合成数据能提升机器学习性能吗?
能提升机器学习性能吗?
研究合成数据提高对不平衡数据集上模型性能的能力

背景 — 不平衡数据集
商业机器学习应用中经常出现不平衡分类问题。您可能会在客户流失预测、欺诈检测、医学诊断或垃圾邮件检测中遇到这些问题。在所有这些场景中,我们的目标是检测出属于少数类别的样本,而这些样本在我们的数据中可能非常少。有几种方法可以提高模型在不平衡数据集上的性能:
- 欠采样:通过随机欠采样多数类别,获得更平衡的训练数据集。
- 过采样:通过随机过采样少数类别,获得平衡的训练数据集。
- 加权损失:根据少数类别对损失函数进行加权。
- 合成数据:使用生成式人工智能创建高保真度的少数类别合成数据样本。
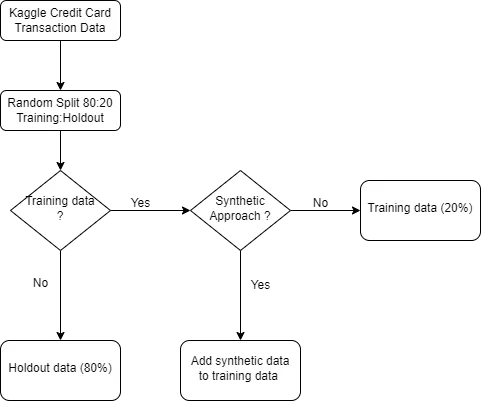
本文演示了如何在合成数据上训练模型,以超越其他方法来提高分类器的性能。
数据集
数据来源于Kaggle,包含284,807笔信用卡交易,其中492笔(0.172%)被标记为欺诈。该数据可在开放数据共享许可下供商业和非商业用途使用。
对于感兴趣的读者,Kaggle提供了关于数据的更详细信息和基本描述统计。
从这个Kaggle数据集中,我创建了两个子集:一个训练集和一个保留集。训练集占总数据的80%,在探索该方法时还包括合成生成的样本。保留集占原始数据的20%,不包括任何合成样本。