一项来自特拉维夫和哥本哈根大学的新的人工智能研究引入了一种“即插即用”的方法,通过使用辨别信号来快速微调文本到图像扩散模型
特拉维夫和哥本哈根大学的人工智能研究通过辨别信号快速微调文本到图像扩散模型


文本到图像扩散模型在根据输入文本描述生成多样且高质量图像方面取得了令人印象深刻的成功。然而,当输入文本在词汇上存在歧义或涉及复杂细节时,这些模型会遇到挑战。这可能导致意图的图像内容(如用于衣服的“熨斗”)被错误地表现为“元素”金属。
为了解决这些限制,现有方法采用了预训练的分类器来指导去噪过程。一种方法涉及将扩散模型的分数估计与预训练分类器的对数概率梯度混合。简单来说,这种方法使用了扩散模型和预训练分类器的信息,以生成与所需结果匹配并与分类器对图像的判断相符的图像。
然而,这种方法需要一个能够处理真实和嘈杂数据的分类器。
其他策略使用特定数据集上的类标签来条件化扩散过程。虽然有效,但这种方法远未达到在网络上训练的图像-文本对的模型的完全表达能力。
另一个方向是使用与特定概念或标签相关的少量图像对扩散模型或其输入令牌进行微调。然而,这种方法存在一些缺点,包括为新概念进行缓慢训练、图像分布的潜在变化以及从小组图像中捕获的有限多样性。
本文提出了一种解决这些问题的方法,提供了更准确的期望类别表示,解决了词汇歧义问题,并改善了细节的描绘。它实现了这一点,而不损害原始预训练扩散模型的表达能力或面临上述缺点。该方法的概述如下图所示。
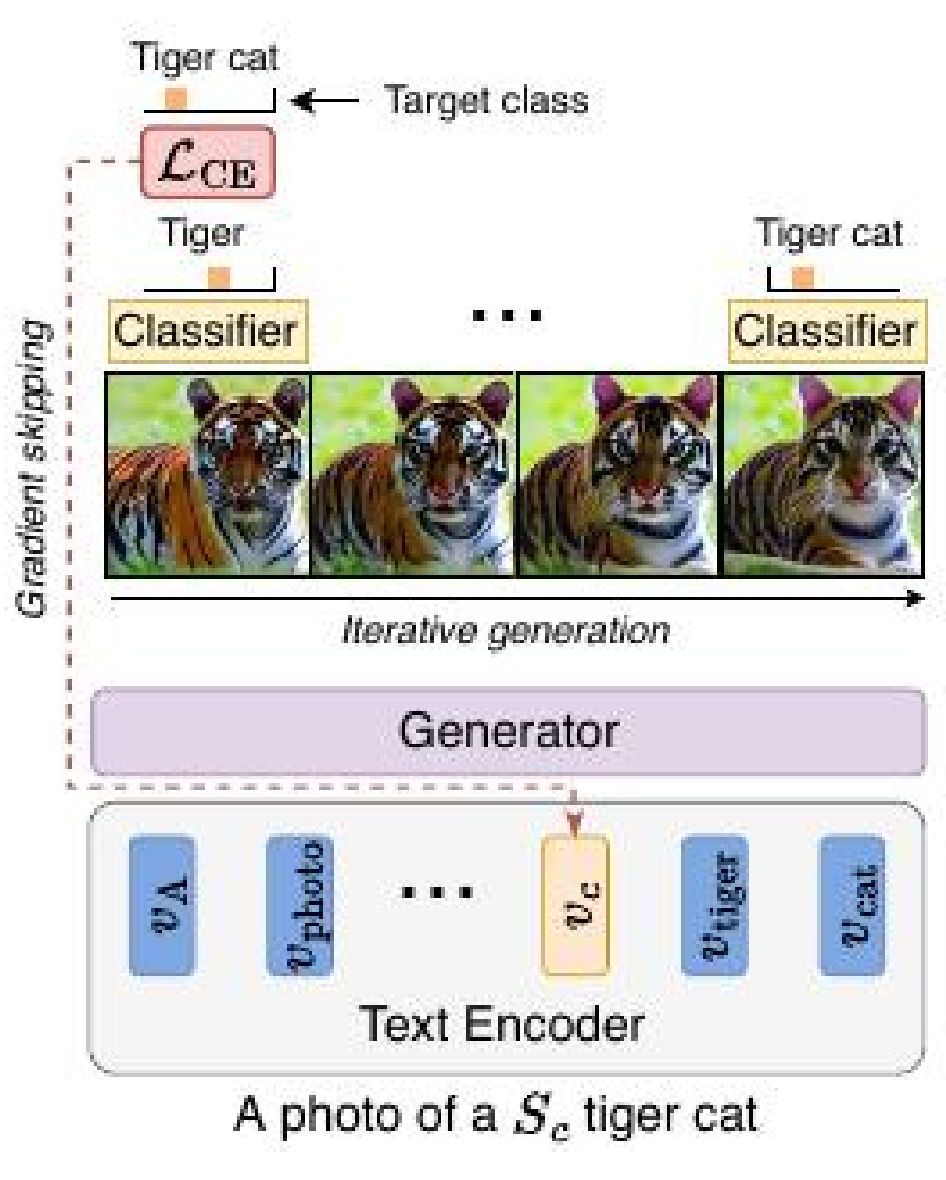

与指导扩散过程或改变整个模型不同,这种方法专注于更新与每个感兴趣类别对应的单个添加令牌的表示。重要的是,这种更新不涉及在标记图像上进行模型调整。
该方法通过生成新图像的迭代过程来学习特定目标类别的令牌表示,这些图像具有更高的类别概率,根据预训练分类器的反馈指导每次迭代中指定类别令牌的演变。采用了一种称为梯度跳过的新优化技术,其中梯度仅通过扩散过程的最终阶段传播。然后,优化后的令牌被纳入作为条件文本输入的一部分,使用原始扩散模型生成图像。
根据作者的说法,该方法具有几个关键优势。它仅需要一个预训练的分类器,并且不需要在嘈杂数据上明确训练的分类器,这使其与其他类别条件技术有所区别。此外,它在速度上表现出色,一旦训练了一个类别令牌,就可以立即改善生成的图像,而不需要更耗时的方法。
从研究中选择的样本结果如下图所示。这些案例研究提供了所提出的方法与最先进方法的比较概述。

这是一种新颖的AI非侵入性技术的摘要,利用预训练的分类器来微调文本到图像扩散模型。如果您感兴趣并想了解更多信息,请随时参考下面引用的链接。






