为什么以及什么是机器学习中的特征工程?
机器学习中的特征工程是什么?为什么重要?
数据转换和选择用于机器学习
介绍
这是一个特征转换和选择或提取的过程,为机器学习模型生成改进的数据。这取决于数据科学家处理和改进数据以获得良好的模型。不同的人可以有不同的方法,但几乎每个人都会经历特征工程技术。在本文中,我们将讨论特征工程的不同技术。
特征工程包括四个部分:
- 特征转换
- 特征构建
- 特征选择
- 特征提取
本文的第一部分将讨论特征转换及其不同的技术。
特征转换
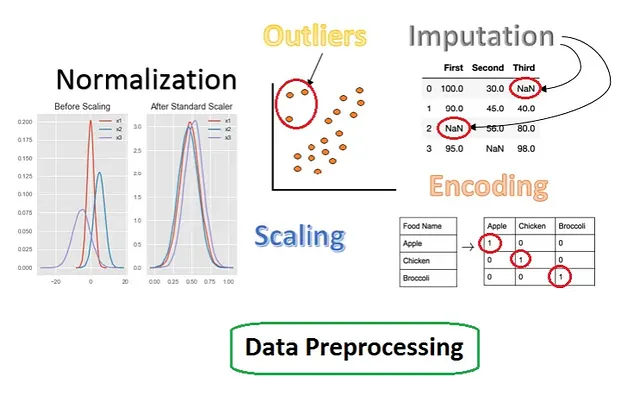
这些方法和技术是在将数据提供给模型之前进行数据预处理的最常用方法。这些过程包括缺失数据插补、缩放、编码、异常值检测等。
缩放:
当数据数字存在变化时,使用此方法。假设在一个输入列中,值非常低,而在另一个输入列中,值非常高,那么模型可能会偏离良好的性能。较大值的列在模型学习中占主导地位,模型将对其他特征给予较低的重要性。
要点:
- 在进行训练集和测试集划分后进行缩放是可取的。
- 如果在其他转换之后进行缩放,可能会获得更好的模型性能。
缩放的类型:
- 标准化:
- 在这种类型的缩放中,值被压缩到均值和标准差。新转换的数据点的均值为零,标准差为一。
- 当我们在sklearn中使用scalar库时,它会返回一个新转换列的numpy数组,但我们需要将它们放入数据框中。
- 在不知道应该应用哪个模型时使用。