数据科学中的统计学:理论与概述
数据科学中的统计学

你有兴趣掌握统计学知识以在数据科学面试中脱颖而出吗?如果是的话,你不应该只为了面试而学习。理解统计学可以帮助你从数据中获得更深入、更精细的洞察。
在这篇文章中,我将展示解决数据科学问题所需了解的关键统计概念。
- 如何减轻细粒度图像分类中的背景引起的偏差?屏蔽策略和模型架构的比较研究
- 变分转换器用于音乐创作:AI能取代音乐家吗?
- 谷歌研究员提出了MEMORY-VQ:一种新的人工智能方法,可以减少存储要求,而不会牺牲存储增强模型的性能
统计学简介
当你想到统计学时,你的第一个想法是什么?你可能会想到以数字形式表示的信息,如频率、百分比和平均值。通过观看电视新闻和报纸,你已经看到了世界各地的通胀数据、你所在国家的就业和失业人数、街头致命事件的数据以及一项调查中各个政党的投票百分比等数据。所有这些例子都是统计数据。
这些统计数据的制作是一个被称为统计学的学科的最明显的应用。统计学是一门关于开发和研究收集、解释和呈现经验数据方法的科学。此外,你可以将统计学领域分为两个不同的部分:描述统计和推断统计。
年度普查、频率分布、图表和数值总结是描述统计的一部分。对于推断统计,我们指的是一组允许基于样本(被称为样本)推广结果的方法。
在数据科学项目中,我们大部分时间都在处理样本。因此,我们用机器学习模型获得的结果是近似的。一个模型在特定样本上可能工作得很好,但这并不意味着它在新样本上表现良好。一切取决于我们的训练样本,它需要具有代表性,以很好地概括人口的特征。
图表和数值总结的探索性数据分析(EDA)
在数据科学项目中,探索性数据分析是最重要的步骤,它使我们能够通过摘要统计和图形表示对数据进行初步调查。它还允许我们发现模式、发现异常并检查假设。此外,它有助于发现数据中可能存在的错误。
在EDA中,关注的重点是变量,可以分为两种类型:
- 数值型,如果变量是以数字刻度进行测量的。它可以进一步分为离散型和连续型。当存在不同的数量时,它是离散型的。离散变量的例子包括学位成绩和家庭人数。当我们处理连续变量时,可能值的集合在有限或无限区间内,例如身高、体重和年龄。
- 分类型,如果变量通常由两个或多个类别组成,如职业状态(就业、失业和正在寻找工作的人)和工作类型。与数值变量一样,分类变量可以分为两种不同类型:有序和名义。当类别之间存在自然顺序时,变量是有序的。一个例子是具有低、中、高等级的薪水。当分类变量没有任何顺序时,它是名义的。名义变量的一个简单例子是性别,包括女性和男性。
单变量数据的探索性数据分析(EDA)
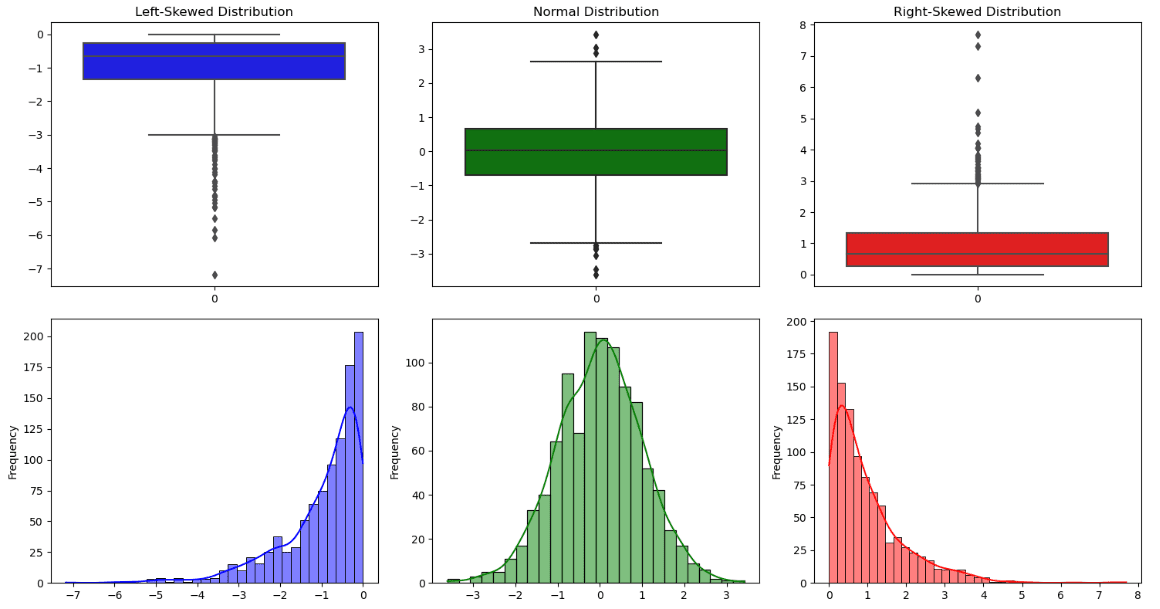
为了理解数值特征,我们通常使用df.describe()来获得每个变量的统计概览。输出包括计数、平均值、标准差、最小值、最大值、中位数、第一和第三四分位数。
所有这些信息也可以通过一个称为箱线图的图形表示来查看。箱子中间的线是中位数,而下边缘和上边缘分别对应第一和第三四分位数。除了箱子提供的信息之外,还有两条线,也称为须,表示分布的两个尾巴。所有超出须界限的数据点都是异常值。
从这个图可以观察到分布是对称的还是不对称的:
- 当分布呈钟形,中位数与均值大致相等,须与相同长度时,该分布是对称的。
- 当中位数接近第三四分位数时,该分布是右偏的(正偏)。
- 当中位数接近第一四分位数时,该分布是左偏的(负偏)。
从直方图中可以看到分布的其他重要方面,它计算了每个区间中有多少数据点。可以注意到四种形状:
- 一个峰/模式
- 两个峰/模式
- 三个或更多峰/模式
- 均匀分布,没有明显的模式
当变量是分类变量时,最好的方法是观察每个要素的频率表。为了更直观的可视化,我们可以使用条形图,根据变量的不同选择垂直或水平的条形。
双变量数据的探索性数据分析
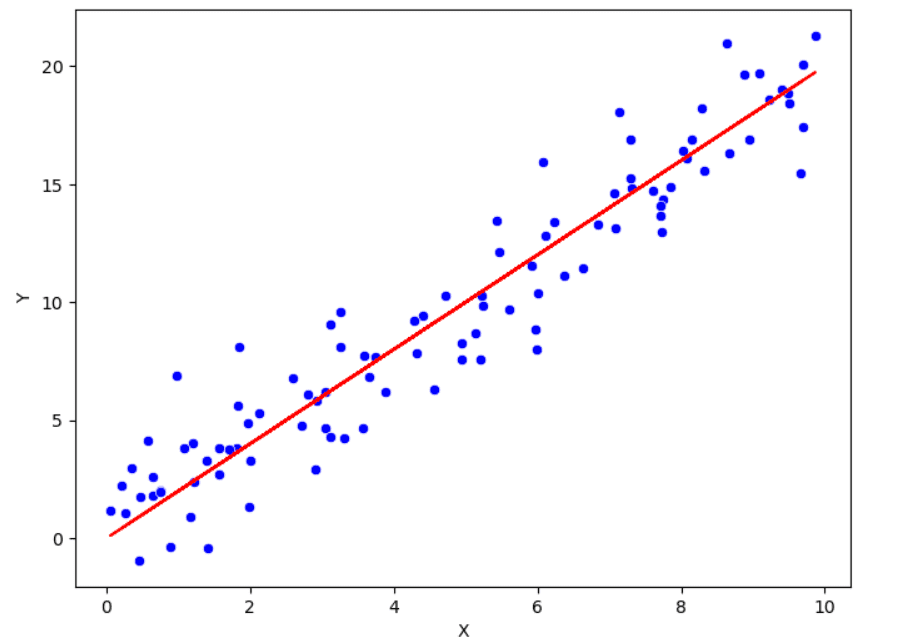
之前我们列举了了解单变量分布的方法。现在,是时候研究变量之间的关系了。为此,通常会计算皮尔逊相关系数,它是两个变量之间线性关系的度量。此相关系数的范围在-1和1之间。如果相关系数的值接近这两个极端之一,关系就越强。如果接近0,则两个变量之间关系较弱。
除了相关性,还有散点图可以可视化两个变量之间的关系。在这种图形表示中,每个点对应一个特定的观察值。当数据内部变异性很大时,它通常不太信息丰富。为了从变量对中获取更多信息,可以添加平滑线并对数据进行转换。
概率分布
概率分布的知识在处理数据时起到关键作用。
以下是数据科学中最常用的概率分布:
- 正态分布
- 卡方分布
- 均匀分布
- 泊松分布
- 指数分布
正态分布
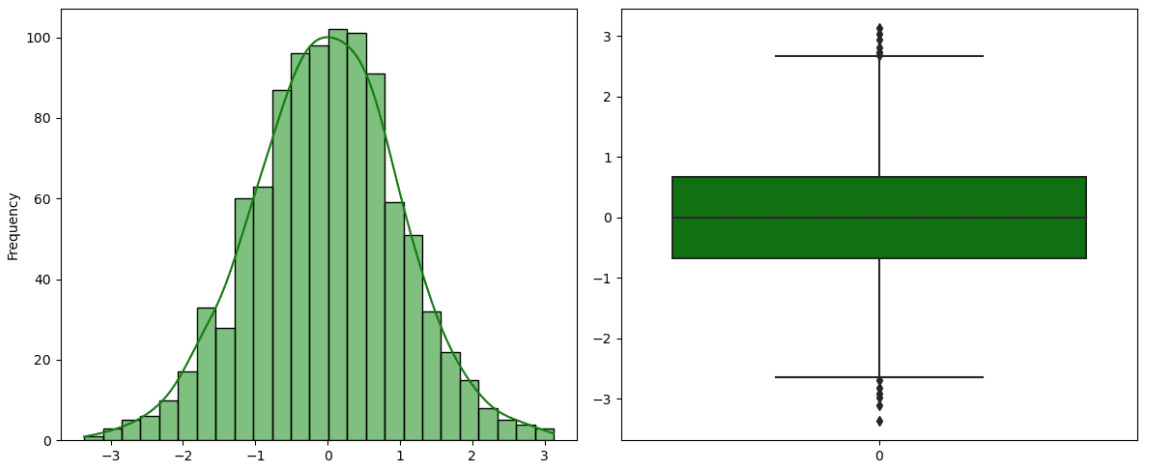
正态分布,也称为高斯分布,是统计学中最常见的分布。它的特点是呈钟形曲线,中间较高,两端逐渐变低。它是对称的,单峰的,有一个峰值。此外,正态分布有两个关键参数:均值和标准差。均值与峰值相等,曲线的宽度由标准差表示。还有一种特殊类型的正态分布,称为标准正态分布,均值为0,方差为1。它是通过从原始值中减去均值,然后除以标准差得到的。
t分布
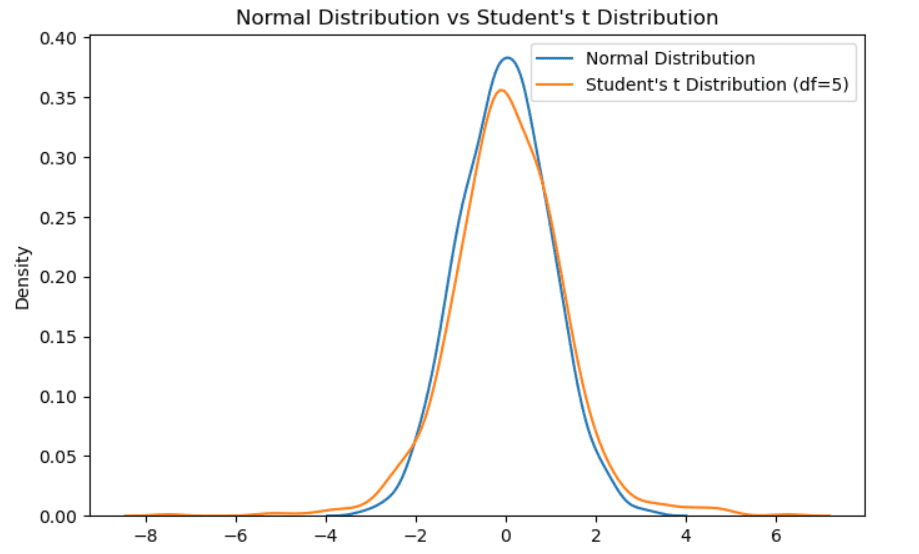
它也被称为具有v个自由度的t分布。与标准正态分布一样,它以零为中心对称。它与高斯分布略有不同,因为中间部分的概率质量较少,尾部的概率质量较多。当样本量较小时,会使用t分布。样本量增加时,t分布将趋于正态分布。
卡方分布
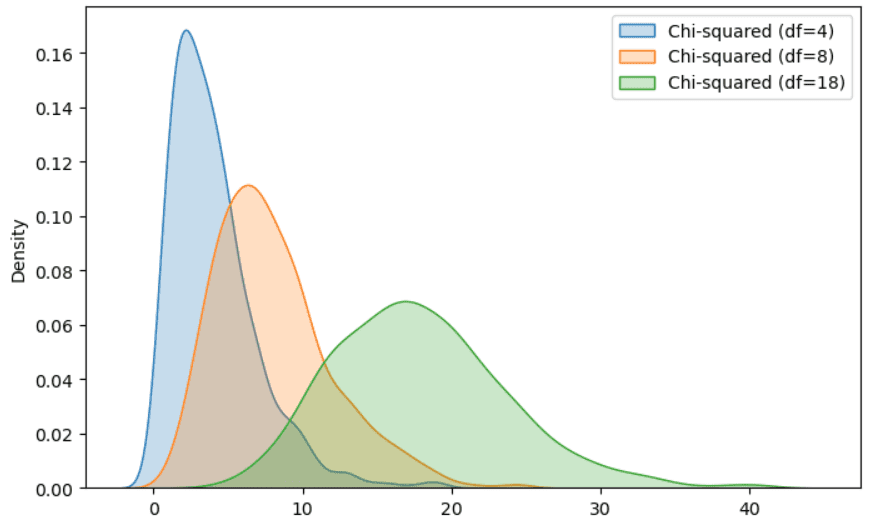
这是Gamma分布的特殊情况,非常适用于假设检验和置信区间的应用。如果我们有一组正态分布且独立的随机变量,我们对每个随机变量计算平方值,并将每个平方值相加,最终的随机值遵循卡方分布。
均匀分布
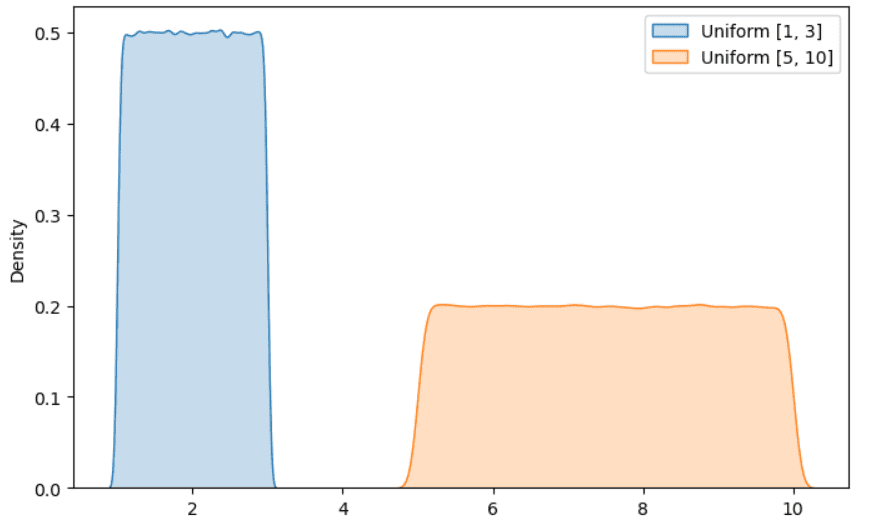
<p这是另一种在数据科学项目中经常遇到的流行分布。其思想是所有结果发生的概率相等。一个常见的例子是掷一个六面骰子。你可能知道,骰子的每个面出现的概率相等,因此结果遵循均匀分布。
泊松分布
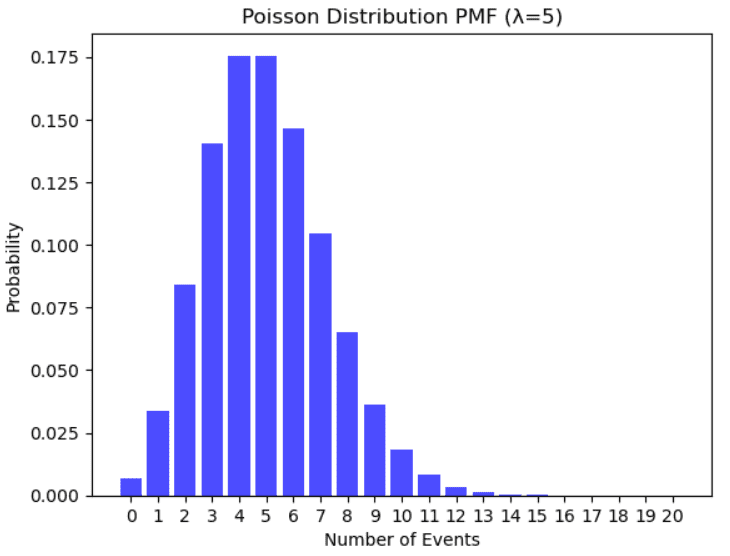 泊松分布的例子。作者插图。
泊松分布的例子。作者插图。
它用于模拟在特定时间间隔内随机发生的事件数量。遵循泊松分布的例子包括一个社区中年龄超过100岁的人数,系统每天的故障次数,以及在特定时间范围内到达求助热线的电话数量。
指数分布
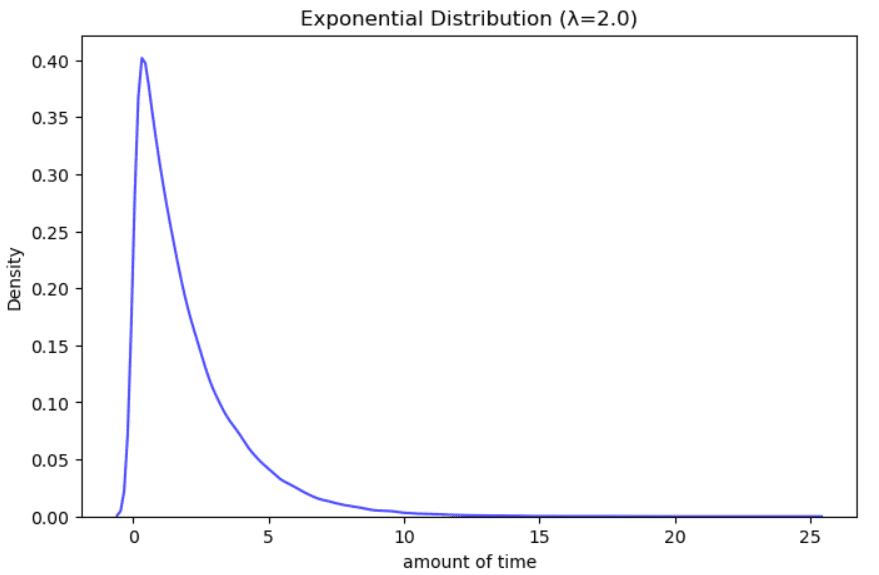 指数分布的例子。作者插图。
指数分布的例子。作者插图。
它用于模拟在特定时间间隔内随机发生的事件之间的时间间隔。例子包括求助热线等待时间,下一次地震的时间,癌症患者剩余的生命年限。
假设检验
假设检验是一种统计方法,允许根据样本数据对总体假设进行制定和评估。因此,它是一种推断统计学的形式。该过程从总体参数的假设开始,也称为原假设,需要进行测试,而备择假设(H1)代表相反的陈述。如果数据与我们的假设非常不同,则拒绝原假设(H0),并且结果被认为是“统计显著的”。
一旦确定了两个假设,还有其他步骤要遵循:
- 设置显著水平,这是用于拒绝原假设的标准。典型的值为0.05和0.01。该参数 ? 决定了经验证据对原假设的反驳力度,直到拒绝原假设。
- 计算统计量,即从样本计算得出的数值量。它帮助我们确定决策规则,以尽可能地限制错误风险。
- 计算p值,即获得与在原假设中指定的参数不同的统计量的概率。如果它小于或等于显著水平(例如:0.05),我们拒绝原假设。如果p值大于显著水平,则无法拒绝原假设。
有各种各样的假设检验。假设我们正在进行一个数据科学项目,并且我们想要使用线性回归模型,该模型以正态性、独立性和线性性的强假设而闻名。在应用统计模型之前,我们更喜欢检查与糖尿病成年女性体重相关的特征的正态性。Shapiro-Wilk检验可以提供帮助。还有一个名为Scipy的Python库,其中包含此检验的实现,其中的原假设是变量服从正态分布。如果p值小于或等于显著水平(例如:0.05),我们拒绝假设。如果p值大于显著水平,我们可以接受原假设,这意味着变量具有正态分布。
最后的想法
希望你觉得这个介绍有用。我认为,如果理论与实际示例相结合,掌握统计学是可能的。当然还有其他重要的统计概念我在这里没有涵盖,但我更愿意关注那些在我作为数据科学家的经验中发现有用的概念。你知道其他对你工作有帮助的统计方法吗?如果你有有见地的建议,请在评论中留言。
资源:
- HyperStat在线统计教材
- 位置测量
- 数据科学中最常用的概率分布
Eugenia Anello 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在连续学习与异常检测的结合上。






