“见面TR0N:一种简单高效的方法,可以为预训练的生成模型添加任何类型的条件”
见面TR0N 一种简单高效的方法,可为预训练生成模型添加条件


最近,大规模机器学习模型在各种任务中表现出色。然而,训练这样的模型需要大量的计算机计算能力。因此,正确有效地利用当前的大规模预训练模型至关重要。然而,仍然需要解决将各种模型的能力插入和融合的挑战。进行此任务的机制应该是模块化的和模型中立的,允许简单地切换模型组件(例如,用具有VAE的新的前沿文本/图像模型替换CLIP)。
在这项工作中,来自Layer 6 AI、多伦多大学和Vector研究所的研究人员调查了通过混合先前训练的模型进行条件生成的方法。给定一个条件变量c,条件生成模型旨在学习一个条件数据分布。它们通常是从头开始训练的,使用与c匹配的数据对,例如具有相应类标签或通过语言模型c提供的文本提示的图片x。他们希望通过使用一个模型G,将从先验分布p(z)中采样的潜变量z转换为数据样本x = G(z),将任何预训练的无条件推进生成模型变为条件模型。为此,他们提供了TR0N,一个广泛的框架,用于有条件地训练预训练的无条件生成模型。
TR0N假设可以访问经过训练的辅助模型f,一个分类器或一个CLIP编码器,将每个数据点x映射到其关联的条件c = f(x)。TR0N还期望访问一个函数E(z, c),为满足准则c的G(z)分配较低的值。使用这个函数,TR0N通过在T步中最小化E(z, c)关于z的梯度,为给定的c定位能够提供必要条件数据样本的潜变量。然而,他们证明了最初简单地优化E可能会更好。鉴于此,TR0N首先研究了一个网络,他们使用该网络来更有效地优化优化过程。
- AWS重申对负责任的生成式人工智能的承诺
- 合成字幕对于多模态训练是否有用?这篇AI论文展示了合成字幕在提高多模态训练的字幕质量方面的有效性
- 这个Python库“Imitation”提供了PyTorch中模仿和奖励学习算法的开源实现
由于它“翻译”一个条件c到一个匹配的潜变量z,使得E(z, c)最小,所以这个网络被称为翻译网络,因为它本质上摊销了优化问题。翻译网络在不调整G或使用预先制作的数据集的情况下进行训练,这一点很重要。TR0N是一种零样本方法,只有轻量级的翻译网络是可训练的部分。TR0N能够使用任何G和任何f,这也使得在有新的最新版本可用时,升级这些组件变得容易。这一点很重要,因为它避免了从头开始训练条件模型的极其昂贵的训练过程。
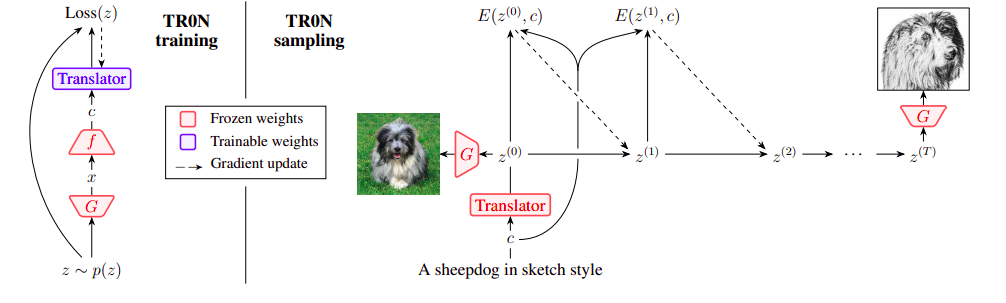
在图1的左侧面板上,他们描述了如何训练翻译网络。在翻译网络训练完成后,开始优化E的过程,使用它的输出。与初始简单初始化相比,这恢复了由于摊销差距而丢失的性能,产生更好的局部最优解和更快的收敛。可以将TR0N解释为使用Langevin动力学进行采样的一种方法,因为TR0N是一种随机方法。翻译网络是一个条件分布q(z|c),它对潜变量z分配高密度,以使得E(z, c)较小。他们还在E的梯度优化过程中添加噪声。在图1的右侧面板上,他们演示了如何使用TR0N进行采样。
他们做出了三个贡献:(i)引入了翻译网络及其特别有效的参数化方式,允许不同的Langevin动力学初始化方式;(ii)将TR0N框架作为一个高度通用的框架,而之前的相关工作主要集中在单个任务上,并具有特定的G和f选择;(iii)通过任务中图像质量和计算可行性方面的实证,证明了TR0N在竞争对手方面的表现优于其他选择,并能够产生多样化的样本。HuggingFace上有一个演示。