揭示神经魔法:深入理解激活函数
神经魔法:激活函数深入理解

为什么使用激活函数
深度学习和神经网络由相互连接的节点组成,数据按顺序通过每个隐藏层传递。然而,线性函数的组合仍然是一个线性函数。当我们需要学习数据中的复杂和非线性模式时,激活函数变得重要。
- 来自埃因霍温和西北大学的研究人员开发了一种新的神经形态生物传感器,能够进行芯片内学习,无需外部训练
- “放大看不见的:这种人工智能AI方法使用NeRFs来可视化3D中的微妙动作”
- 以数据为先导:与Anand S.一起讲述故事的艺术
使用激活函数的两个主要好处是:
引入非线性
线性关系在现实世界的情况下很少见。大多数现实世界的情况都很复杂,遵循各种不同的趋势。使用线性算法(如线性回归和逻辑回归)无法学习这样的模式。激活函数为模型添加非线性,使其能够学习数据中的复杂模式和变化。这使得深度学习模型能够执行包括图像和语言领域在内的复杂任务。
允许深度神经网络层
如上所述,当我们顺序应用多个线性函数时,输出仍然是输入的线性组合。在每个层之间引入非线性函数使它们能够学习输入数据的不同特征。没有激活函数,拥有深度连接的神经网络架构将与使用基本的线性或逻辑回归算法相同。
激活函数允许深度学习架构学习复杂模式,使其比简单的机器学习算法更强大。
让我们来看一些在深度学习中常用的激活函数。
Sigmoid
在二分类任务中常用的Sigmoid函数将实数值映射到0到1的范围内。
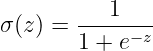
上述方程如下:
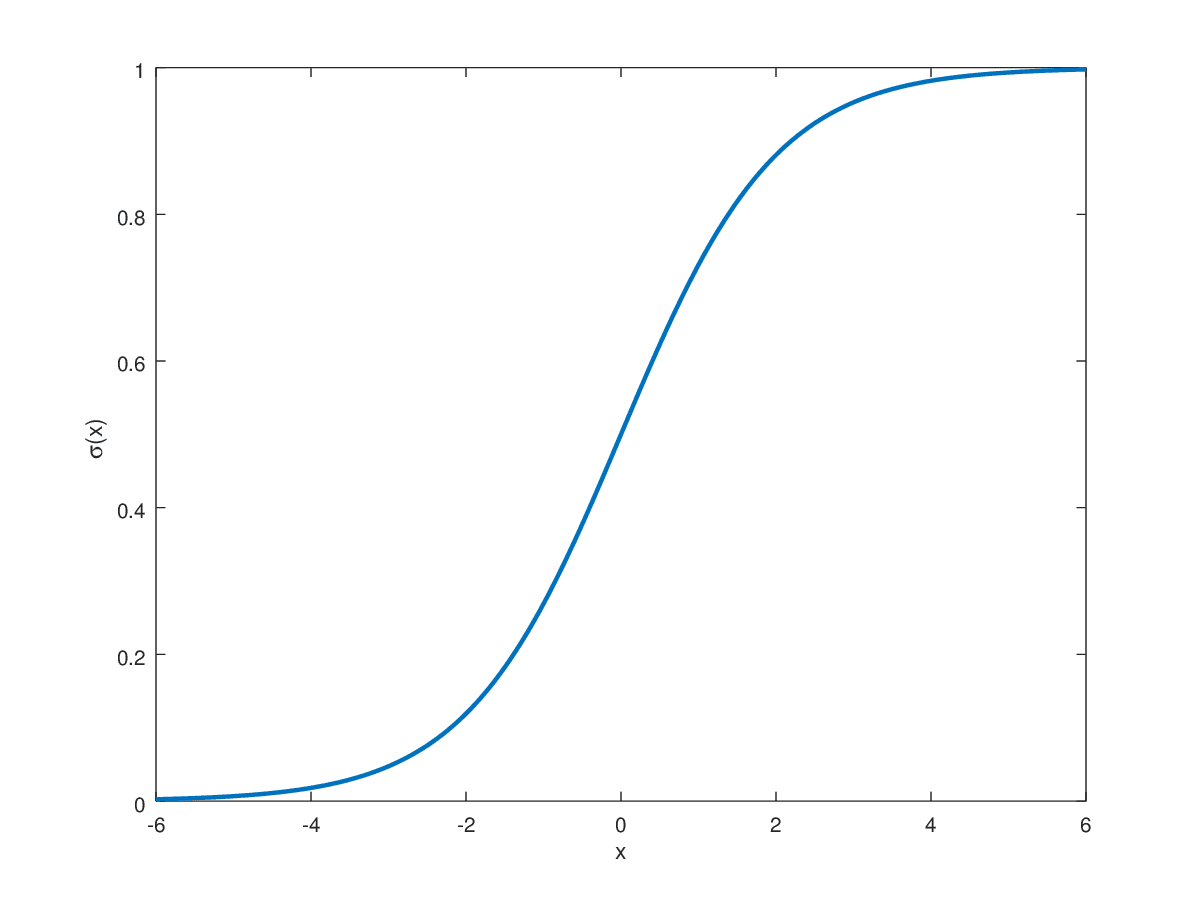
Sigmoid函数主要用于输出层的二分类任务,其中目标标签为0或1。这自然使得Sigmoid在这类任务中更受青睐,因为输出限制在此范围内。对于接近正无穷大的正值,Sigmoid函数将其映射到接近1。在相反的情况下,它将接近负无穷大的值映射为0。这些之间的所有实数都以S形趋势映射在0到1的范围内。
缺点
饱和点
Sigmoid函数在反向传播算法中对梯度下降算法造成问题。除了接近S形曲线中心的值,梯度非常接近于零,导致训练问题。接近渐近线时,它可能导致梯度消失的问题,因为小的梯度可以显着减慢收敛速度。
非零中心
经实验证明,具有零中心的非线性函数可以确保均值激活值接近0。具有这种标准化值可以确保梯度下降更快地收敛到极小值。虽然不是必需的,但具有零中心的激活函数可以加快训练速度。当输入为0时,Sigmoid函数在0.5处为中心。这是在隐藏层使用Sigmoid的缺点之一。
Tanh
双曲正切函数是对Sigmoid函数的改进。Tanh函数将实数值映射到-1到1之间。
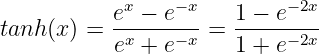
Tanh函数如下:
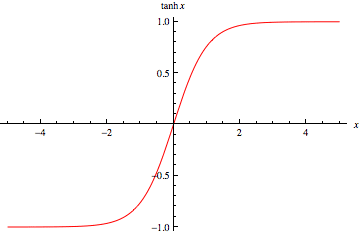
双曲正切函数(TanH)与Sigmoid函数遵循相同的S形曲线,但它现在是以零为中心的。这使得在训练过程中收敛更快,改进了Sigmoid函数的一个缺点。这使得它更适用于神经网络架构中的隐藏层。
缺点
饱和点
双曲正切函数(TanH)与Sigmoid函数遵循相同的S形曲线,但它现在是以零为中心的。这使得在训练过程中收敛更快,改进了Sigmoid函数。这使得它更适用于神经网络架构中的隐藏层。
计算开销
尽管在现代环境中不是一个主要问题,但与其他常见的替代方法相比,指数计算的开销更大。
ReLU
在实践中最常用的激活函数是修正线性单元激活(ReLU),它是最简单但也是最有效的非线性函数。
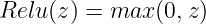
它保留所有非负值,并将所有负值固定为0。可视化,ReLU函数如下:
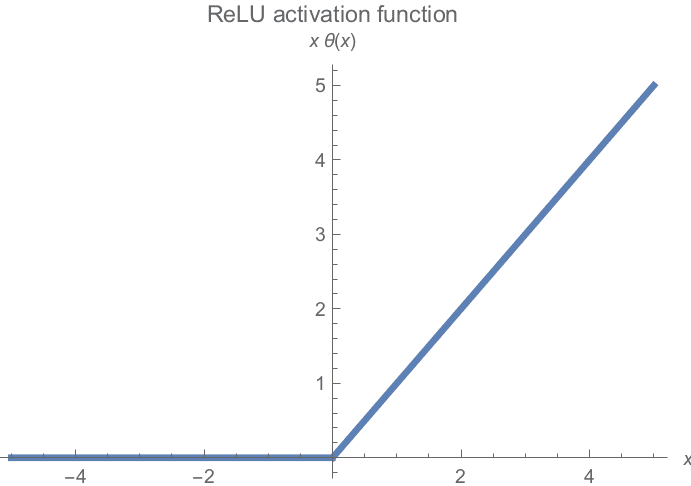
缺点
ReLU失效
梯度在图的一端变得平坦。所有负值的梯度为零,因此有一半的神经元可能对训练的贡献很小。
无限激活
在图的右侧,梯度没有上限。如果梯度值过高,这可能导致梯度爆炸问题。这个问题通常通过梯度剪裁和权重初始化技术来修正。
非零中心化
与Sigmoid类似,ReLU激活函数也不是以零为中心的。同样,这会导致收敛问题并减慢训练速度。
尽管存在所有这些缺点,它是神经网络架构中所有隐藏层的默认选择,并且在实践中被证明非常高效。
要点
现在我们知道了三个最常用的激活函数,那么我们如何确定对于我们的情况来说最好的选择是什么?
尽管这高度依赖于数据分布和具体问题陈述,但在实践中仍然有一些基本的起点。
- Sigmoid仅适用于二元问题的输出激活,当目标标签为0或1时。
- Tanh现在主要被ReLU和类似函数取代。然而,在RNN的隐藏层中仍然使用它。
- 在所有其他情况下,ReLU是深度学习架构中隐藏层的默认选择。
Muhammad Arham是一名从事计算机视觉和自然语言处理的深度学习工程师。他曾参与部署和优化多个生成型人工智能应用,这些应用在Vyro.AI的全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型感兴趣,并坚信不断改进。





