深入淺出pandas的Copy-on-Write模式:第一部分
深入浅出pandas的Copy-on-Write模式
解析Copy-on-Write内部工作原理

介绍
pandas 2.0在4月初发布,为新的Copy-on-Write(CoW)模式带来了许多改进。该功能预计将在pandas 3.0中成为默认选项,预计于2024年4月发布。目前没有计划支持遗留或非CoW模式。
这个系列的文章将解释Copy-on-Write的内部工作原理,帮助用户理解正在发生的事情,展示如何有效使用它,并说明如何调整代码。这将包括如何利用该机制以获得最高效的性能,并展示一些会导致不必要瓶颈的反模式。我几个月前写了一篇简短的Copy-on-Write介绍。
我写了一篇简短的文章,解释了pandas的数据结构,这将帮助您理解一些在CoW中必需的术语。
我是pandas核心团队的一员,一直积极参与实施和改进CoW。我是Coiled的开源工程师,在那里我负责Dask,包括改进pandas的集成,并确保Dask与CoW兼容。
Copy-on-Write如何改变pandas的行为
你们中的许多人可能熟悉pandas中的以下注意事项:
import pandas as pddf = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})让我们选择grade列并将第一行覆盖为"E"。
grades = df["grade"]grades.iloc[0] = "E"df student_id grade0 1 E1 2 C2 3 D不幸的是,这也更新了df而不仅仅是grades,这可能会引入难以找到的错误。CoW将禁止这种行为,并确保仅更新df。我们还会看到一个无用的SettingWithCopyWarning。
让我们看一个没有任何作用的ChainedIndexing示例:
df[df["student_id"] > 2]["grades"] = "F"df student_id grade0 1 A1 2 C2 3 D在这个例子中,我们再次遇到SettingWithCopyWarning,但df没有发生任何变化。所有这些陷阱归结为NumPy中的复制和视图规则,这是pandas在底层使用的。pandas用户必须了解这些规则以及它们如何适用于pandas DataFrame,才能理解为什么类似的代码模式会产生不同的结果。
CoW消除了所有这些不一致之处。当启用CoW时,用户只能同时更新一个对象,例如,在我们的第一个示例中,只会修改grades,而不会修改df;在第二个示例中,会引发ChainedAssignmentError而不是什么都不做。通常情况下,不可能同时更新两个对象,例如,每个对象都表现得像前一个对象的副本。
还有许多这样的情况,但在这里不会详细介绍所有情况。
它是如何工作的
让我们更详细地了解Copy-on-Write,并强调一些值得知道的事实。这是本文的主要部分,内容相当技术性。
Copy-on-Write承诺任何从其他DataFrame或Series派生的对象无论以任何方式派生,始终表现为副本。这意味着不可能通过单个操作修改多个对象,例如,我们上面的第一个示例只会修改grades。
一种非常保守的方法是在每个操作中复制DataFrame及其数据,这将完全避免pandas中的视图。这将确保写时复制语义,但也会导致巨大的性能损失,因此这不是一个可行的选择。
现在我们将深入探讨确保没有两个对象会被单个操作更新并且我们的数据不会被不必要地复制的机制。第二部分是实现中的有趣之处。
我们必须确切地知道何时触发复制以避免不必要的复制。只有当我们尝试在一个pandas对象中变异其值而不复制其数据时,潜在的复制才是必要的。如果这个对象的数据与另一个pandas对象共享,我们必须触发复制。这意味着我们必须跟踪一个NumPy数组是否被两个DataFrames引用(通常,我们必须知道一个NumPy数组是否被两个pandas对象引用,但为了简单起见,我将使用DataFrame这个术语)。
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})df2 = df[:]这个语句创建了一个DataFrame df 和这个DataFrame的一个视图 df2。视图意味着两个DataFrame都由相同的底层NumPy数组支持。从写时复制的角度来看,df 必须知道 df2 也引用了它的NumPy数组。但这还不够。df2 也必须知道 df 引用了它的NumPy数组。如果两个对象都知道有另一个DataFrame引用相同的NumPy数组,那么我们可以在其中一个被修改时触发复制,例如:
df.iloc[0, 0] = 100这里在原地修改了 df。 df 知道还有另一个对象引用了相同的数据,例如它触发了复制。它不知道哪个对象引用了相同的数据,只知道有另一个对象存在。
让我们看看如何实现这一点。我们创建了一个内部类 BlockValuesRefs 用于存储这些信息,它指向所有引用给定NumPy数组的DataFrames。
有三种不同类型的操作可以创建一个DataFrame:
- 从外部数据创建一个DataFrame,例如通过
pd.DataFrame(...)或通过任何I/O方法。 - 通过触发原始数据的复制来创建一个新的DataFrame,例如
dropna在几乎所有情况下都会创建一个副本。 - 通过不触发原始数据的复制来创建一个新的DataFrame,例如
df2 = df.reset_index()。
前两种情况很简单。当创建DataFrame时,支持它的NumPy数组会连接到一个新的 BlockValuesRefs 对象。这些数组只被新对象引用,所以我们不必跟踪任何其他对象。该对象创建一个指向包装NumPy数组的 Block 的弱引用,并在内部存储此引用。块的概念在这里解释。
弱引用创建对任何Python对象的引用。它在原本应该超出范围时不会保持此对象的存活。
import weakrefclass Dummy: def __init__(self, a): self.a = aIn[1]: obj = Dummy(1)In[2]: ref = weakref.ref(obj)In[3]: ref()Out[3]: <__main__.Dummy object at 0x108187d60>In[4]: obj = Dummy(2)这个例子创建了一个Dummy对象和对该对象的弱引用。之后,我们将另一个对象分配给相同的变量,即初始对象超出范围并被垃圾回收。弱引用不会干扰此过程。如果解析弱引用,它将指向
None而不是原始对象。
In[5]: ref()Out[5]: None这样确保我们不会保留任何可能被垃圾回收的数组。
让我们来看看这些对象是如何组织的:
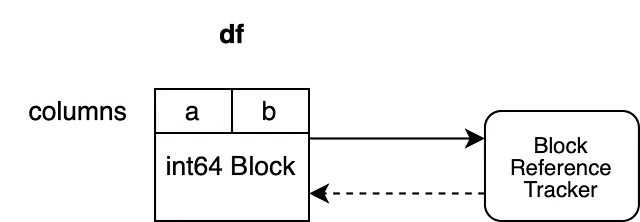
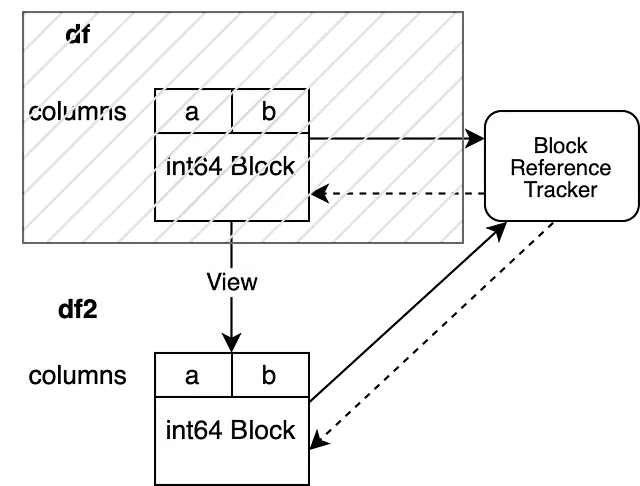
我们的示例有两列 "a" 和 "b",它们的数据类型都是 "int64"。它们由一个 Block 支持,该 Block 保存了两列的数据。该 Block 对引用跟踪对象保持了强引用,确保该对象在 Block 不被垃圾回收时保持存在。引用跟踪对象对 Block 保持了弱引用。这使得对象能够跟踪该 Block 的生命周期,但不会阻止垃圾回收。引用跟踪对象目前没有对任何其他 Block 保持弱引用。
这些是简单的情况。我们知道没有其他 pandas 对象共享相同的 NumPy 数组,因此我们可以简单地实例化一个新的引用跟踪对象。
第三种情况更复杂。新对象查看与原始对象相同的数据。这意味着两个对象都指向同一块内存。我们的操作将创建一个引用相同 NumPy 数组的新 Block,这称为浅拷贝。现在,我们必须将这个新的 Block 在我们的引用跟踪机制中注册。我们将我们的新 Block 注册到与旧对象连接的引用跟踪对象中。
df2 = df.reset_index(drop=True)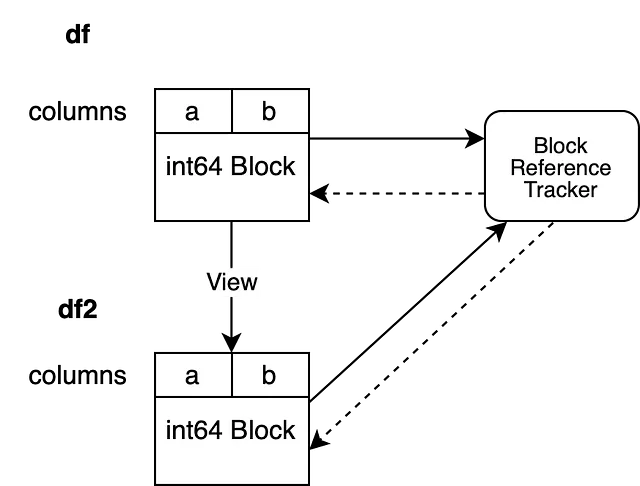
我们的 BlockValuesRefs 现在指向支持初始 df 的 Block 和支持 df2 的新 Block。这确保我们始终知道指向相同内存的所有 DataFrame。
现在,我们可以询问引用跟踪对象有多少个指向相同 NumPy 数组的 Block 是活动的。引用跟踪对象评估弱引用并告诉我们有多个对象引用相同数据。这使我们能够在其中一个对象被原地修改时触发内部复制。
df2.iloc[0, 0] = 100df2 中的 Block 通过深拷贝进行复制,创建一个具有自己的数据和引用跟踪对象的新 Block。现在可以对支持 df2 的原始 Block 进行垃圾回收,以确保支持 df 和 df2 的数组不共享任何内存。
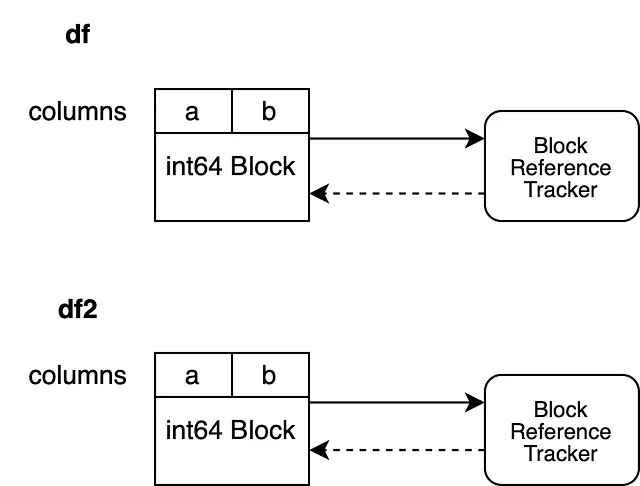
让我们看一个不同的情况。
df = None
df2.iloc[0, 0] = 100在修改 df2 之前,使 df 无效。因此,指向支持 df 的 Block 的引用跟踪对象的弱引用评估为 None。这使我们能够在不触发复制的情况下修改 df2。
我们的引用跟踪对象只指向一个 DataFrame,这使我们能够在不触发复制的情况下进行原地操作。
reset_index 上面创建了一个视图。如果我们有一个触发内部复制的操作,机制会更简单一些。
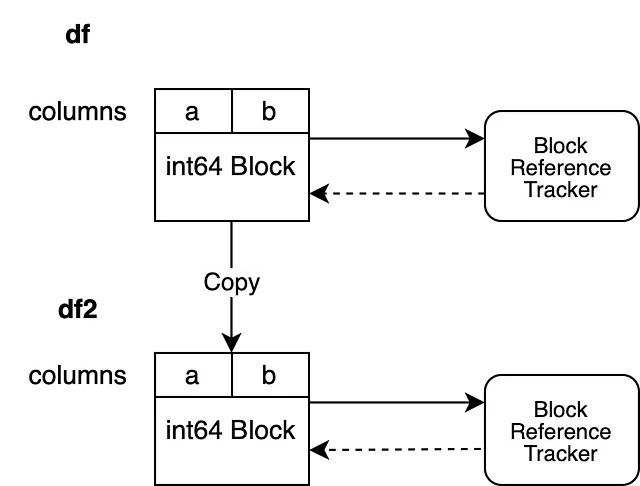
df2 = df.copy()这将立即为我们的 DataFrame df2 实例化一个新的引用跟踪对象。
结论
我们已经研究了Copy-on-Write跟踪机制的工作原理和触发复制的时机。该机制尽可能地推迟在pandas中进行复制,这与非CoW行为非常不同。引用跟踪机制跟踪所有共享内存的DataFrame,使得pandas的行为更加一致。
本系列的下一部分将解释用于使该机制更高效的技术。
感谢阅读。欢迎分享您对Copy-on-Write的想法和反馈。