虚假规范性增强了人工智能代理的合规和执行行为的学习
虚假规范性增强了AI代理的学习行为
在我们最近的论文中,我们探讨了多智能体深度强化学习如何作为复杂社会互动的模型,例如社会规范的形成。这种新型模型可以为创建更丰富、更详细的世界模拟提供一条途径。
人类是一种超级社会物种。相对于其他哺乳动物,我们更从合作中受益,但我们也更依赖合作,并面临更大的合作挑战。如今,人类面临着许多合作挑战,包括防止资源冲突,确保每个人都能获得清洁的空气和饮用水,消除极端贫困,以及应对气候变化。我们面临的许多合作问题很难解决,因为它们涉及称为社会生态系统的复杂社会和生物物理相互作用网络。然而,人类可以通过共同学习来克服我们面临的合作挑战。我们通过不断演变的文化来实现这一点,包括规范和制度,这些规范和制度组织我们与环境和彼此的互动。
然而,规范和制度有时无法解决合作问题。例如,个体可能过度开发像森林和渔业这样的资源,从而导致它们崩溃。在这种情况下,决策者可能制定法律来改变制度规则或制定其他干预措施,以试图改变规范,以期带来积极变化。但政策干预并不总是按预期起作用。这是因为现实世界的社会生态系统比我们通常用来预测候选政策效果的模型要复杂得多。
基于博弈论的模型经常被应用于文化进化的研究中。在这些模型中,代理之间的关键互动在“收益矩阵”中表示。在一个有两个参与者和两个动作A和B的游戏中,收益矩阵定义了四种可能结果的价值:(1)我们都选择A,(2)我们都选择B,(3)我选择A而你选择B,(4)我选择B而你选择A。最著名的例子是“囚徒困境”,其中动作被解释为“合作”和“背叛”。根据自我的短视自利行为的理性代理在囚徒困境中注定会背叛,即使更好的相互合作的结果是可行的。
博弈论模型已经被广泛应用。不同领域的研究人员使用它们来研究各种不同的现象,包括经济和人类文化的演化。然而,博弈论不是一个中立的工具,而是一种深具偏见的建模语言。它要求一切最终都必须以收益矩阵(或等效表示)来衡量。这意味着建模者必须了解或愿意假设关于个体行为如何相互作用以产生激励的一切。这在某些情况下是适当的,博弈论方法在建模寡头公司行为和冷战时期的国际关系等方面取得了很多显著成功。然而,博弈论作为一种建模语言的主要弱点在于在模型者不完全理解个体选择如何相互作用以产生收益的情况下会暴露出来。不幸的是,这往往是社会生态系统的情况,因为它们的社会和生态部分以我们尚未完全理解的复杂方式相互作用。
我们在这里呈现的工作是研究社会生态系统中替代建模框架的一个例子。我们的方法可以正式地看作是一种基于代理的建模。然而,它的独特之处在于结合了来自人工智能,特别是多智能体深度强化学习的算法元素。
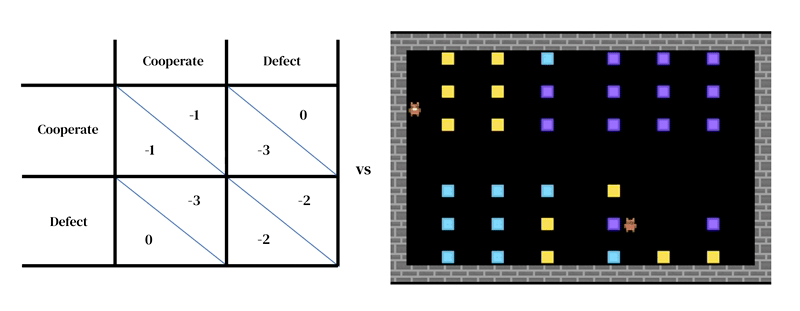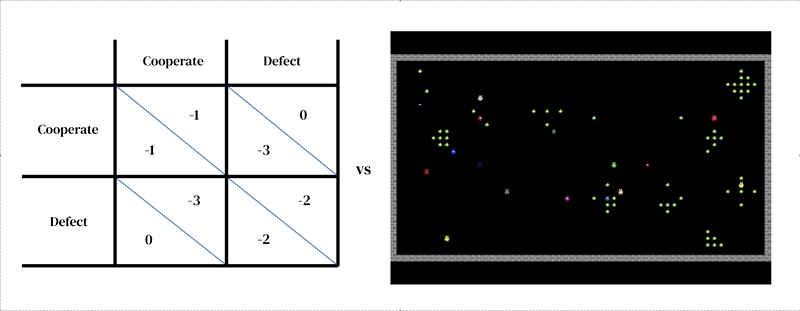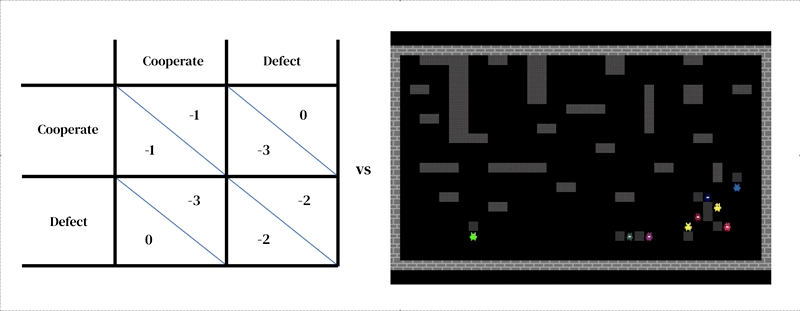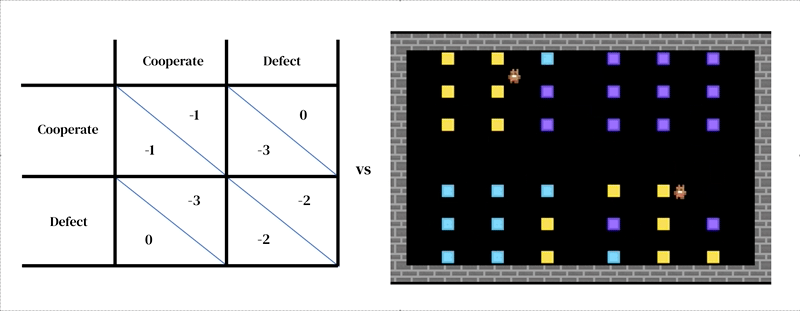
这种方法的核心思想是每个模型由两个相互关联的部分组成:(1)一个丰富的、动态的环境模型和(2)一个个体决策模型。
第一个部分采用研究人员设计的模拟器的形式:一个交互式程序,它接收当前环境状态和代理动作,并输出下一个环境状态以及所有代理的观察和即时奖励。个体决策模型也是基于环境状态进行调整的。它是一个从过去经验中学习的代理,执行一种试错形式。代理通过接收观察结果并输出行动与环境进行互动。每个代理根据其行为策略选择行动,这是一种从观察到行动的映射。代理通过改变其策略以改善在任何期望维度上的表现来学习,通常是为了获得更多的奖励。策略存储在神经网络中。代理从自己的经验中“从零开始”学习世界的运作方式以及如何获得更多奖励。他们通过调整网络权重的方式逐渐将他们接收的像素转化为胜任的行动。几个学习代理可以同时存在于彼此相同的环境中。在这种情况下,代理相互依赖,因为他们的行动会相互影响。
与其他基于代理的建模方法一样,多代理深度强化学习使得可以轻松地指定跨越分析层次的模型,这在博弈论中很难处理。例如,行动可能更接近于低级运动原语(例如“向前走”;“右转”),而不是博弈论中的高级战略决策(例如“合作”)。这是一个重要的特征,用于捕捉代理必须通过实践有效地学习如何实现其战略选择的情况。例如,在一项研究中,代理通过轮流清理河流来学会合作。这个解决方案之所以可能,是因为环境具有空间和时间维度,代理在其中对于如何构建彼此之间的行为具有很大的自由。有趣的是,虽然环境允许许多不同的解决方案(例如领土争夺),但代理会收敛于与人类玩家相同的轮流解决方案。
在我们最新的研究中,我们将这种类型的模型应用于文化演化研究中的一个悬而未决的问题:如何解释那些似乎对违规没有立即物质后果的虚假和武断的社会规范的存在。例如,在某些社会中,男性被期望穿裤子而不是裙子;在许多社会中,有一些词语或手势不应在有礼貌的场合使用;在大多数社会中,人们对如何发型或戴头饰有一些规定。我们将这些社会规范称为“愚蠢的规则”。在我们的框架中,强制和遵守社会规范都必须学习。拥有包含“愚蠢规则”的社会环境意味着代理有更多机会学习有关强制规范的知识。这种额外的练习使他们能够更有效地执行重要规则。总体而言,“愚蠢的规则”对于人口可能是有益的-这是一个令人惊讶的结果。这个结果之所以可能,是因为我们的模拟侧重于学习:强制和遵守规则是需要训练才能发展的复杂技能。
我们之所以对这种关于愚蠢规则的结果感到兴奋,部分原因是它展示了多代理深度强化学习在建模文化演化中的实用性。文化对于社会-生态系统的政策干预的成功与否起着重要作用。例如,加强回收利用方面的社会规范是解决某些环境问题的一部分解决方案。按照这个轨迹,更丰富的模拟可以带来对如何为社会-生态系统设计干预措施的更深入理解。如果模拟变得足够逼真,甚至可能测试干预措施的影响,例如设计一个促进生产力和公平的税法。
这种方法为研究人员提供了工具来指定他们感兴趣的现象的详细模型。当然,就像所有研究方法论一样,它应该预期具有自身的优点和缺点。我们希望在未来能够更多地了解何时可以有益地应用这种建模方法。虽然没有一种万能的建模方法,但我们认为在构建社会现象模型时,有充分的理由考虑多代理深度强化学习,特别是当它们涉及学习时。






