这个Python库“Imitation”提供了PyTorch中模仿和奖励学习算法的开源实现
The Python library Imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch.


在明确定义奖励函数的领域,如游戏中,强化学习(RL)已经超过了人类的表现。不幸的是,在真实世界中许多任务中,设计奖励函数是困难或不可能的,因此它们必须立即从用户反馈中吸收奖励函数或策略。此外,即使可以制定奖励函数,例如代理赢得游戏的情况下,为了有效地解决RL问题,得到的目标可能需要更稀疏。因此,在RL的最新结果中,经常使用模仿学习来初始化策略。
在本文中,他们提供了一个名为”模仿”的库,该库提供了七种奖励和模仿学习算法的优秀、可靠和模块化的实现。重要的是,他们的算法接口是一致的,使得训练和对比各种方法变得容易。此外,他们使用了像PyTorch和Stable Baselines3这样的现代后端来构建模仿。而以前的库则经常支持多种算法,不再积极更新,并且是建立在过时的框架上的。作为实验的基准,模仿具有许多重要的应用。根据早期的研究,模仿学习算法中的小实现细节可能会显著影响性能。
模仿力图使创建新的奖励和模仿学习算法的过程更简单,同时提供可靠的基线。如果使用了糟糕的实验基线,可能会导致错误的积极结果被报告。他们的技术经过了仔细的基准测试和与以前的解决方案的比较,以克服这个困难。他们还进行了静态类型检查,并对其代码进行了98%的测试覆盖。他们的实现是模块化的,允许用户在不修改代码的情况下灵活地修改奖励或策略网络的架构、RL算法和优化器。
- 新的AI驱动的SQL专家可以在几秒钟内构建SQL查询
- VoAGI新闻,7月19日:ChatGPT被废黜???•数据科学家的Docker•使用思维树提示进行推理
- 掌握GPU:Python中GPU加速数据框架的初学者指南
通过子类化和覆盖所需方法,可以扩展算法。此外,模仿提供了处理常规活动(例如收集回合数据)的实用方法,这有助于促进全新算法的创建。使用像PyTorch和Stable Baselines3这样的前沿框架构建模型是另一个优势。相比之下,许多当前的模仿和奖励学习算法的实现是多年前发布的,并且尚未得到更新。这对于与原始出版物一起提供的参考实现(如GAIL和AIRL代码库)尤其有效。
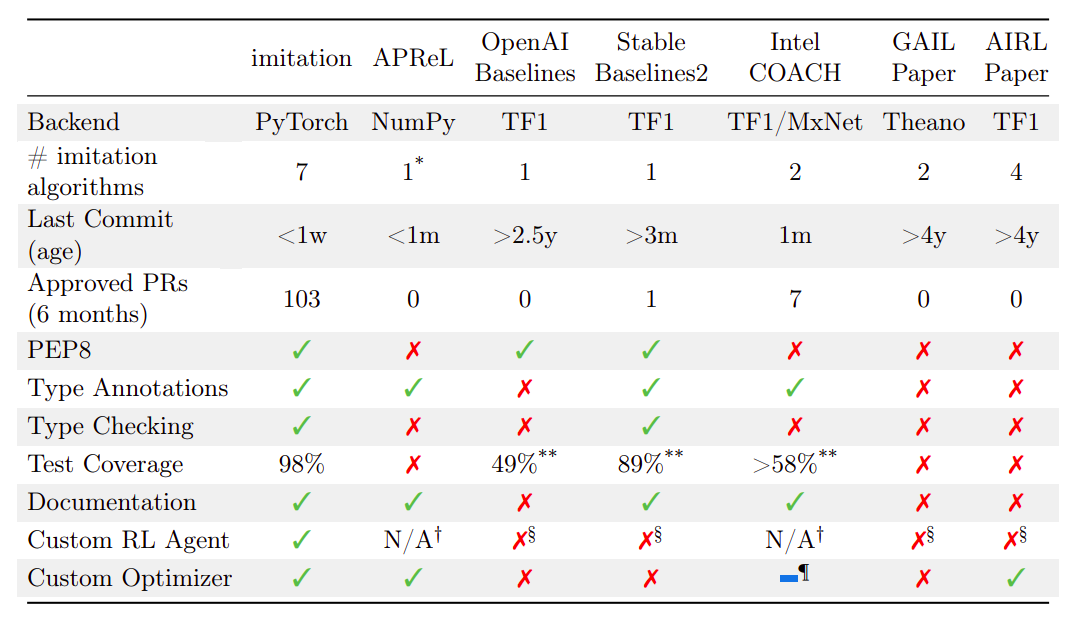
然而,即使是像Stable Baselines2这样的流行库也不再处于活跃开发阶段。他们在上面的表格中比较了各种指标的替代库。虽然不可能包括每个模仿和奖励学习算法的所有实现,但该表格包含了他们所知道的所有广泛使用的模仿学习库。他们发现,在所有指标上,模仿等于或超过其他替代方案。APRel在偏好比较学习低维特征方面表现出色。这与该模型相辅相成,该模型提供了更广泛的算法选择,并强调可伸缩性,但实现复杂性更高。PyTorch实现可以在GitHub上找到。





