相比之下,不利用不确定性估计的模型往往学习速度较慢。
优势3:归纳偏差
贝叶斯深度学习的另一个优点是通过先验有效地利用归纳偏置。先验允许我们对模型参数的初始信念或假设进行编码,这在存在领域知识的情况下特别有用。
考虑生成型人工智能,其目标是创建与训练数据相似的新数据(如医学图像)。例如,如果您正在生成脑部图像,并且您已经了解脑部的一般布局-白质在内部,灰质在外部-这些知识可以包含在您的先验中。这意味着您可以对图像中心的白质存在赋予更高的概率,并将灰质赋予边缘。
实质上,贝叶斯深度学习不仅使模型能够从数据中学习,还使其能够从知识的角度开始学习,而不是从头开始。这使其成为一种强大的工具,适用于各种应用。

贝叶斯深度学习的局限性
贝叶斯深度学习看起来令人难以置信!那么为什么这个领域如此被低估呢?确实,我们经常谈论生成型人工智能、Chat GPT、SAM或更传统的神经网络,但我们几乎从未听说过贝叶斯深度学习,为什么呢?
局限1:贝叶斯深度学习运行速度很慢
理解贝叶斯深度学习的关键是我们“平均”模型的预测,而每当有一个平均时,就会涉及到对参数集合的积分。
但是,计算积分通常是难以处理的,这意味着没有一个闭合或明确的形式可以快速计算这个积分。因此,我们无法直接计算它,我们必须通过抽样一些点来近似计算积分,这使得推理非常缓慢。
想象一下,对于每个数据点x,我们必须对10,000个模型的预测进行平均,而每个预测可能需要1秒的运行时间,这将导致模型在处理大量数据时不可伸缩。
在大多数业务案例中,我们需要快速和可伸缩的推理,这就是为什么贝叶斯深度学习并不那么流行的原因。
局限2:近似误差
在贝叶斯深度学习中,通常需要使用近似方法(如变分推断)来计算权重的后验分布。这些近似可能会导致最终模型中的误差。近似的质量取决于变分族和差异度量的选择,这可能是选择和适当调整的挑战。
局限3:模型复杂度和可解释性的增加
虽然贝叶斯方法提供了更好的不确定性度量,但这是以增加模型复杂性为代价的。贝叶斯神经网络可能很难解释,因为我们现在有了一组可能权重的分布,而不是单一的权重集合。这种复杂性可能会导致在解释模型决策时面临挑战,尤其是在强调可解释性的领域。
对于可解释人工智能(XAI)的兴趣越来越大,传统深度神经网络已经很难解释,因为很难理解权重,而贝叶斯深度学习更具挑战性。
如果您有任何反馈、想要分享的想法、与我合作的愿望,或者只是想打个招呼,请填写下面的表格,让我们开始交流吧。
打个招呼 🌿
请随意点赞或关注我以获取更多内容!
参考资料
- Ghahramani, Z. (2015). Probabilistic machine learning and artificial intelligence. Nature, 521(7553), 452–459. 链接
- Blundell, C., Cornebise, J., Kavukcuoglu, K., & Wierstra, D. (2015). Weight uncertainty in neural networks. arXiv preprint arXiv:1505.05424. 链接
- Gal, Y., & Ghahramani, Z. (2016). Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning (pp. 1050–1059). 链接
- Louizos, C., Welling, M., & Kingma, D. P. (2017). Learning sparse neural networks through L0 regularization. arXiv preprint arXiv:1712.01312. 链接
- Neal, R. M. (2012). Bayesian learning for neural networks (Vol. 118). Springer Science & Business Media. 链接





