简化变压器:使用您理解的词进行最先进的自然语言处理(NLP)-第二部分-输入
简化变压器:自然语言处理(NLP)最新进展-第二部分-输入
深入了解transformer输入的构造
输入
龙从蛋中孵化出来,婴儿从腹中出生,AI生成的文本从输入开始。我们都必须从某个地方开始。什么样的输入?这取决于手头的任务。如果你正在构建一个语言模型,一个可以生成相关文本的软件(Transformers架构在各种场景中都很有用),输入就是文本。然而,计算机能接收任何类型的输入(文本、图像、声音)并神奇地知道如何处理它吗?它不能。
我相信你认识那些对文字不太擅长但在数字方面很棒的人。计算机有点像那样。它不能直接在CPU/GPU(计算发生的地方)中处理文本,但它肯定可以处理数字!正如你很快就会看到的,将这些单词表示为数字的方式是秘密酱料中的关键成分。
Tokenizer
分词是将语料库(你拥有的所有文本)转化为机器更好利用的较小部分的过程。假设我们有一个包含10,000篇维基百科文章的数据集。我们将每个字符进行转换(分词)。有很多方式可以对文本进行分词,让我们看看OpenAI的分词器是如何处理以下文本的:
“许多单词映射到一个标记,但有些不行:不可分割。”
像表情符号一样的Unicode字符可能会被拆分成包含底层字节的多个标记:🤚🏾
通常相邻的字符序列可能会被分组在一起:1234567890″
这是分词的结果:

如你所见,大约有40个单词(取决于你如何计算标点符号)。在这40个单词中,生成了64个标记。有时,标记就是整个单词,比如“许多、单词、映射”,有时它是单词的一部分,比如“Unicode”。我们为什么要将整个单词分成较小的部分?为什么要分割句子?我们本可以保持它们的完整性。最终,它们都会被转换为数字,所以从计算机的角度来看,如果标记是3个字符长还是30个字符长有什么区别呢?标记有助于模型学习,因为作为文本是我们的数据,它们是数据的特征。不同的特征工程方法会导致性能的差异。例如,在句子:“Get out!!!!!!!”中,我们需要决定多个“!”是否与一个“!”不同,或者它们是否具有相同的意义。从技术上讲,我们本可以保持句子的完整性,但是想象一下看一个人群和看每个人的场景,哪种情况下你能得到更好的洞察力呢?
现在我们有了标记,我们可以构建一个查找字典,允许我们摒弃单词并使用索引(数字)代替。例如,如果我们的整个数据集是句子:“上帝在哪里”。我们可以构建这样的词汇表,它只是单词和代表它们的单个数字的键值对。我们不需要每次都使用整个单词,我们可以使用这个数字。例如:{Where: 0, is: 1, god: 2}。每当我们遇到单词“is”,我们就用1来替换它。对于更多分词器的示例,你可以查看Google开发的分词器或者尝试一些OpenAI的TikToken。
词向量
直觉在将单词表示为数字的旅程中,我们正在取得很大进展。下一步将是从这些标记中生成数值的语义表示。为此,我们可以使用一个称为Word2Vec的算法。目前,细节并不是很重要,但主要思想是你可以使用一个任意大小的数字向量(我们暂且简化为普通的列表)来表示一个词的语义含义(论文的作者使用了512)。想象一下一个数字列表,如[-2, 4, -3.7, 41… -0.98],它实际上保存了一个词的语义表示。它应该以这样的方式创建,以便如果我们将这些向量绘制在一个二维图上,相似的术语会比不相似的术语更接近。
如您在图片中所见(来自此处),“Baby”靠近“Aww”和“Asleep”,而“Citizen”/“State”/“America’s”也有一定的分组。*2D词向量(即包含2个数字的列表)甚至无法准确地表示一个词的含义,正如作者所提到的,他们使用了512个数字。由于我们无法在512维空间中绘制任何内容,我们使用一种称为PCA的方法将维度数量减少到两个,希望能够保留原始含义的大部分。在本系列的第三部分中,我们将深入探讨这是如何发生的。
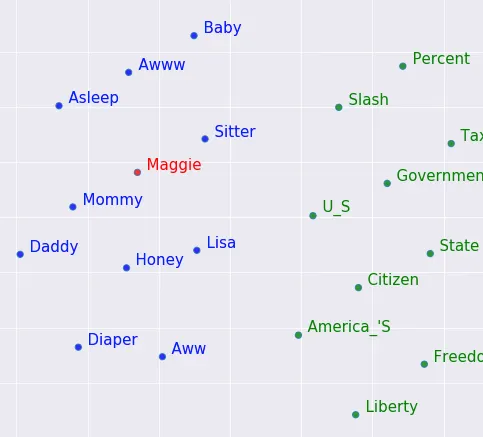
它起作用了!您实际上可以训练一个能够生成具有语义含义的数字列表的模型。计算机不知道“baby”是一个尖叫、剥夺睡眠(超级可爱)的小人类,但它知道它通常会在“aww”周围看到这个词,比“State”和“Government”更频繁。我将在接下来详细介绍它是如何发生的,但在那之前,如果您感兴趣,这可能是一个好地方。
这些“数字列表”非常重要,因此在机器学习术语中它们有自己的名称,即嵌入(Embeddings)。为什么叫嵌入?因为我们正在执行嵌入(如此有创意)的过程,即将一个术语从一种形式(单词)映射(翻译)到另一种形式(数字列表)。这些是很多()。从现在开始,我们将称单词为嵌入,正如前面解释的,它们是一系列数字,用于表示任何它被训练代表的词的语义含义。
使用Pytorch创建嵌入
我们首先计算我们拥有的唯一标记的数量,为简单起见,假设为2。创建嵌入层(Transformer架构的第一部分)将非常简单,只需编写以下代码:
*一般代码备注 —— 不要将此代码及其约定视为良好的编码风格,它是特别为了易于理解而编写的。
代码
import torch.nn as nnvocabulary_size = 2num_dimensions_per_word = 2embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds.weight)---------------------output:Parameter containing:tensor([[-1.5218, -2.5683], [-0.6769, -0.7848]], requires_grad=True)现在我们有了一个嵌入矩阵,这个例子中是一个2×2的矩阵,由从正态分布N(0,1)(例如,均值为0,方差为1的分布)中得出的随机数生成。请注意requires_grad=True,这是Pytorch中表示这4个数字是可学习权重的语言。它们可以并且将在学习过程中进行自定义,以更好地表示模型接收到的数据。
在更实际的情况下,我们可以期望得到一个接近10,000×512的矩阵,它用数字表示我们的整个数据集。
vocabulary_size = 10_000num_dimensions_per_word = 512embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds)---------------------output:Embedding(10000, 512)*有趣的事实(我们可以想出更有趣的事情),有时您会听到语言模型使用数十亿个参数。这个初始的、不太疯狂的层,包含了10,000×512个参数,即500万个参数。这个大型语言模型(LLM)是很困难的,它需要很多计算。这里的参数是那些数字(-1.525等)的一个花哨的词,只是它们是可变的,并且在训练过程中将发生变化。这些数字是机器的学习,这就是机器正在学习的内容。稍后当我们给它输入时,我们将输入与这些数字相乘,然后我们希望得到一个好的结果。你知道的,数字很重要。当你很重要时,你有自己的名字,所以这些不仅仅是数字,它们是参数。
为什么使用512而不是5个数字?因为更多的数字意味着我们可能能够生成更准确的含义。太棒了,不要想得太小,让我们使用一百万!为什么不呢?因为更多的数字意味着更多的计算、更多的计算能力、更昂贵的训练等。512被发现是一个中间的好地方。
序列长度
在训练模型时,我们将把大量的单词放在一起。这样做在计算上更高效,并且有助于模型在获取更多上下文时学习。如前所述,每个单词将由一个512维的向量(包含512个数字的列表)表示,每次我们将输入传递给模型(即前向传递),我们将发送一系列的句子,而不仅仅是一个句子。例如,我们决定支持一个50个单词的序列。这意味着我们将取出一个句子中的x个单词,如果x > 50,我们将其分割并只取前50个,如果x < 50,我们仍然需要大小完全相同(我很快会解释为什么)。为了解决这个问题,我们添加填充,即特殊的虚拟字符串,到句子的其余部分。例如,如果我们支持一个由7个单词组成的句子,而且我们有句子“Where is god”。我们添加4个填充,所以输入到模型的内容将是“Where is god <PAD> <PAD> <PAD> <PAD>”。实际上,我们通常添加至少2个额外的特殊填充,以便模型知道句子的起始位置和结束位置,所以实际上会是这样的:“<StartOfSentence> Where is god <PAD> <PAD> <EndOfSentence>”。
* 为什么所有输入向量必须具有相同的大小?因为软件有“期望”,而矩阵有更严格的期望。你不能随意进行任何“数学”计算,它必须遵守某些规则,其中之一是适当的向量大小。
位置编码
直觉我们现在有一种表示(和学习)词汇中单词的方法。让我们通过编码单词的位置使其变得更好。为什么这很重要?因为如果我们拿这两个句子来说:
1. The man played with my cat2. The cat played with my man
我们可以使用完全相同的嵌入来表示这两个句子,但是这两个句子有不同的含义。我们可以将这样的数据看作是无序的。如果我计算某个东西的总和,从哪里开始并不重要。在语言中,顺序通常很重要。这些嵌入包含语义含义,但没有确切的顺序含义。它们以某种方式保持顺序,因为这些嵌入最初是根据某种语言逻辑创建的(baby出现在sleep附近,而不是state附近),但是同一个单词在不同的上下文中可能有多个含义,更重要的是,可能有不同的含义。
将单词表示为无序的文本是不够的,我们可以改进这一点。作者建议我们在嵌入中添加位置编码。我们通过为每个单词计算一个位置向量,并将其与嵌入向量相加(求和)来实现这一点。位置编码向量必须具有相同的大小,以便可以相加。位置编码的公式使用了两个函数:对于偶数位置使用正弦函数(例如第0个单词、第2个单词、第4个单词、第6个单词等),对于奇数位置使用余弦函数(例如第1个单词、第3个单词、第5个单词等)。
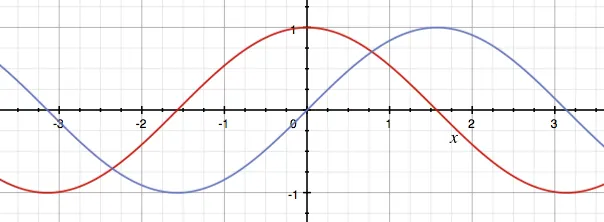
可视化通过观察这些函数(红色为正弦函数,蓝色为余弦函数),你或许可以想象为什么选择了这两个特定的函数。这些函数之间存在一些对称性,就像一个单词和它之前的单词之间存在一样,这有助于模型(表示)这些相关的位置。此外,它们输出的值范围在-1到1之间,这些是非常稳定的数字(它们不会变得非常大或非常小)。
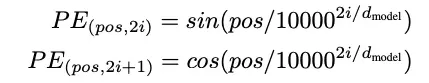
在上面的公式中,上一行表示从0开始的偶数(i = 0),并继续是偶数(2*1、2*2、2*3)。第二行以相同的方式表示奇数。
每个位置向量都是一个维度为number_of_dimensions(在我们的例子中为512)的向量,其中的数字从0到1。
代码
from math import sin, cosmax_seq_len = 50 number_of_model_dimensions = 512positions_vector = np.zeros((max_seq_len, number_of_model_dimensions))for position in range(max_seq_len): for index in range(number_of_model_dimensions//2): theta = pos / (10000 ** ((2*i)/number_of_model_dimensions)) positions_vector[position, 2*index ] = sin(theta) positions_vector[position, 2*index + 1] = cos(theta)print(positions_vector)---------------------输出:(50, 512)如果我们打印第一个单词,我们会发现我们只得到了0和1。
print(positions_vector[0][:10])---------------------输出:array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])第二个数字已经更加多样化了。
print(positions_vector[1][:10])---------------------输出:array([0.84147098, 0.54030231, 0.82185619, 0.56969501, 0.8019618 , 0.59737533, 0.78188711, 0.62342004, 0.76172041, 0.64790587])*代码的灵感来自这里。
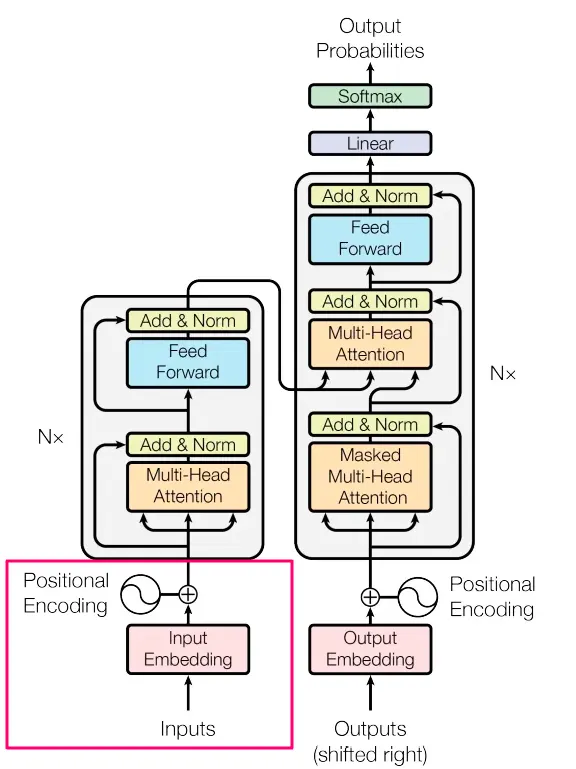
我们已经看到不同的位置会产生不同的表示。为了最终将该部分输入作为一个整体(在下图中用红色标记的正方形),我们将位置矩阵中的数字添加到我们的输入嵌入矩阵中。最终我们得到一个与嵌入大小相同的矩阵,只不过这次数字包含语义意义+顺序。

总结这是我们系列文章的第一部分(用红色框起来的部分)。我们讨论了模型如何获得输入。我们看到了如何将文本分解为其特征(标记),将它们表示为数字(嵌入)以及一种将位置编码添加到这些数字的聪明方法。
下一部分将重点介绍编码器块的不同机制(第一个灰色矩形),每个部分描述一个不同的彩色矩形(例如多头注意力,添加和归一化等)。





