通过从数万亿个标记中检索来改进语言模型
改进语言模型通过检索数万亿个标记来实现
近年来,在Transformer模型中增加参数数量取得了显著的自回归语言建模性能提升。这导致训练能源成本大幅增加,并产生了具有1000多亿参数的密集“大型语言模型”(LLMs)。同时,收集了包含万亿个单词的大型数据集,以促进这些LLMs的训练。
我们探索了一种改进语言模型的替代路径:通过在包括网页、书籍、新闻和代码在内的文本段落数据库上进行检索来增强transformer。我们将这种方法称为“检索增强的Transformer”(RETRO)。
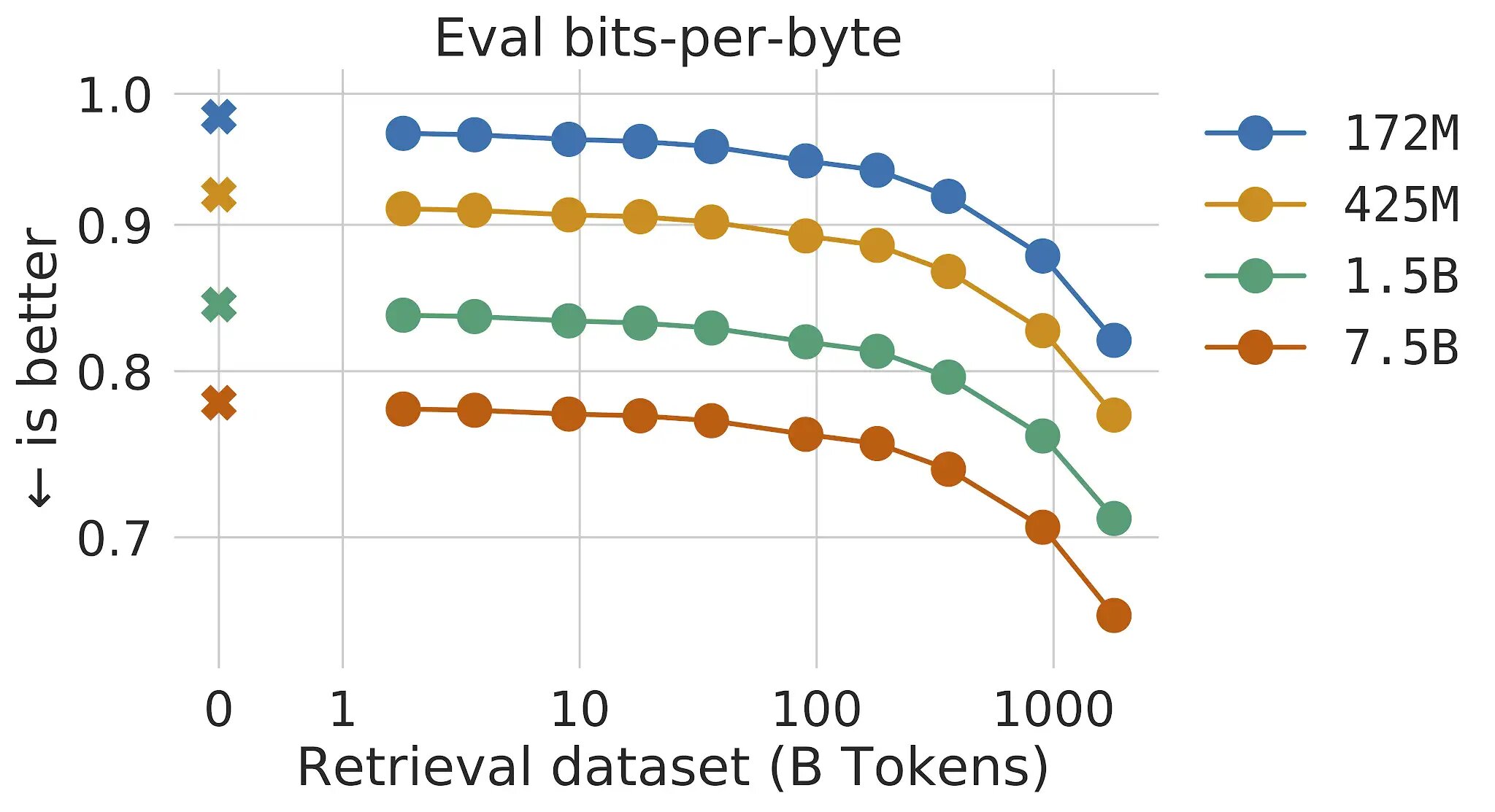
在传统的Transformer语言模型中,模型大小和数据大小的好处是相互关联的:只要数据集足够大,语言建模性能就受到模型大小的限制。然而,通过检索机制,RETRO模型不受训练期间所见数据的限制-它可以访问整个训练数据集。与具有相同参数数量的标准Transformer相比,这导致了显著的性能提升。我们表明,随着检索数据库的规模增加,语言建模持续改善,至少可达到2万亿令牌-相当于连续阅读的175个完整人生。
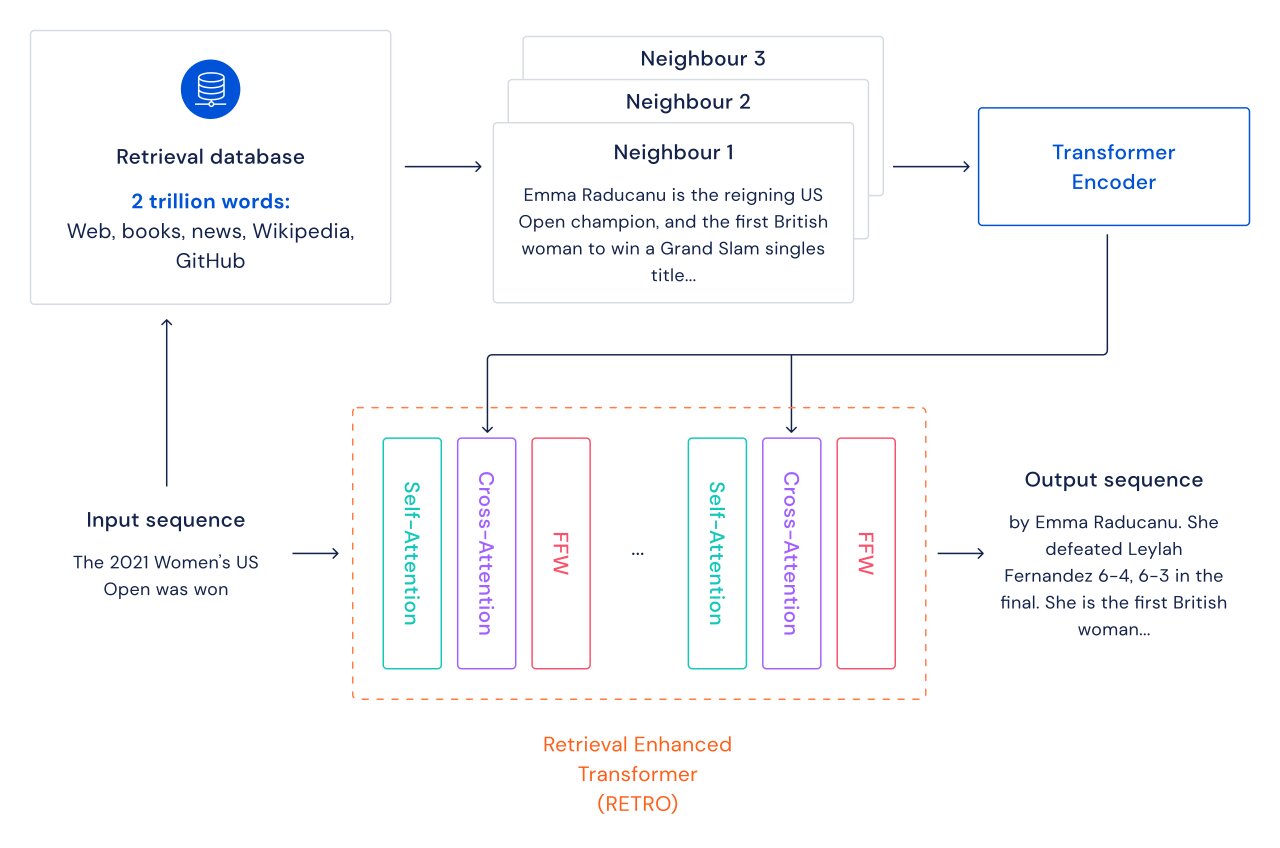
对于每个文本段落(大约是文档的一个段落),执行最近邻搜索,返回在训练数据库中找到的类似序列及其延续。这些序列有助于预测输入文本的延续。RETRO架构在文档级别交错使用常规的自注意力和在更细的段落级别上与已检索的邻居进行交叉注意力。这既提供了更准确也更事实性的延续。此外,RETRO提高了模型预测的可解释性,并提供了通过检索数据库进行直接干预以提高文本延续安全性的途径。在我们对标准语言建模基准数据集Pile的实验中,具有75亿参数的RETRO模型在16个数据集中的10个上优于具有1750亿参数的Jurassic-1,并在16个数据集中的9个上优于具有2800亿参数的Gopher。
下面,我们展示了来自我们的7B基准模型和我们的7.5B RETRO模型的两个样本,突出显示RETRO的样本比基准样本更真实,更关注主题。








