数据科学中的库存优化:使用Python的实践教程
数据科学中的库存优化:Python实践教程
第一部分:实现马可夫过程进行库存优化的简介。

简介
库存优化就像解决一个棘手的谜题。作为一个广泛的问题,它在许多领域中出现,它的核心是找出为您的商店订购多少产品。
想象一下一个自行车店主为销售订购新自行车的情况。但这里存在一个棘手的情况。如果她为商店订购太多的自行车,她将在维护和存储自行车方面花费太多。另一方面,如果她订购的自行车较少,她可能没有足够的自行车满足顾客的需求,这将导致利润和声誉的损失。
她需要的是一个能帮助她在每天做出最佳决策的最优“策略”,以确保她的库存长期获得利润。
因此,在解决这个问题的背景下,具有编程、数据和建模知识的数据科学家可以在找出这个最佳“策略”方面发挥重要作用。然而,为了达到这个目标(回答这个问题),我们需要一些基础知识。我们需要对以下内容有基本的了解:
- 马可夫过程,
- 马可夫奖励过程
- 和马可夫决策过程。
- 最后,我们将结合这三个概念,并将其与
- 动态规划和
- 强化学习
来达到我之前提到的最优“策略”。本博客旨在了解和建模Python中的“马可夫过程”,这将是下一步的基础。
库存优化:现成的机器学习模型能解决吗?
老实说,我写这篇博客是因为我对在线资源上的库存优化建模和解决方式感到沮丧。在我的博士学位中,我不得不处理库存优化问题(因为我的课题是顺序决策)。我进行了一些研究,阅读了一些论文和书籍,能够找到正确的建模方法来“一致地”解决它。
关键是,“库存优化”类型的问题是动态问题,当你处于什么状态(库存情况)时,你需要适应这种情况并拥有一种自适应策略。
库存优化不是一个可以用静态分析方法解决的静态问题,也不能使用现成的机器学习/深度学习模型来解决。它是一个动态过程,其中必须理解和建模其组成部分,使您能够动态地调整每天的决策。
马可夫过程
如果你是一个分析专业人士(无论是数据科学家、分析师等),你经常会处理时间索引的过程,并且遵循不确定的路径。想象一下一个在能源公司工作的数据科学家。她的任务是跟踪商品价格的不确定路径。
商品价格(例如石油)将在时间步长t=0,1,2,⋯上遵循一条路径。这是一个不确定的过程,被时间索引。然而,如果我们想进行分析,我们需要内部表示这个过程。
状态
将状态视为内部表示不确定过程的工具。让我们回到石油价格的例子。假设今天的石油价格是100美元。我可以用S_0=100来表示这个信息,然后明天的价格将不同,可以表示为S_1,这个序列继续S_0,S_1,S_2。这个过程是一个随机状态的序列St∈S,如在时间t=0,1,2,3,.. — 我们可以用以下方式表示这个过程:
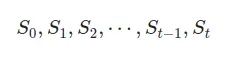
马尔可夫性质
在这篇简短的博客中,我想谈谈马尔可夫过程。我们称这个过程(马尔可夫性质)如果它的状态转移具有以下性质:
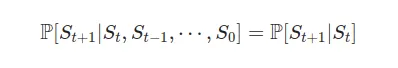
这个方程在简单的术语中是什么意思?
我们可以考虑一个天气的简单例子。假设一天可以有三种可能的天气情况:“晴天”,“下雨”和“下雪”。那么,如果今天是“晴天”,
- 明天也有70%的可能是“晴天”,
- 明天有20%的可能天气会转变成“下雨”,
- 明天有10%的可能天气会是“下雪”。
在这个天气例子中,我们可以看到明天天气状况的概率“只”取决于“今天”,所以天气状况的历史“无关紧要”。只要今天的天气是晴天(St=“晴天”),明天天气是晴天的概率为P(S_{t+1}=“晴天”)=0.7,P(S_{t+1}=“下雨”)=0.2和P(S_{t+1}=“下雪”)=0.1。
让我们通过一个简单的实际例子更好地理解马尔可夫过程。这个例子是关于管理自行车店的库存,并将进行一些实际的Python编码。
自行车店库存管理的简单例子
回到自行车店的例子:想象一下,你拥有一家自行车店,库存只能容纳一定数量的自行车(有限容量)。例如,假设你的店最多能容纳5辆自行车。
每天都有一些顾客来你的店里购买自行车。假设今天(周三),你的店里有三辆自行车。然而,你也知道明天(周四)你的店里会有一些需求,也就是说你的自行车将被销售。你不确定明天会有多少顾客,也就是明天对自行车的需求是不确定的。我们需要更准确地建模这个过程,建模库存的状态如何变化和演变。¹
问题描述
在这篇博客中,我们的主要关注点是马尔可夫过程。这意味着在这篇博客中,我们将有一个(假设)固定的策略(在这种情况下,策略是每天订购多少辆自行车)。为了对这个例子的马尔可夫过程建模,首先我们需要确定这个问题的框架(什么是状态?)。其次,我们需要建立状态转移模型。
状态(过程的内部表示)可以由两个组成部分描述:
- α:你店里已经有的自行车数量
- β:你前一天订购的自行车数量,明天早上将到货(这些自行车在卡车上)
24小时周期的序列
这家自行车店在24小时周期内的事件序列如下:
- 下午6点:观察到状态S_t:(α,β)
- 下午6点:订购新自行车,数量等于max(C−(α+β),0)
- 上午6点:收到36小时前订购的自行车
- 上午8点:开店
- 从上午8点到下午6点:一天内经历需求i(使用泊松分布进行建模)详见以下内容。
- 下午6点:关店
下面的图表可视化了这个序列:

与上面的解释类似,St=(αt+βt)是这个随机过程的内部表示,在马尔可夫过程中,我们希望模拟这个随机过程的演化。
一个演示24小时库存序列的例子。
我来举个例子。假设大卫是一家自行车店的店主。在一个星期三(下午6点),他的店内有2辆自行车,他在周一下午6点订购了一辆自行车。他的状态将是:
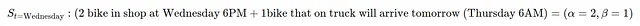
所以星期三晚上8点的状态是S=(α=2,β=1)。然后,每天都有一个随机(非负整数)的自行车需求,需求的模型是泊松分布(泊松参数λ∈R>)。每个i=0,1,2⋯的需求以概率出现:
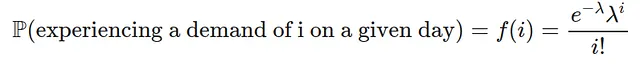
我们可以通过可视化这个分布来看到在选择λ=2时经历不同需求的概率
# import matplotlib and some desired stylingimport matplotlib.pyplot as plt%matplotlib inlineplt.style.use("ggplot")plt.rcParams["figure.figsize"] = [10, 6]# need numpy to do some numeric calculationimport numpy as np# poisson is used to find pdf of Poisson distribution from scipy.stats import poisson
x_values = np.arange(0,10)# pdf Poisson distri with lambda = 1pdf_x_values = poisson.pmf(k=x_values,mu=2)plt.bar(x_values, pdf_x_values, edgecolor='black')plt.xticks(np.arange(0, 10, step=1))plt.xlabel("顾客需求")plt.ylabel("顾客需求的概率")plt.title("顾客需求的概率分布,$\lambda = 1$ ")plt.savefig("fig/poisson_lambda_2.png", dpi=300)plt.show()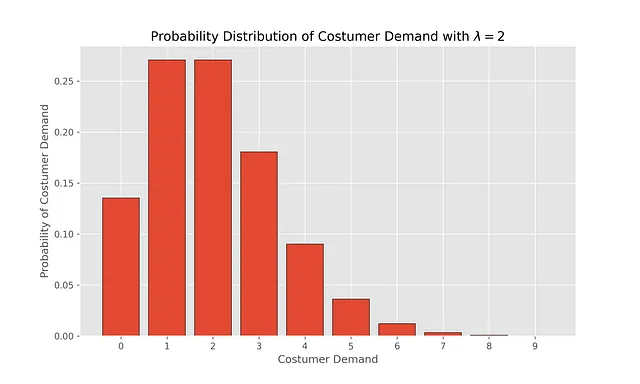
构建马尔可夫过程的概率转移:
现在我们已经初步了解了状态St=(α,β)是什么,引入了随机过程的不确定性是顾客需求(i)。我们可以进一步探讨这个问题中概率转移的演化。我将为此编写代码,但首先,让我们以更简单的方式解释一下。
这个问题的概率转移有两种情况,第一种和第二种。
- 情况1)
如果需求i小于当天可用的总库存,初始库存=α+β
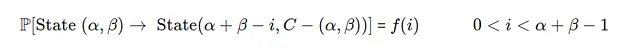
- 情况2)
如果需求i大于当天可用的总库存,初始库存=α+β
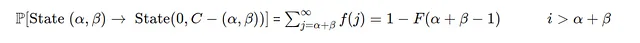
其中F(α+β−1)是泊松分布的CDF。
了解了这个问题的背景之后,我们现在可以编写一些Python代码来更好地理解它。这个Python代码的关键是设计用于存储马尔可夫过程转换的数据结构。为了做到这一点,我将数据结构设计为一个称为“MarkovProcessDict”的字典。这个字典的键对应当前状态,值(用字典表示)是下一个状态,以及与每个下一个状态相关联的概率。这是一个数据结构MarkovProcessDict的示例:
from typing import DictMarkovProcessDict = {"当前状态A":{"从A到下一个状态1": "从A到下一个状态1的概率", "从A到下一个状态2": "从A到下一个状态2的概率"}, "当前状态B":{"从B到下一个状态1": "从B到下一个状态1的概率", "从B到下一个状态2": "从B到下一个状态2的概率" }}MarkovProcessDict
让我们解读一下数据结构MarkovProcessDict的含义。例如,初始状态是“当前状态A”,可以转到两个新的状态:
- 1) “从A到下一个状态1”,概率为“从A到下一个状态1的概率“
- 2) “从A到下一个状态2”,概率为“从A到下一个状态2的概率”。
实际编码
让我们编写代码来构建我们的MarkovProcessDict数据结构,给出了前面解释的这个过程的两种不同情况。
MarkovProcessDict: Dict[tuple, Dict[tuple, float]] = {}user_capacity = 2user_poisson_lambda = 2.0
# 我们考虑在运行这个自行车店时可能遇到的所有可能状态for alpha in range(user_capacity+1): for beta in range(user_capacity + 1 - alpha): # 这是当前状态St state = (alpha, beta) # 这是初始库存,早上8点你拥有的自行车总数 initial_inventory = alpha + beta # beta1是下一个状态中的beta,与当前状态无关(因为决策策略是固定的) beta1 = user_capacity - initial_inventory # 所有可能需求的列表 for i in range(initial_inventory +1): # 如果初始需求能满足需求 if i <= (initial_inventory-1): # 特定需求发生的概率 transition_prob = poisson.pmf(i,user_poisson_lambda) # 如果我们已经在我们的数据中定义了该状态(MarkovProcessDict) if state in MarkovProcessDict: MarkovProcessDict[state][(initial_inventory - i, beta1)]= transition_prob else: MarkovProcessDict[state] = {(initial_inventory - i, beta1):transition_prob } # 如果初始需求无法满足需求 else: # 不满足需求的概率 transition_prob = 1- poisson.cdf(initial_inventory -1, user_poisson_lambda) if state in MarkovProcessDict: MarkovProcessDict[state][(0, beta1)]= transition_prob else: MarkovProcessDict[state] = {(0, beta1 ):transition_prob }在上面的代码中,for循环遍历所有可能的状态组合,并且每个状态(St)以“transition_prob”的概率移动到下一个状态(S_{t+1})。我们可以使用以下代码打印系统的动态:
or (state, value) in MarkovProcessDict.items(): print("当前状态是:{}".format(state)) for (next_state, trans_prob) in value.items(): print("下一个状态是{},概率为{:.2f}".format(next_state, trans_prob))
可视化最终数据结构
了解这些动态的一种方法是使用graphviz Python包,其中每个节点表示当前状态,边显示从该状态移动到另一个状态的概率。
# 导入包
import graphviz
# 定义graphviz Diagraph的初始结构,颜色为浅蓝色、填充样式
d = graphviz.Digraph(node_attr={'color': 'lightblue2', 'style': 'filled'})
d.attr(size='10,10')
d.attr(layout = "circo")
for s, v in MarkovProcessDict.items():
for s1, p in v.items():
# 用s[0]和s[1]表示alpha和beta
d.edge("(\u03B1={}, \u03B2={})".format(s[0],s[1]),
"(\u03B1={}, \u03B2={})".format(s1[0],s1[1]), label=str(round(p,2)), color="red")
print(d)
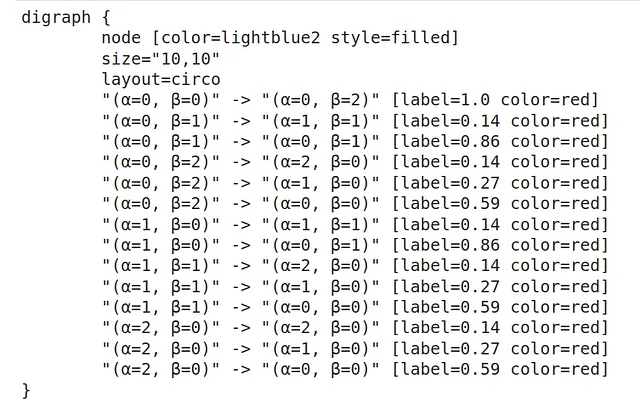
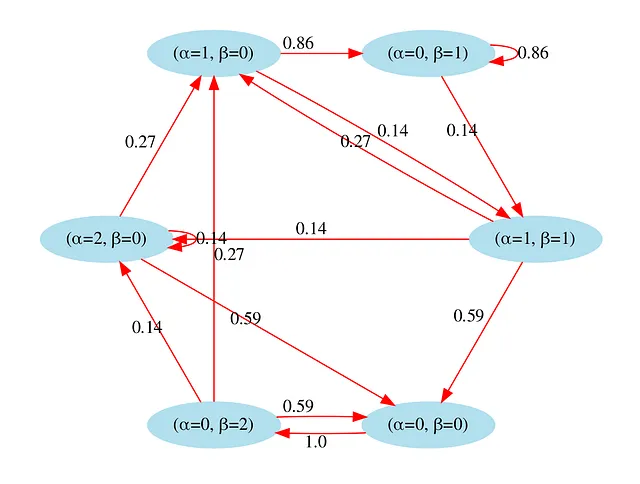
在下面的图表中,我可视化了这个转换的图形。例如,如果我们处于状态St = (α=1,β=0)(左上角的圆圈),则下一个状态有86%的概率是S(t+1):(α=0,β=1),14%的概率是S(t+1):(α=1,β=1)。
最后说明
- 库存优化不是一个静态优化问题,而是需要适应性策略来在每个时间阶段根据不确定性做出最佳决策的顺序决策过程。
- 在这篇博客中,我尝试构建了一个数学模型,用于跟踪库存过程(使用状态和马尔可夫过程),并通过实际的Python编码来可视化过程的动态。
- 这篇博客奠定了处理库存优化问题的基础,下一步我们将研究马尔可夫奖励和马尔可夫决策过程。
[1] 您可以在“基于强化学习的金融应用基础”中更深入地阅读这个例子。但是,我在这篇博客中重新编写了Python代码,以使其更容易理解。
感谢您的阅读!
希望本文提供了一个易于理解的教程,介绍如何使用Python进行库存优化。
如果您认为本文帮助您更多地了解库存优化和马尔可夫过程,请点赞并关注!





